问题描述
titanic讲的是在titanic灾难发生时,船上不同人的生还率。给出的训练集是一个csv文件,包含船上乘客的年龄,性别,船票位置,家庭成员关系等,然后最终的结果是二元分析,遇难或者生还,0或1。
分析训练集
开始先有个对数据集大致的印象,然后类似于数据库中的group by,分析一些重要特征对生还率的影响
def analize_data():
print(train_df.columns.values)
print(train_df.head())
print(train_df.tail())
# 描述字段类型和空值情况
print(train_df.info())
print('_' * 40)
print(test_df.info())
# 描述数据集的数学特征
print(train_df.describe())
print(train_df.describe(include=['O']))
# 类似数据库处理,group by,order by
print(train_df[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived',
ascending=False))
print(train_df[["Sex", "Survived"]].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived',
ascending=False))
print(train_df[["SibSp", "Survived"]].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived',
ascending=False))
print(train_df[["Parch", "Survived"]].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived',
ascending=False))
analize_data()

通过图表分析数据
def data_analyze():
# 相关性分析
for x in data1_x:
if data1[x].dtype != 'float64':
print('Survival Correlation by:', x)
print(data1[[x, Target[0]]].groupby(x, as_index=False).mean())
print('-' * 10, '
')
print(pd.crosstab(data1['Title'], data1[Target[0]]))
plt.figure(figsize=[16, 12])
plt.subplot(231)
plt.boxplot(x=data1['Fare'], showmeans=True, meanline=True)
plt.title('Fare Boxplot')
plt.ylabel('Fare ($)')
plt.subplot(232)
plt.boxplot(data1['Age'], showmeans=True, meanline=True)
plt.title('Age Boxplot')
plt.ylabel('Age (Years)')
plt.subplot(233)
plt.boxplot(data1['FamilySize'], showmeans=True, meanline=True)
plt.title('Family Size Boxplot')
plt.ylabel('Family Size (#)')
plt.subplot(234)
plt.hist(x=[data1[data1['Survived'] == 1]['Fare'], data1[data1['Survived'] == 0]['Fare']],
stacked=True, color=['g', 'r'], label=['Survived', 'Dead'])
plt.title('Fare Histogram by Survival')
plt.xlabel('Fare ($)')
plt.ylabel('# of Passengers')
plt.legend()
plt.subplot(235)
plt.hist(x=[data1[data1['Survived'] == 1]['Age'], data1[data1['Survived'] == 0]['Age']],
stacked=True, color=['g', 'r'], label=['Survived', 'Dead'])
plt.title('Age Histogram by Survival')
plt.xlabel('Age (Years)')
plt.ylabel('# of Passengers')
plt.legend()
plt.subplot(236)
plt.hist(x=[data1[data1['Survived'] == 1]['FamilySize'], data1[data1['Survived'] == 0]['FamilySize']],
