++和--操作符对应两条汇编指令:


上图中的表达式,我们的初步分析如下:

完整的示例程序如下:
1 #include <stdio.h> 2 3 int main() 4 { 5 int i = 0; 6 int r = 0; 7 8 r = (i++) + (i++) + (i++); 9 10 printf("i = %d ", i); 11 printf("r = %d ", r); 12 13 r = (++i) + (++i) + (++i); 14 15 printf("i = %d ", i); 16 printf("r = %d ", r); 17 18 return 0; 19 }
vc编译器的额结果如下:
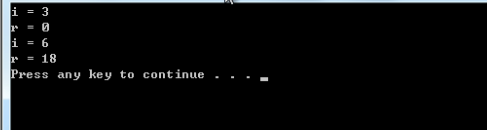
i自增了6次,最终为6。但是两个r的值和我们的分析不一样,这是不是错了呢?
gcc下的运行结果如下:

两种编译器得到了两种不同的结果,这就是C语言里面的灰色地带。
vc中第8行的反汇编结果如下:

首先取出i的值,然后连续累加了两次(相当于i+i+i),将得到的最终的结果存入r。接下来将i变量自增1,连续做了3次。
第13行的程序在vc中的反汇编如下:
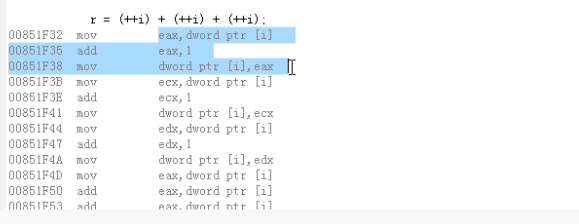
vc编译器将i先自增3次,这时i为6,然后做加法,相当于i+i+i。r最终为18。
gcc中第8行的反汇编如下:

先将变量i的值取出来,然后执行了2次加法(相当于i+i+i),然后将结果放到r中。最后将i自增3次。这种处理和vc是一样的。
第13行在gcc中的反汇编如下:
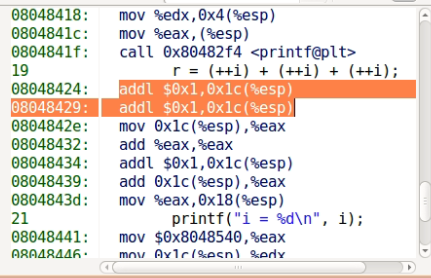
先对i自增了两次,这时i为5,然后执行一次加法(相当于i+i),然后再对i自增1,这时i变成了6,这时再做加法,得到最终结果16。
为什么两个编译器会有不同的结果呢?

++和--分别对应两条汇编指令,这两条指令相对执行次序是一定的,但是它们不一定是相邻的。例如,对于前置++来说,先自增1,在将值取出来使用,在这两条行为之间可能夹杂着其它行为。
上面的例子在java中运行得到的结果和我们第一次分析的是一样的。
在工程中,不要将++和--与其它的运算符进行混合运算。因为编译器的结果可能是不一样的。
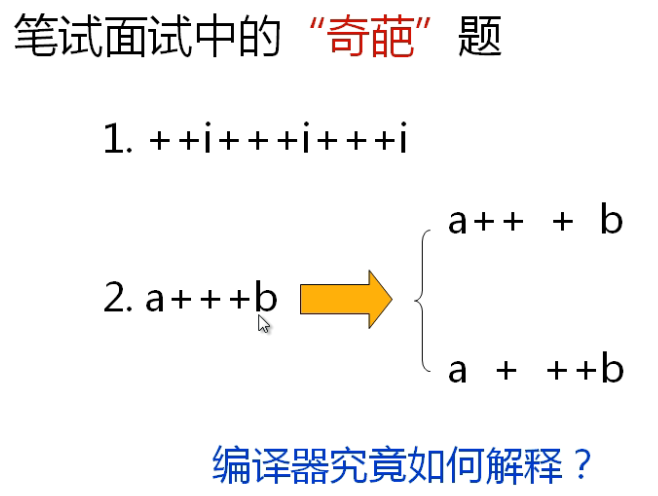
上图中的表达式编译器究竟是怎么样解释的呢?编译器采用了一种叫做贪心法的算法进行编译。

示例程序如下:
1 #include <stdio.h> 2 3 int main() 4 { 5 int i = 0; 6 int j = ++i+++i+++i; 7 8 int a = 1; 9 int b = 4; 10 int c = a+++b; 11 12 int* p = &a; 13 14 b = b/*p; 15 16 printf("i = %d ", i); 17 printf("j = %d ", j); 18 printf("a = %d ", a); 19 printf("b = %d ", b); 20 printf("c = %d ", c); 21 22 return 0; 23 }
第6行的编译过程:
编译器先读入+,一个+没有意义,编译器再次读入一个+,这时两个++,编译器意识到这是前置++,既然是前置++,就需要一个变量,于是再次读入i,这时已经读入了++i,由于采用了贪心法,编译器并不着急计算++i,而是继续读,又读入了一个+,这时为++i+,编译器认为这还要再加上一个值,于是继续读,又读进来一个+,这时已经读入了++i++,编译器认为接着再读入任何字符也不可能称为有意义的符号了。于是,编译器开始处理这个符号,先算++i,得到1,再算1++,常量是不能进行++的,于是编译器报错。
我们在程序中写入一个1++,进行编译,报错信息和第6行的报错信息一样,如下所示:
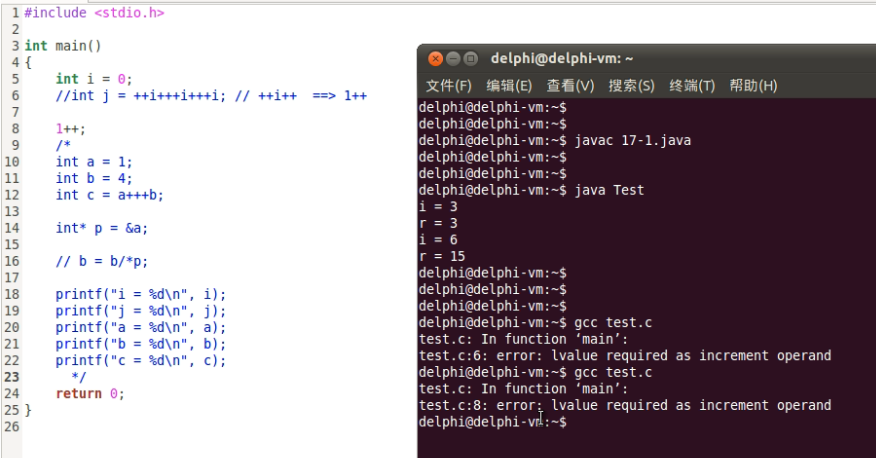
因此,我们的贪心分析是正确的。
第11行的分析思路是一样的,相当于int c = a++ + b;最终得到c为5,a的值变成了2。
第14行的分析同理,当和*紧挨着时,被认为是注释。而不是除号。
当我们加入一些空格后,编译器就不会报错了,如下:

这是为什么呢?原因如下:

小结:
