数据集简介
MNIST手写数字数据集官网:
或者数据集下载网址:http://yann.lecun.com/exdb/mnist/
共有4个数据集,下载之后是4个gz压缩包,把它们保存在磁盘中: train-images-idx3-ubyte.gz: training set images (9912422 bytes) train-labels-idx1-ubyte.gz: training set labels (28881 bytes) t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
解压之后得到的是一个二进制文件。由60000个训练样本集和10000个测试样本集构成,每个样本的尺寸为28x28,以二进制格式存储。标签是0到9的数字,图像则是0到255的像素值。
文件的格式如下:训练集和测试集格式一样,这里以训练集为例:
train-labels-idx1-ubyte
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
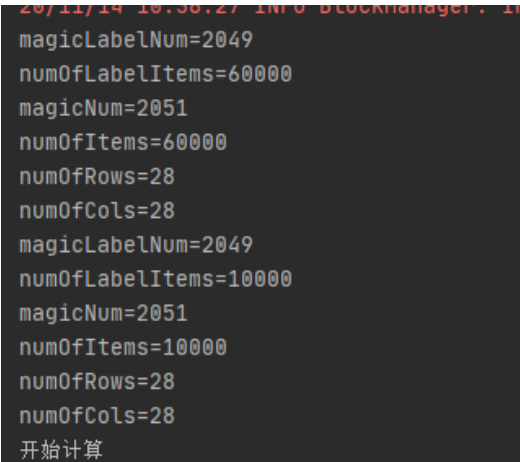
| 0000 | 32 bit integer | 0x00000801(2049) | magic number (MSB first) (文件头魔数) |
| 0004 | 32 bit integer | 60000 | number of items (标签个数) |
| 0008 | unsigned byte | ?? | label (图像标签) |
| 0009 | unsigned byte | ?? | label |
| …….. | unsigned byte | ?? | label |
The labels values are 0 to 9.
train-images-idx3-ubyte
| [offset] | [type] | [value] | [description] |
|---|---|---|---|
| 0000 | 32 bit integer | 0x00000803(2051) | magic number(文件头魔数) |
| 0004 | 32 bit integer | 60000 | number of images(图像个数) |
| 0008 | 32 bit integer | 28 | number of rows(图像宽度) |
| 0012 | 32 bit integer | 28 | number of columns(图像高度) |
| 0016 | unsigned byte | ?? | pixel (图像像素值) |
| 0017 | unsigned byte | ?? | pixel |
| …….. | unsigned byte | ?? | pixel |
这里的行和列,其实就是一张图片的像素矩阵,也就是每个图片都有28×28=784个像素。从第16个字节开始,就是图片的每一个像素点的值了。
SVM模型简介
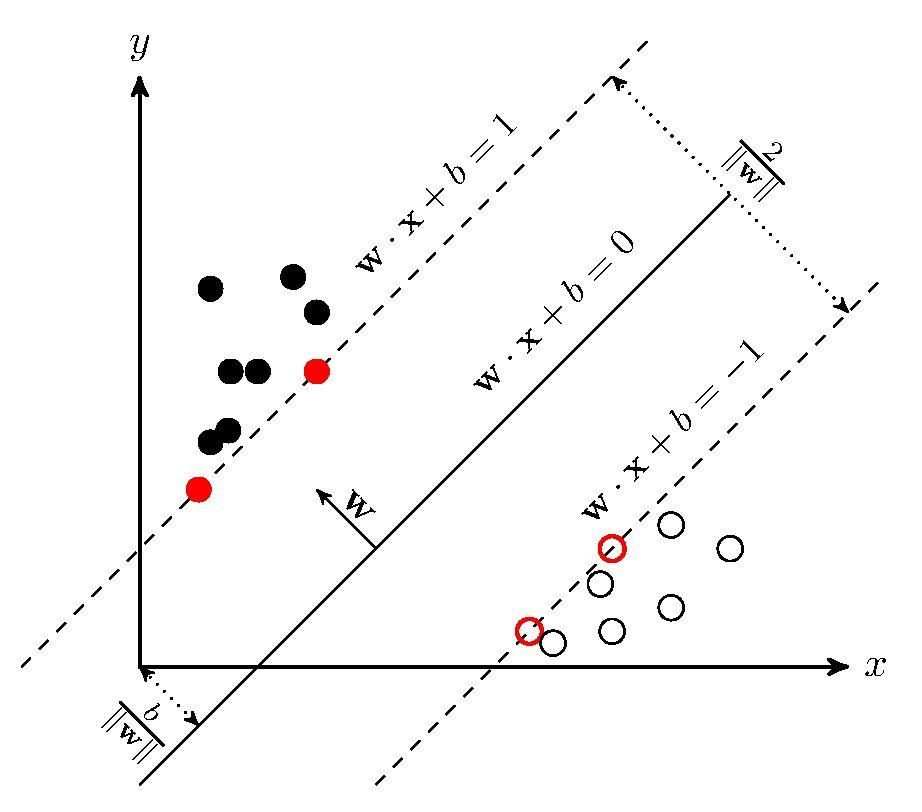
svm通常用于解决监督式机器学习中的二元分类问题,其基本模型定义为特征空间上间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。如图示
Spark MLlib通过SVMWithSGD类和其伴生对象实现了线性SVM二元分类模型,并采用随机梯度下降算法来优化目标函数
数据集处理
数据集读取
spark MLlib的数据格式是 LabeledPoint 标签向量数据格式,所以要先对数据进行读取和处理。
/**
* 安全打开文件流方法
*/
def using[A <: { def close(): Unit }, B](resource: A)(f: A => B): B =
try {
f(resource)
} finally {
resource.close()
}
读取图片信息如下:返回有每一张图片像素数据组成的数组
/**
* 读取图像文件
*
* @param imagesPath
* @return Array[Array[Byte]]
* TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
* [offset] [type] [value] [description]
* 0000 32 bit integer 0x00000803(2051) magic number
* 0004 32 bit integer 60000 number of images
* 0008 32 bit integer 28 number of rows
* 0012 32 bit integer 28 number of columns
* 0016 unsigned byte ?? pixel
* 0017 unsigned byte ?? pixel
* ........
