在Ubuntu系统下安装Hadoop集群(阿里云)
修改主机名字
hostnamectl set-hostname master #master为想要更改的主机名
reboot #重启
root@master:/$ sudo vim /etc/hostname
slave1,slave2同样的操作,结果如下:
root@slave1:~$ cat /etc/hostname
slave1
root@slave1:~$ cat /etc/hostname
slave2
创建hadoop用户
在三台机器上创建hadoop用户(以master为例)
hadoop@master:/$ sudo addgroup hadoop
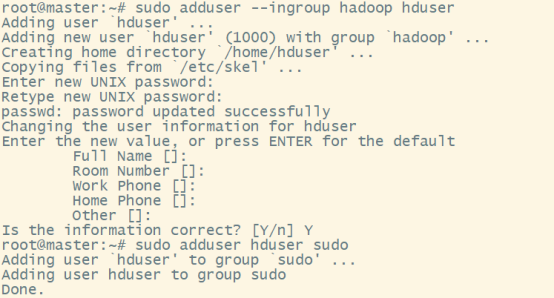
hadoop@master:/$ sudo adduser --ingroup hadoop hadoop
# hadoop 用户增加管理员权限,方便部署
hadoop@master:/$ sudo adduser hadoop sudo
安装JAVA(三台机器都要做)
更新apt
hadoop@master:/$ sudo apt-get update
安装openjdk-8-jdk
hadoop@master:/$ sudo apt install openjdk-8-jdk
查看Java版本
hadoop@master:/$ java -version

配置 JAVA_HOME 环境变量,在 ~/.bashrc 中进行设置
hadoop@master:/$ sudo vim ~/.bashrc
hadoop@master:/$ echo $JAVA_HOME
/usr/lib/jvm/java-8-openjdk-amd64
在文件最下面添加如下单独一行(注意 = 号前后不能有空格)并保存:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64

让该环境变量生效(一定要做)
source ~/.bashrc
这样,Hadoop 所需的 Java 运行环境就安装好了。
修改hosts文件
在三台机器上都配置主机名和IP的映射:主机名和IP地址的映射
hadoop@master:/$ sudo vim /etc/hosts
结果如下:(私网IP)
hadoop@master:~$ cat /etc/hosts
#127.0.0.1 localhost
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
172.28.51.190 master master
172.28.51.192 slave1 slave1
172.28.51.191 slave2 slave2
配置SSH无密码登陆节点
因为Ubuntu中默认没有安装SSH服务,所以我们先要执行三步使其生效(三台都要):
hadoop@master:/$sudo apt-get install openssh-server #安装服务,一路回车
hadoop@master:/$sudo /etc/init.d/ssh restart #启动服务
hadoop@master:/$sudo ufw disable #关闭防火墙
然后在master节点生成SSH公钥,公钥储存在 /home/hadoop/.ssh中
hadoop@master:/$ssh-keygen -t rsa # 一直按回车就可以
让 master 节点可以无密码 SSH 本机,在 master 节点上执行。并赋予权限
hadoop@master:/$cat ./id_rsa.pub >> ./authorized_keys
hadoop@master:/$chmod 0600 ~/.ssh/authorized_keys
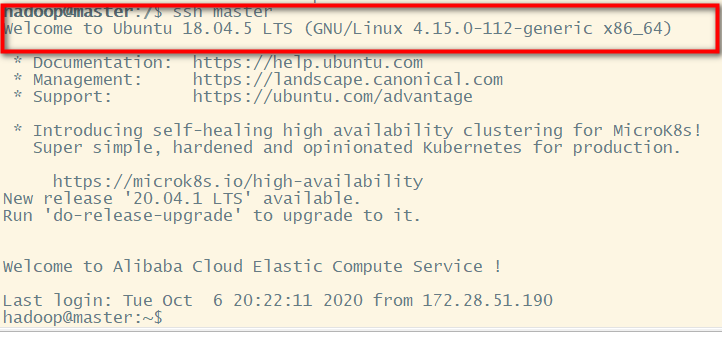
完成后可执行 ssh master 验证一下
hadoop@master:/$ ssh master
接着在 master 节点将上公匙传输到 slave1节点,过程中需要输入 slave1 节点的密码
scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/
接着在 slave1节点上,把公钥加入授权
hadoop@slave1:~$ mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
hadoop@slave1:~$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
对 slave2 重复上面俩步,这样 master 节点就可以无密码登陆俩个 slave 节点了。
可以用来检验是否能成功登陆,exit退出
hadoop@master:~$ ssh slave1
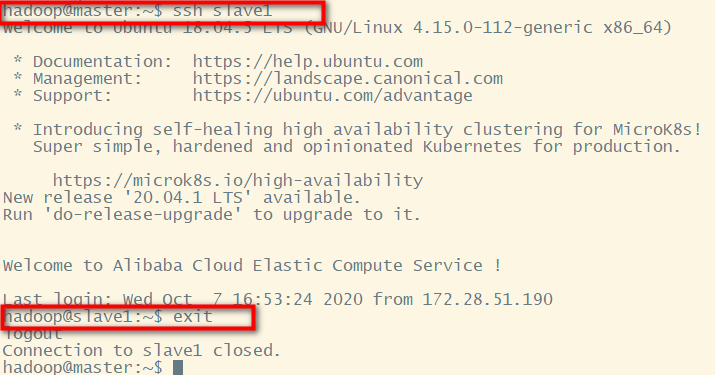
对 slave2 重复上面俩步,这样就验证了 master 节点可以无密码登陆俩个 slave 节点了。
安装Hadoop
下载镜像,在线安装
hadoop@master:~$wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz
#解压缩
hadoop@master:~$tar xvzf hadoop-2.7.7.tar.gz
