问题描述
speech recognize是kaggle上1,2年前的一个赛题,主要描述的是如果在各种环境中识别出简单的英文单词发音,比如bed,cat,right之类的语音。提供的训练集是.wav格式的语音,解压后数据集大小在2G左右。
训练集分析
语音识别相对图片识别来说,是一个区别较大的领域。所以首先要了解训练集的基本特征,理清不同语音之间的共性。
振幅和频率
def log_specgram(audio, sample_rate, window_size=20,
step_size=10, eps=1e-10):
nperseg = int(round(window_size * sample_rate / 1e3))
noverlap = int(round(step_size * sample_rate / 1e3))
freqs, times, spec = signal.spectrogram(audio,
fs=sample_rate,
window='hann',
nperseg=nperseg,
noverlap=noverlap,
detrend=False)
return freqs, times, np.log(spec.T.astype(np.float32) + eps)
def plt_specgram(freqs, times, spectrogram):
fig = plt.figure(figsize=(14, 8))
ax1 = fig.add_subplot(211)
ax1.set_title('Raw wave of ' + filename)
ax1.set_ylabel('Amplitude')
ax1.plot(np.linspace(0, sample_rate / len(samples), sample_rate), samples)
ax2 = fig.add_subplot(212)
ax2.imshow(spectrogram.T, aspect='auto', origin='lower',
extent=[times.min(), times.max(), freqs.min(), freqs.max()])
ax2.set_yticks(freqs[::16])
ax2.set_xticks(times[::16])
ax2.set_title('Spectrogram of ' + filename)
ax2.set_ylabel('Freqs in Hz')
ax2.set_xlabel('Seconds')
plt.savefig('./output/yes_0a7c2a8d_nohash_0.png')
plt.show()
train_audio_path = './input/train/audio/'
filename = '/yes/0a7c2a8d_nohash_0.wav'
sample_rate, samples = wavfile.read(str(train_audio_path) + filename)
# print(sample_rate, samples)
# 频谱图
freqs, times, spectrogram = log_specgram(samples, sample_rate)
plt_specgram(freqs, times, spectrogram)
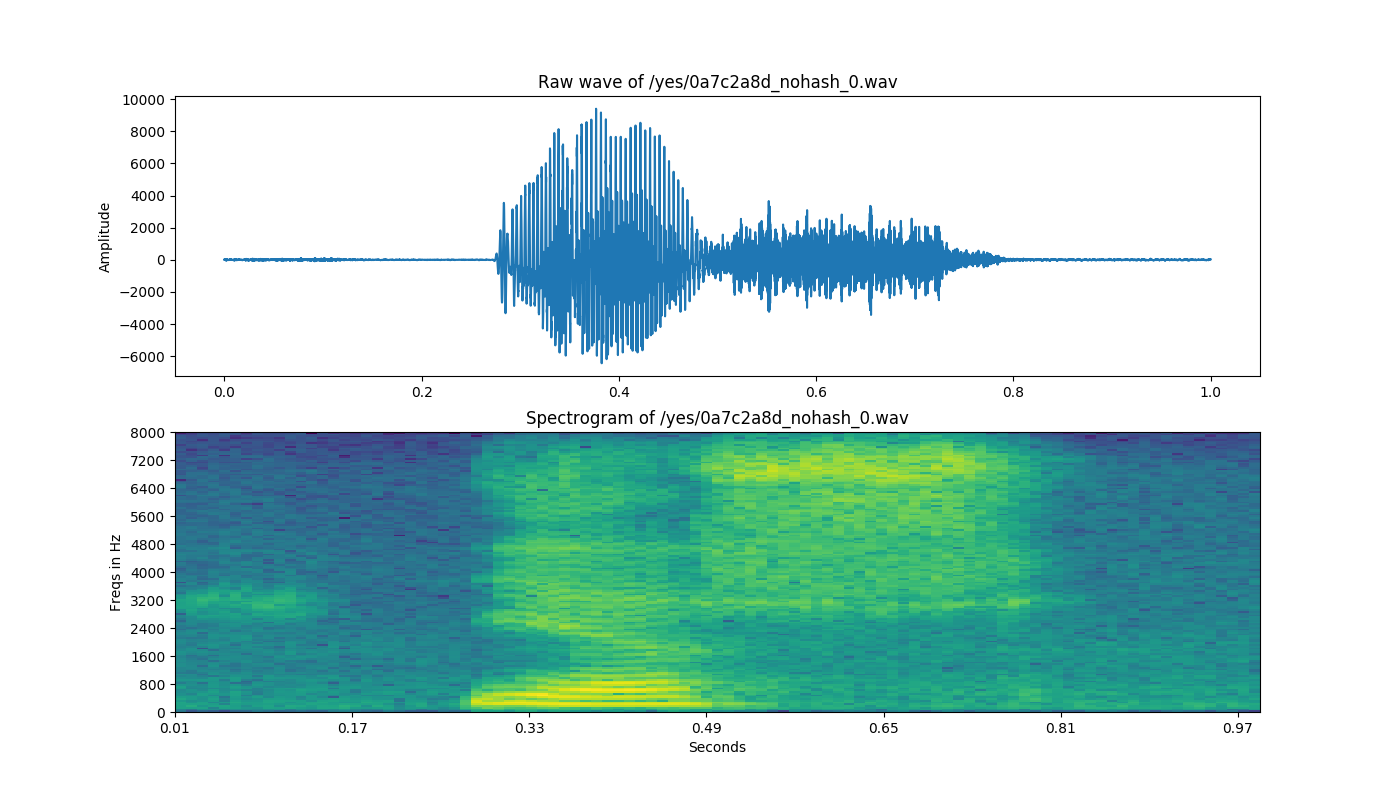
声音强度
def plt_spectrogram():
plt.figure(figsize=(12, 4))
librosa.display.specshow(log_S, sr=sample_rate, x_axis='time', y_axis='mel')
plt.title('Mel power spectrogram ')
plt.colorbar(format='%+02.0f dB')
plt.tight_layout()
plt.savefig('./output/spectrogram.png')
plt.show()
# 光谱图
sig = samples
sig = sig / max(abs(sig))
S = librosa.feature.melspectrogram(y=sig, sr=sample_rate, n_mels=128)
log_S = librosa.power_to_db(S, ref=np.max)
plt_spectrogram()
