目的
- 用docker实现所有服务
- 在spark-notebook中编写Scala代码,实时提交到spark集群中运行
- 在HDFS中存储数据文件,spark-notebook中直接读取
组件
- Spark (Standalone模式, 1个master节点 + 可扩展的worker节点)
- Spark-notebook
- Hadoop name node
- Hadoop data node
- HDFS FileBrowser
实现
最初用了Big Data Europe的docker-spark-hadoop-workbench,但是docker 服务运行后在spark-notebook中运行代码会出现经典异常:


java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
发现是因为spark-notebook和spark集群使用的spark版本不一致. 于是fork了Big Data Europe的repo,在此基础上做了一些修改,基于spark2.11-hadoop2.7实现了一个可用的workbench.
运行docker服务
docker-compose up -d
扩展spark worker节点
docker-compose scale spark-worker=3
测试服务
各个服务的URL如下:
Namenode: http://localhost:50070 Datanode: http://localhost:50075 Spark-master: http://localhost:8080 Spark-notebook: http://localhost:9001 Hue (HDFS Filebrowser): http://localhost:8088/home
以下是各个服务的运行截图
HDFS Filebrower

Spark集群

Spark-notebook

运行例子
1. 上传csv文件到HDFS FileBrowser,
2. Spark notebook新建一个notebook
3. 在新建的notebook里操作HDFS的csv文件
具体的步骤参考这里
以下是spark-notebook运行的截图:
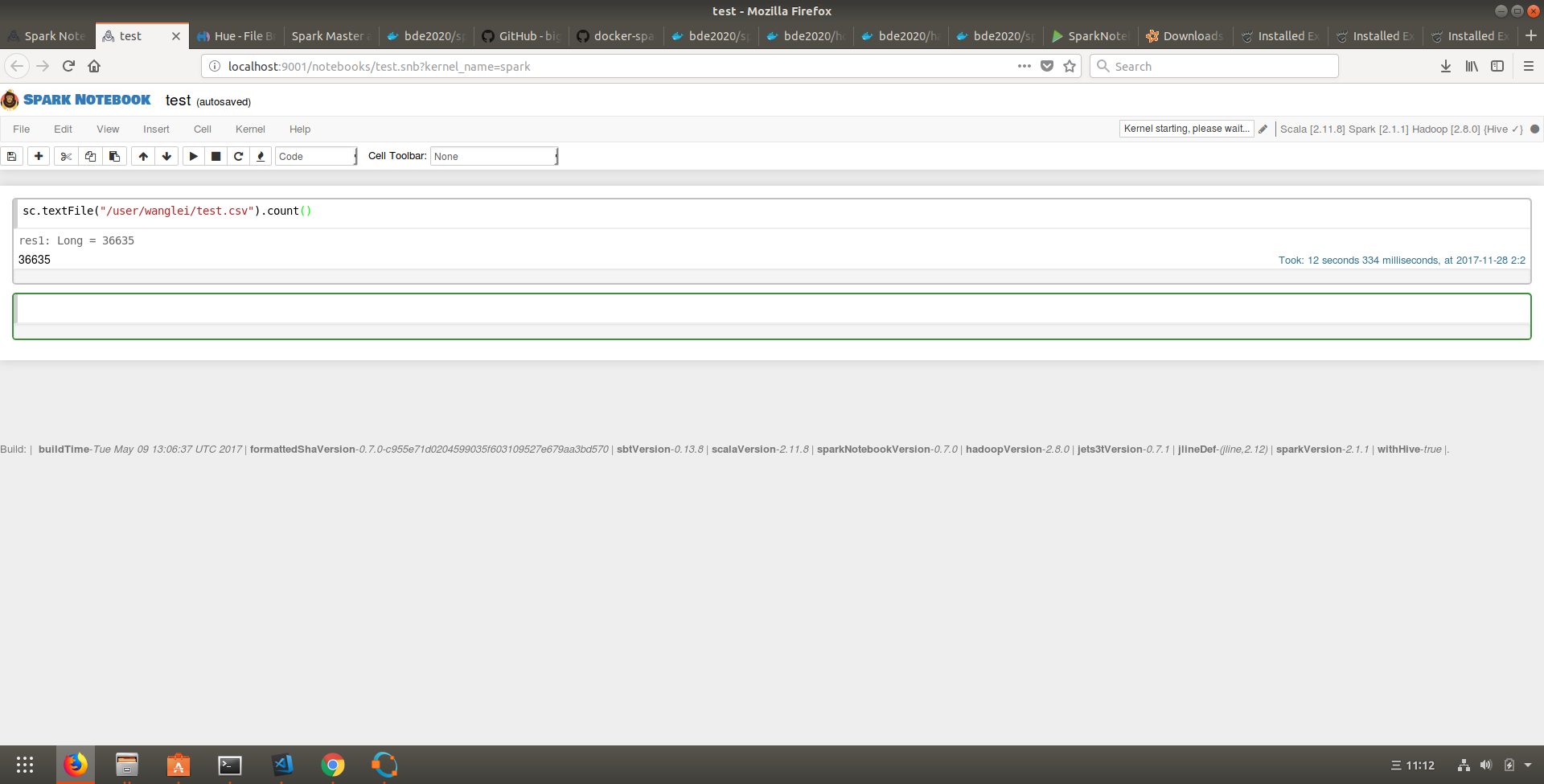
代码链接