#创建文件夹 /usr/local/hadoop
hadoop@master:~$ sudo mkdir -p /usr/local/hadoop
#进入到hadoop-2.7.7/目录下
hadoop@master:~$ cd hadoop-2.7.7/
#把hadoop安装到/usr/local/hadoop
#把hadoop-2.7.7/目录下的东西移动到/usr/local/hadoop
hadoop@master:~/hadoop-2.7.7$ sudo mv * /usr/local/hadoop
#把对/usr/local/hadoop的操作权限赋予hadoop用户
hadoop@master:~/hadoop-2.7.7$sudo chown -R hadoop:hadoop /usr/local/hadoop

输入指令查看 Hadoop 是否可用,成功则会显示 Hadoop 版本信息
hadoop@master:~$cd /usr/local/hadoop #到Hadoop文件夹的当前路径
#查看版本
hadoop@master:/usr/local/hadoop$ ./bin/hadoop version

配置 Hadoop 环境变量
hadoop@master:/usr/local/hadoop$ update-alternatives --config java
hadoop@master:/usr/local/hadoop$ sudo vim ~/.bashrc
在文件末尾加入下面环境配置信息,注意保存退出!
#HADOOP VARIABLES START
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=(PATH:)HADOOP_HOME/bin
export PATH=(PATH:)HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#HADOOP VARIABLES END
使设置生效,千万不要忘了这一步
hadoop@master:/usr/local/hadoop$ source ~/.bashrc
配置分布式集群环境
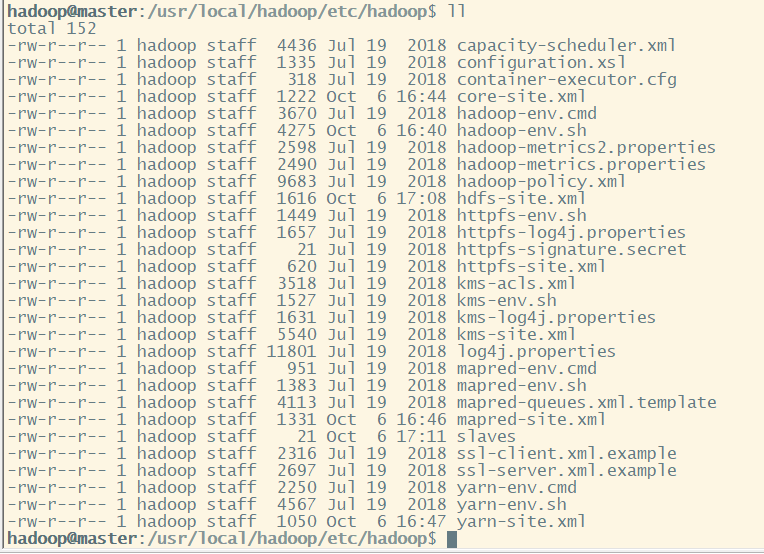
需要修改 /usr/local/hadoop/etc/hadoop 中的6个配置文件。
slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml、hadoop-env.sh
各个配置文件所在目录如下:首先进入到hadoop安装目录