* xxxx unsigned byte ?? pixel
*/
def loadImages(imagesPath: String): Array[Array[Byte]] ={
val file = new File(imagesPath)
val in = new FileInputStream(file)
var trainingDS = new Array[Byte](file.length.toInt)
using(new FileInputStream(file)) { source =>
{
in.read(trainingDS)
}
}
//32 bit integer 0x00000803(2051) magic number
val magicNum = ByteBuffer.wrap(trainingDS.take(4)).getInt
println(s"magicNum=$magicNum")
//32 bit integer 60000 number of items
val numOfItems = ByteBuffer.wrap(trainingDS.slice(4, 8)).getInt
println(s"numOfItems=$numOfItems")
//32 bit integer 28 number of rows
val numOfRows = ByteBuffer.wrap(trainingDS.slice(8, 12)).getInt
println(s"numOfRows=$numOfRows")
//32 bit integer 28 number of columns
val numOfCols = ByteBuffer.wrap(trainingDS.slice(12, 16)).getInt
println(s"numOfCols=$numOfCols")
trainingDS = trainingDS.drop(16)
val itemsBuffer = new ArrayBuffer[Array[Byte]]
for(i <- 0 until numOfItems){
//使用slice方法从规定的索引处提取数组中的元素
itemsBuffer += trainingDS.slice( i * numOfCols * numOfRows , (i+1) * numOfCols * numOfRows)
}
itemsBuffer.toArray
}
读取标签代码如下:
/**
* 读取标签
*
* @param labelPath
* @return Array[Byte]
* TRAINING SET LABEL FILE (train-labels-idx1-ubyte):
* [offset] [type] [value] [description]
* 0000 32 bit integer 0x00000801(2049) magic number (MSB first)
* 0004 32 bit integer 60000 number of items
* 0008 unsigned byte ?? label
* 0009 unsigned byte ?? label
* ........
* xxxx unsigned byte ?? label
* The labels values are 0 to 9.
*/
def loadLabel(labelPath: String): Array[Byte] ={
val file = new File(labelPath)
//根据文件路径获取读文件的对象in
val in = new FileInputStream(file)
var labelDS = new Array[Byte](file.length.toInt)
//定义一个Array[Byte]类型的labelDS,把读取到的文件放进去
using(new FileInputStream(file)) { source =>
{
in.read(labelDS)
}
}
/**
* Wraps a byte array into a buffer.(将字节数组包装到缓冲区中。)
*
* 输入参数:array
* The array that will back this buffer
*
* @return The new byte buffer
*/
//32 bit integer 0x00000801(2049) magic number (MSB first--high endian)
val magicLabelNum = ByteBuffer.wrap(labelDS.take(4)).getInt
println(s"magicLabelNum=$magicLabelNum")
//32 bit integer 60000 number of items
val numOfLabelItems = ByteBuffer.wrap(labelDS.slice(4, 8)).getInt
println(s"numOfLabelItems=$numOfLabelItems")
//删掉前面的文件描述
labelDS = labelDS.drop(8)
labelDS
}
-
添加依赖
<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.4.7</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>2.4.7</version> </dependency>
//处理成mlLib能用的基本类型 LabeledPoint
if(trainLabel.length == trainImages.length) {
/**
* zip函数将传进来的两个参数中相应位置上的元素组成一个pair数组。如果其中一个参数元素比较长,那么多余的参数会被删掉。
* 标签数量和图像数量能对上则合并数组 Array[(label,images)]
* 把像素值由二进制byte类型转换成double类型 使用p & 0xFF
* 只能对0/1进行识别
* data: Array[LabeledPoint]
* LabeledPoint:[label:0/1 features:各个图像的像素值]
*/
val data = trainLabel.zip(trainImages).filter(d => d._1.toInt == 0 || d._1.toInt == 1).map( d =>
LabeledPoint(d._1.toInt, Vectors.dense(d._2.map(p => (p & 0xFF).toDouble))))
//创建data的RDD
//trainRdd: RDD[LabeledPoint]
val trainRdd = sc.makeRDD(data)
3.调用MLlib的api,输入数据进行训练,得到分类模型
/**
* 同样使用zip函数将将test数据集中的testLabel,testImages一一对应组成Array[(labe,images)]
* testData: Array[(Int:0/1, Vector:各个图像的像素值)]
*/
val testData = testLabel.zip(testImages).filter(d => d._1.toInt == 0 || d._1.toInt == 1)
.map(d =>(d._1.toInt,Vectors.dense(d._2.map(p => (p & 0xFF).toDouble )) ))
//testRDD: RDD[Vector] 其中的元素都是各个元素的像素值
val testRDD = sc.makeRDD(testData.map(_._2))
// res:Array[Int] 其中的元素都是使用model模型预测的测试集数据的标签
val res = model.predict(testRDD).map(l => l.toInt).collect()
//res.foreach(println(_))
//把测试的结果label和数据集本身的label组成一个pair数组
val tr = res.zip(testData.map(_._1))
//统计测试结果和数据集本身的label一样的个数
val sum = tr.map( f =>{
if(f._1 == f._2.toInt) 1 else 0
}).sum
println("准确率为:"+ sum.toDouble /tr.length)