stacked=True, color=['g', 'r'], label=['Survived', 'Dead'])
plt.title('Family Size Histogram by Survival')
plt.xlabel('Family Size (#)')
plt.ylabel('# of Passengers')
plt.legend()
# 总数
plt.savefig('./output/relate.png')
plt.show()
fig, saxis = plt.subplots(2, 3, figsize=(16, 12))
sns.barplot(x='Embarked', y='Survived', data=data1, ax=saxis[0, 0])
sns.barplot(x='Pclass', y='Survived', order=[1, 2, 3], data=data1, ax=saxis[0, 1])
sns.barplot(x='IsAlone', y='Survived', order=[1, 0], data=data1, ax=saxis[0, 2])
sns.pointplot(x='FareBin', y='Survived', data=data1, ax=saxis[1, 0])
sns.pointplot(x='AgeBin', y='Survived', data=data1, ax=saxis[1, 1])
sns.pointplot(x='FamilySize', y='Survived', data=data1, ax=saxis[1, 2])
# 概率
plt.savefig('./output/probability.png')
plt.show()
fig, (axis1, axis2, axis3) = plt.subplots(1, 3, figsize=(14, 12))
sns.boxplot(x='Pclass', y='Fare', hue='Survived', data=data1, ax=axis1)
axis1.set_title('Pclass vs Fare Survival Comparison')
sns.violinplot(x='Pclass', y='Age', hue='Survived', data=data1, split=True, ax=axis2)
axis2.set_title('Pclass vs Age Survival Comparison')
sns.boxplot(x='Pclass', y='FamilySize', hue='Survived', data=data1, ax=axis3)
axis3.set_title('Pclass vs Family Size Survival Comparison')
# 二元变量分析
plt.savefig('./output/params.png')
plt.show()
a = sns.FacetGrid(data1, hue='Survived', aspect=4)
a.map(sns.kdeplot, 'Age', shade=True)
a.set(xlim=(0, data1['Age'].max()))
a.add_legend()
# 年龄
plt.savefig('./output/age.png')
plt.show()
data_analyze()
举其中年龄的一个例子。直观上的感受,在灾难面前,中年人的生还率一般比老人或者小孩更好。结合图表来看,在30岁左右的人生还率最高,和猜想基本吻合

参数相关性热力图
def correlation_heatmap(df):
_, ax = plt.subplots(figsize=(14, 12))
colormap = sns.diverging_palette(220, 10, as_cmap=True)
_ = sns.heatmap(
df.corr(),
cmap=colormap,
square=True,
cbar_kws={'shrink': .9},
ax=ax,
annot=True,
linewidths=0.1, vmax=1.0, linecolor='white',
annot_kws={'fontsize': 12}
)
plt.title('Pearson Correlation of Features', y=1.05, size=15)
plt.savefig('./output/heatmap.png')
plt.show()
correlation_heatmap(df)
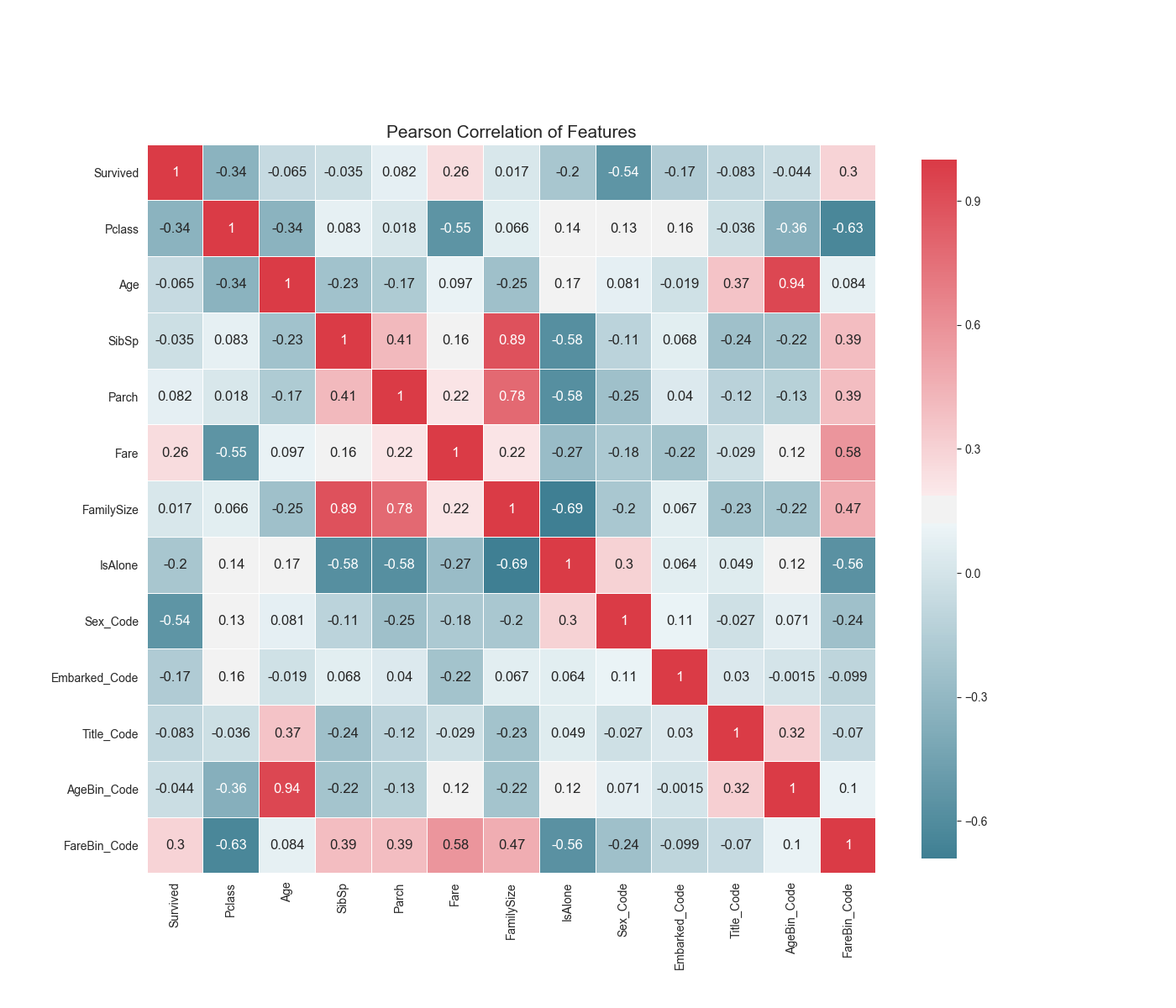 结合热力图,可以看出不同参数对生还率的影响不一样。比如Pclass的仓位类型,可能因为1等,2等,3等仓处在船上的不同位置,离逃生口的距离不一样,这个直接影响到灾难前的逃生。
结合热力图,可以看出不同参数对生还率的影响不一样。比如Pclass的仓位类型,可能因为1等,2等,3等仓处在船上的不同位置,离逃生口的距离不一样,这个直接影响到灾难前的逃生。