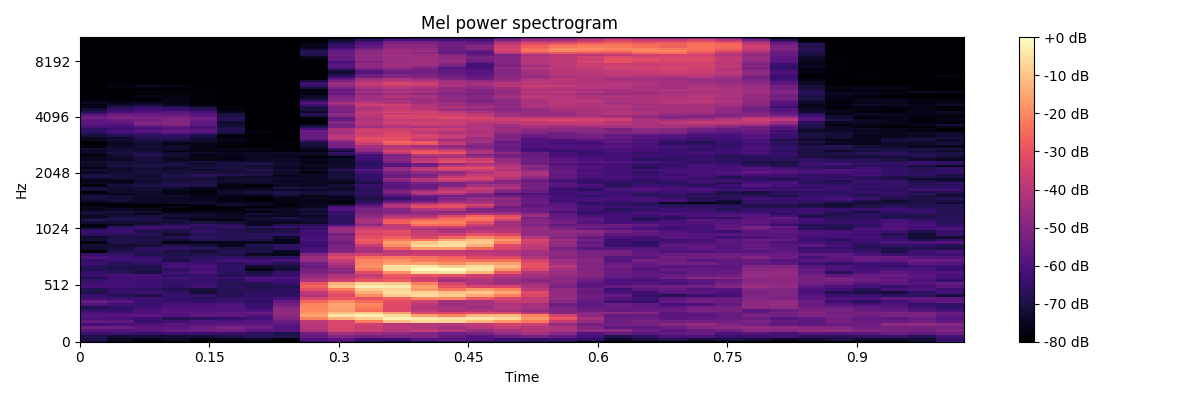
三维图像
def spectrogram_3d():
data = [go.Surface(z=spectrogram.T)]
layout = go.Layout(
title='Specgtrogram of "yes" in 3d',
scene=dict(
yaxis=dict(title='Frequencies'),
xaxis=dict(title='Time'),
zaxis=dict(title='Log amplitude'),
),
)
fig = go.Figure(data=data, layout=layout)
py.plot(fig)
spectrogram_3d()
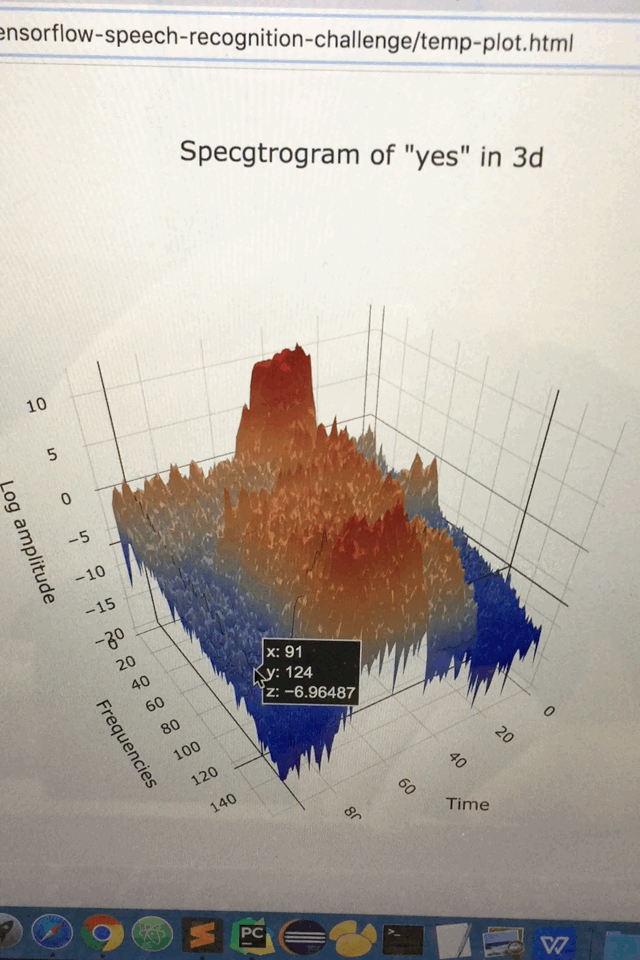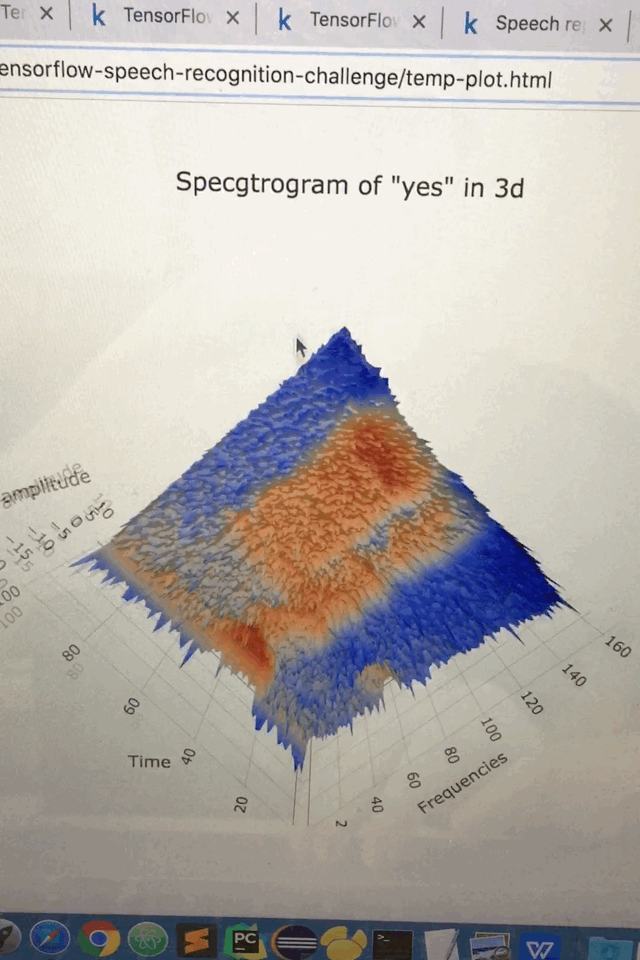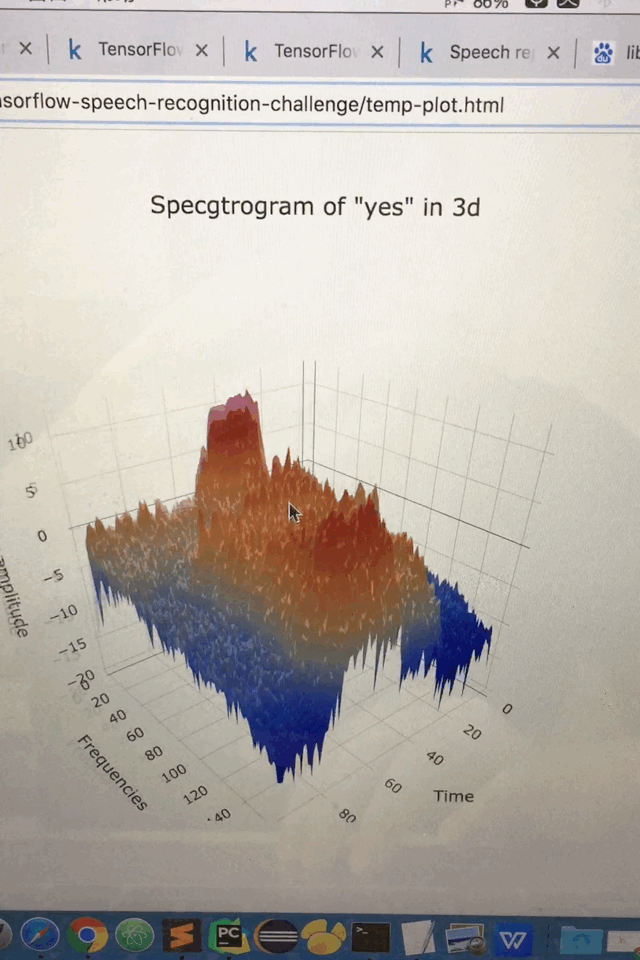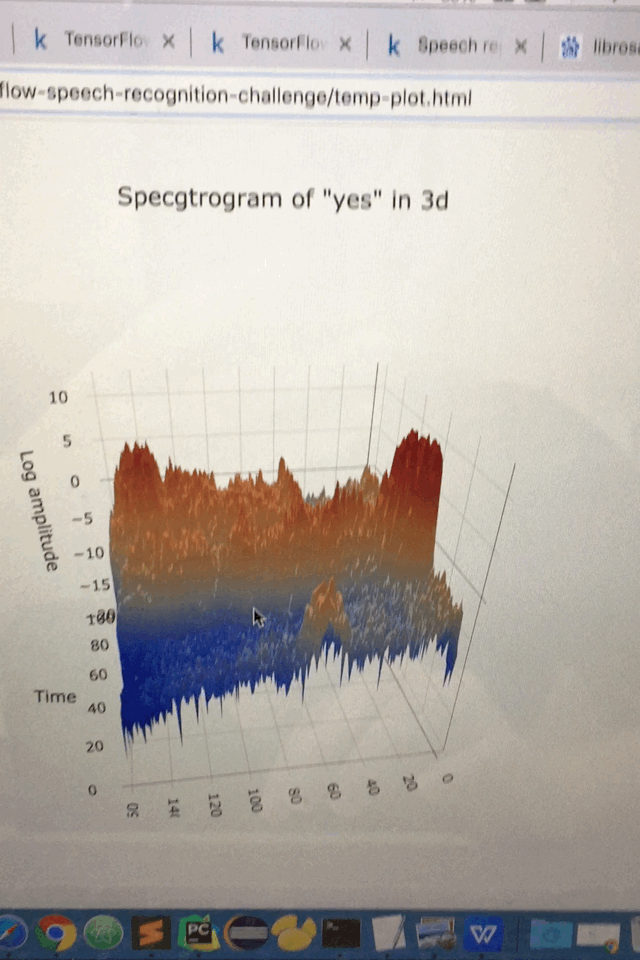
不同音频的总数统计
def count_summary():
dirs.sort()
print('Number of labels: ' + str(len(dirs)))
number_of_recordings = []
for direct in dirs:
waves = [f for f in os.listdir(join(train_audio_path, direct)) if f.endswith('.wav')]
number_of_recordings.append(len(waves))
speech_count = dict(map(lambda x, y: [x, y], dirs, number_of_recordings))
print(speech_count)
count_summary()
"""输出