hadoop@master:~$cd /usr/local/hadoop
#各种配置文件都在此目录下
hadoop@master:/usr/local/hadoop$ cd ./etc/hadoop
hadoop@master:/usr/local/hadoop/etc/hadoop$ ll
- slaves
此文件记录的是将要作为 Datanode 节点的名字。将 master,slave1,slave2 主机名字加入进去。
hadoop@master:/usr/local/hadoop/etc/hadoop$ sudo vim ./slaves
hadoop@master:/usr/local/hadoop/etc/hadoop$ cat ./slaves

- core-site.xml
hadoop@master:/usr/local/hadoop/etc/hadoop$ sudo vim ./core-site.xml
//改为如下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
</property>
</configuration>
- hdfs-site.xml
这文件记录备份相关。dfs.replication 一般设为 3,我们有俩个 slave 节点,因此可以将 dfs.replication 的值设为 2
#创建存放namenode数据的文件
hadoop@master:/usr/local/hadoop/etc/hadoop$ sudo mkdir -p /usr/local/hadoop_store/hdfs/namenode
#创建存放datanode数据的文件
hadoop@master:/usr/local/hadoop/etc/hadoop$ sudo mkdir -p /usr/local/hadoop_store/hdfs/datanode
#为hadoop用户赋予操作hadoop_store文件夹的权限
hadoop@master:/usr/local/hadoop/etc/hadoop$ sudo chown -R hadoop:hadoop /usr/local/hadoop_store
#修改hdfs-site.xml配置文件
hadoop@master:/usr/local/hadoop/etc/hadoop$sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop_store/hdfs/datanode</value>
</property>
</configuration>
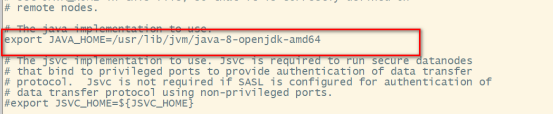
- hadoop-env.sh
hadoop@master:/usr/local/hadoop/etc/hadoop$sudo vim ./hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
-
mapred-site.xml
默认文件名为 mapred-site.xml.template ,此时需要重命名
#重命名
hadoop@master:~$ cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
hadoop@master:~$sudo vim /usr/local/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:54311</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
- yarn-site.xml
hadoop@master:~$sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
配置好以后,将 master 节点上的 /usr/local/hadoop 文件夹复制到剩余节点上。
在 master 节点执行:
hadoop@master:~$cd /usr/local
hadoop@master:~$sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
hadoop@master:~$sudo rm -r ./hadoop/logs/* # 删除日志文件
hadoop@master:~$tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
hadoop@master:~$cd ~ #跳转到有压缩包的路径下
hadoop@master:~$scp ./hadoop.master.tar.gz slave1:/home/hadoop #发送到slave1节点,对其他salve节点也要执行这一步
在剩余 salve 节点上执行(以slave1为例):
hadoop@slave1:~$sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)
hadoop@slave1:~$sudo tar -zxf ~/hadoop.master.tar.gz -C /usr/local
hadoop@slave1:~$sudo chown -R hadoop /usr/local/hadoop
然后在slave2节点上做同样的操作
启动 Hadoop
首次启动 Hadoop 需要将 master 节点格式化:
hadoop@master:~$cd /usr/local/hadoop/sbin
hadoop@master:~$ start-all.sh
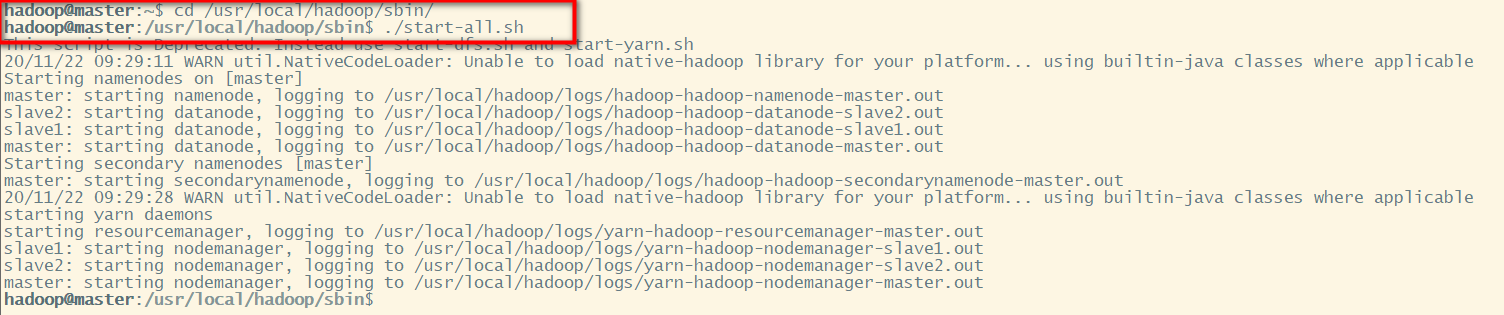
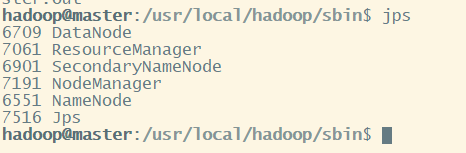
通过命令 jps 可以查看各个节点的启动进程
master 有 NameNode、ResourceManager、SecondaryNameNode、DataNode
hadoop@master:/usr/local/hadoop/sbin$ jps
6709 DataNode
7061 ResourceManager
6901 SecondaryNameNode
7191 NodeManager
6551 NameNode
7516 Jps
slave 有 DataNode、 NodeManager
hadoop@slave1:~$ jps
6663 Jps
6394 DataNode
6527 NodeManager
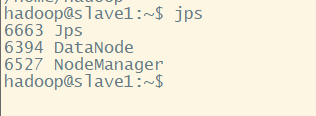
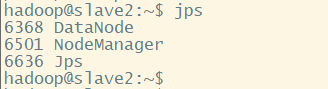
注意:以上进程一个都不能少
WEBUI界面
先在阿里云服务器那边开启相应的端口
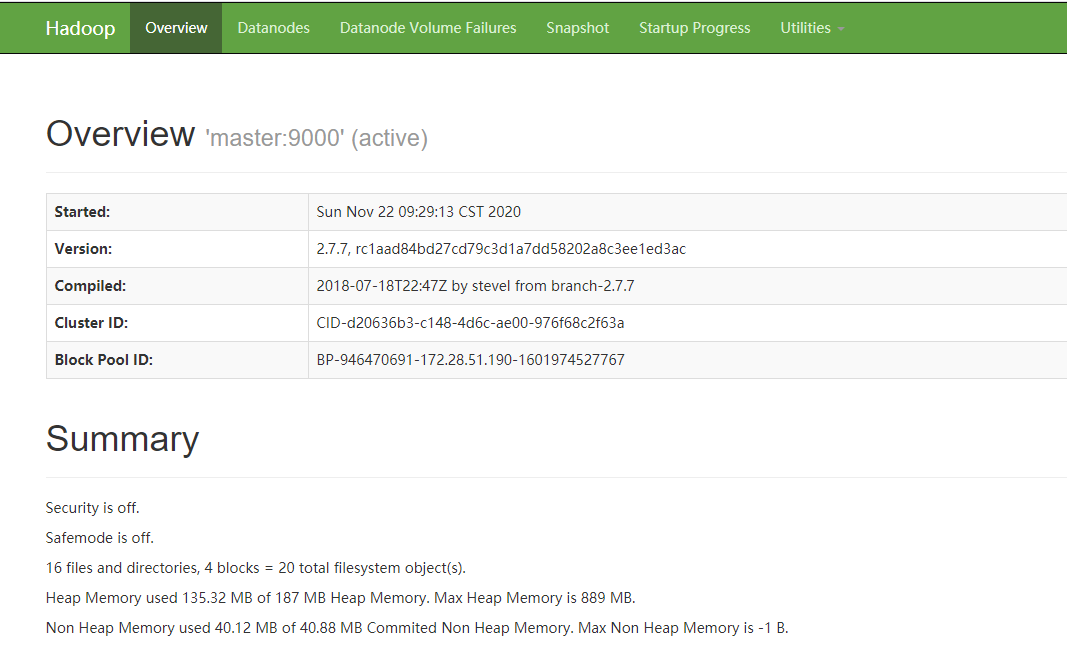
NameNode daemon: http://master:50070/或者 http://8.129.26.6:50070/(阿里云公网IP)
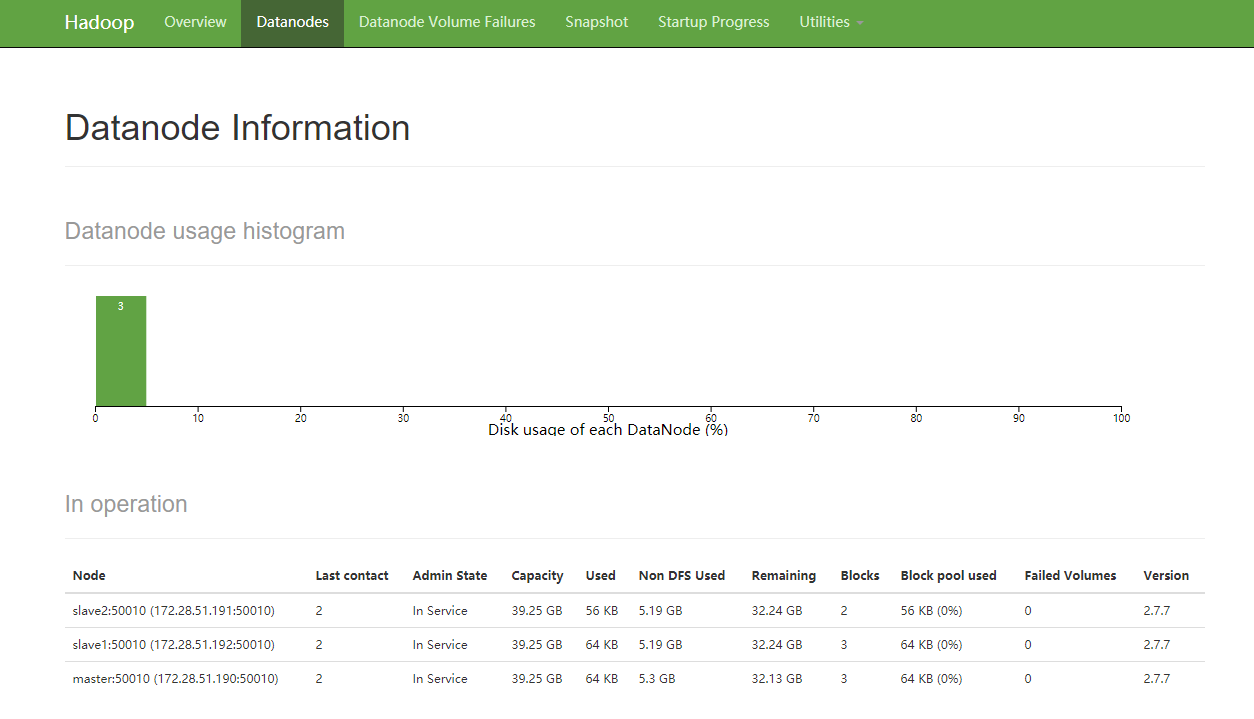
DataNode页面信息:
mapreduce: http://master:8042/

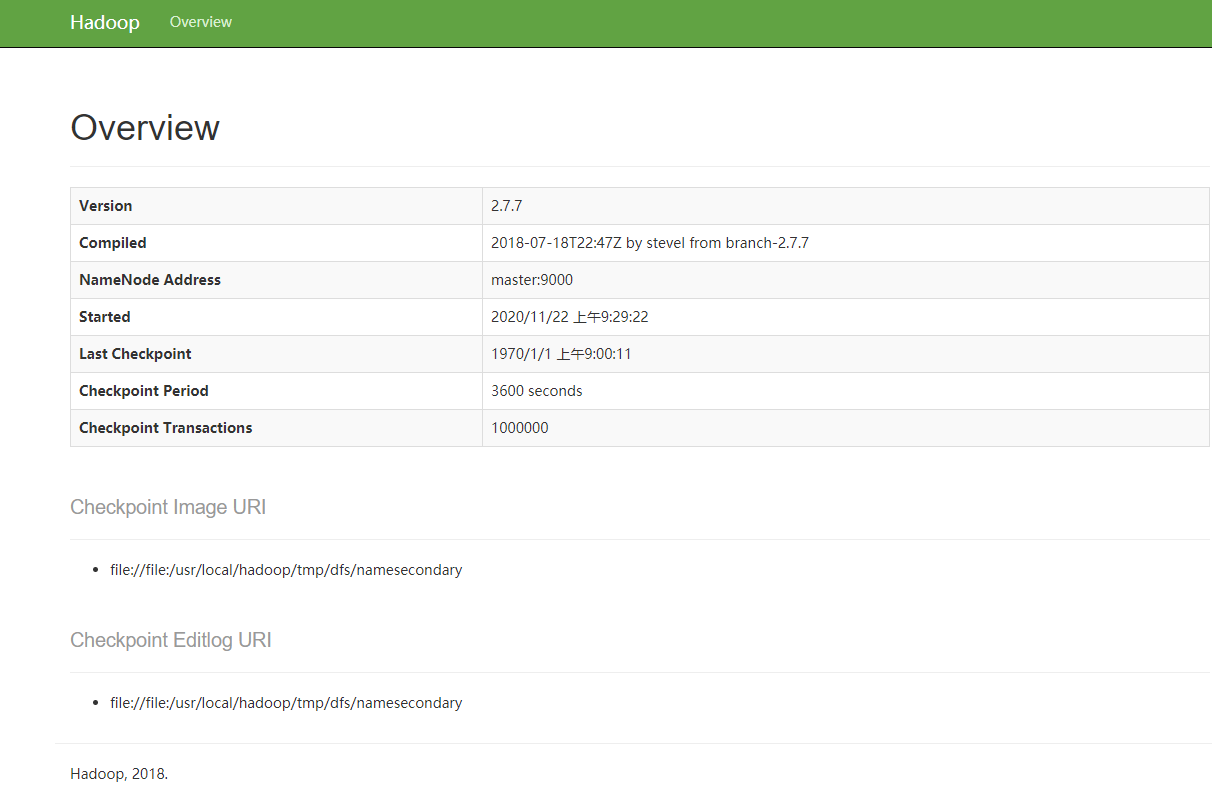
SecondaryNameNode: http://8.129.26.6/50090/status.html
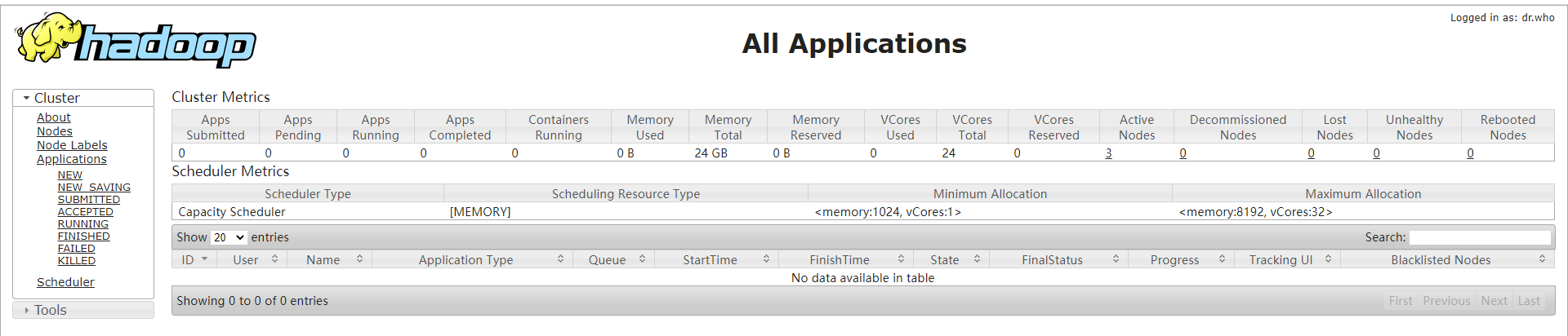
Resource Manager: http://8.129.26.6:8088/
参考链接:
https://www.cnblogs.com/zhangyongli2011/p/10572152.html
https://www.cnblogs.com/guangluwutu/p/9705136.html
https://blog.csdn.net/code__online/article/details/80178032