建模
def model():
# 逻辑回归
logreg = LogisticRegression()
logreg.fit(X_train, Y_train)
Y_pred = logreg.predict(X_test)
acc_log = round(logreg.score(X_train, Y_train) * 100, 2)
print("Logistic:" + str(acc_log))
coeff_df = pd.DataFrame(train_df.columns.delete(0))
coeff_df.columns = ['Feature']
coeff_df["Correlation"] = pd.Series(logreg.coef_[0])
print(coeff_df.sort_values(by='Correlation', ascending=False))
# svm
svc = SVC()
svc.fit(X_train, Y_train)
Y_pred = svc.predict(X_test)
acc_svc = round(svc.score(X_train, Y_train) * 100, 2)
print("svm:" + str(acc_svc))
# k-NN
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, Y_train)
Y_pred = knn.predict(X_test)
acc_knn = round(knn.score(X_train, Y_train) * 100, 2)
print("k-NN:" + str(acc_knn))
#朴素贝叶斯
gaussian = GaussianNB()
gaussian.fit(X_train, Y_train)
Y_pred = gaussian.predict(X_test)
acc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)
print("Bayes:"+str(acc_gaussian))
#感知器
perceptron = Perceptron()
perceptron.fit(X_train, Y_train)
Y_pred = perceptron.predict(X_test)
acc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)
print("perceptron:"+str(acc_perceptron))
# 线性SVC
linear_svc = LinearSVC()
linear_svc.fit(X_train, Y_train)
Y_pred = linear_svc.predict(X_test)
acc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)
print("SVC:"+str(acc_linear_svc))
# 决策树
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, Y_train)
Y_pred = decision_tree.predict(X_test)
acc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)
print("decision_tree:" + str(acc_decision_tree))
# 随机森林
random_forest = RandomForestClassifier(n_estimators=100)
random_forest.fit(X_train, Y_train)
Y_pred = random_forest.predict(X_test)
random_forest.score(X_train, Y_train)
acc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)
print("random_forest:" + str(acc_random_forest))
submission = pd.DataFrame({
"PassengerId": test_df["PassengerId"],
"Survived": Y_pred
})
submission.to_csv('./output/submission.csv', index=False)
model()
输出关键日志
svm:84.4
k-NN:85.52
Bayes:74.97
perceptron:80.36
SVC:81.14
decision_tree:89.11
random_forest:89.11
这里建模的过程,是调用knn,svc,随机森林等不同的模型,对数据建模,并比较准确率。最后发现决策树和随机森林的准确率最高,是89.11%。于是最后用随机森林对测试集进行预测。
kaggle上传预测集