{'_background_noise_': 6, 'bed': 1713, 'bird': 1731, 'cat': 1733, 'dog': 1746, 'down': 2359, 'eight': 2352, 'five': 2357, 'four': 2372, 'go': 2372, 'happy': 1742, 'house': 1750, 'left': 2353, 'marvin': 1746, 'nine': 2364, 'no': 2375, 'off': 2357, 'on': 2367, 'one': 2370, 'right': 2367, 'seven': 2377, 'sheila': 1734, 'six': 2369, 'stop': 2380, 'three': 2356, 'tree': 1733, 'two': 2373, 'up': 2375, 'wow': 1745, 'yes': 2377, 'zero': 2376}
"""
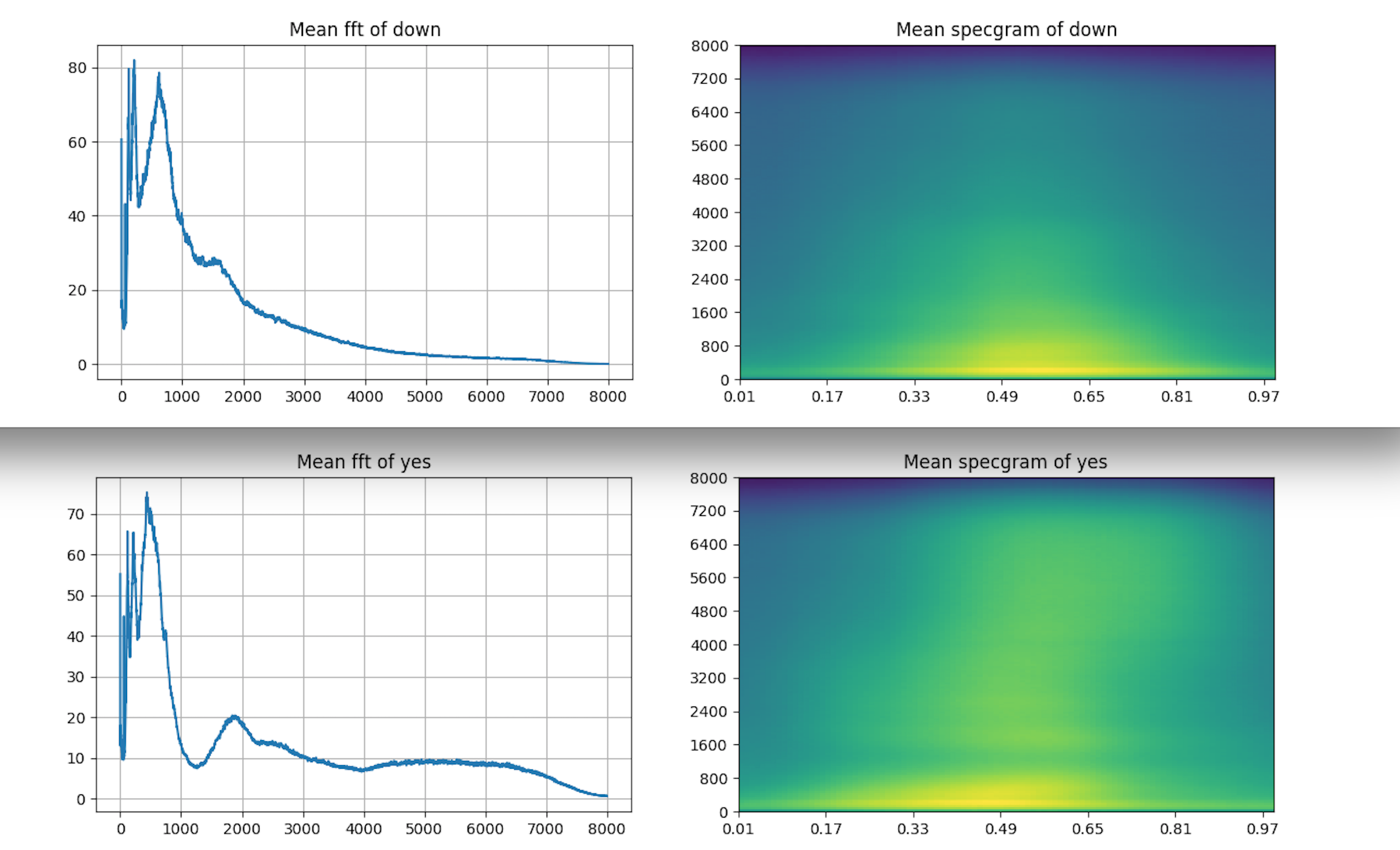
每个英文发音的特征识别
def mean_fft():
to_keep = 'yes no up down left right on off stop go'.split()
dir = [d for d in dirs if d in to_keep]
print(dir)
for direct in dir:
vals_all = []
spec_all = []
waves = [f for f in os.listdir(join(train_audio_path, direct)) if f.endswith('.wav')]
for wav in waves:
sample_rate, samples = wavfile.read(train_audio_path + direct + '/' + wav)
if samples.shape[0] != 16000:
continue
xf, vals = custom_fft(samples, 16000)
vals_all.append(vals)
freqs, times, spec = log_specgram(samples, 16000)
spec_all.append(spec)
plt.figure(figsize=(14, 4))
plt.subplot(121)
plt.title('Mean fft of ' + direct)
plt.plot(np.mean(np.array(vals_all), axis=0))
plt.grid()
plt.subplot(122)
plt.title('Mean specgram of ' + direct)
plt.imshow(np.mean(np.array(spec_all), axis=0).T, aspect='auto', origin='lower',
extent=[times.min(), times.max(), freqs.min(), freqs.max()])
plt.yticks(freqs[::16])
plt.xticks(times[::16])
plt.savefig('./output/mean_fft_' + direct + '.png')
plt.show()
mean_fft()
代码是把所有英文单词的特征图都输出,这里只展示down和yes,2个特征图
原始数据处理
for label, fname in zip(labels, fnames):
sample_rate, samples = wavfile.read(os.path.join(train_data_path, label, fname))
samples = pad_audio(samples)
if len(samples) > 16000:
n_samples = chop_audio(samples)
else:
n_samples = [samples]
for samples in n_samples:
resampled = signal.resample(samples, int(new_sample_rate / sample_rate * samples.shape[0]))
_, _, specgram = log_specgram(resampled, sample_rate=new_sample_rate)
y_train.append(label)
x_train.append(specgram)
x_train = np.array(x_train)
x_train = x_train.reshape(tuple(list(x_train.shape) + [1]))
y_train = label_transform(y_train)
label_index = y_train.columns.values
y_train = y_train.values
y_train = np.array(y_train)
del labels, fnames
gc.collect()
cnn建模
def model_cnn(x_train, y_train):
input_shape = (99, 81, 1)
nclass = 12
inp = Input(shape=input_shape)
norm_inp = BatchNormalization()(inp)
img_1 = Convolution2D(8, kernel_size=2, activation=activations.relu)(norm_inp)
img_1 = Convolution2D(8, kernel_size=2, activation=activations.relu)(img_1)
img_1 = MaxPooling2D(pool_size=(2, 2))(img_1)
img_1 = Dropout(rate=0.2)(img_1)
img_1 = Convolution2D(16, kernel_size=3, activation=activations.relu)(img_1)
img_1 = Convolution2D(16, kernel_size=3, activation=activations.relu)(img_1)
img_1 = MaxPooling2D(pool_size=(2, 2))(img_1)
img_1 = Dropout(rate=0.2)(img_1)
img_1 = Convolution2D(32, kernel_size=3, activation=activations.relu)(img_1)
img_1 = MaxPooling2D(pool_size=(2, 2))(img_1)
img_1 = Dropout(rate=0.2)(img_1)
img_1 = Flatten()(img_1)
dense_1 = BatchNormalization()(Dense(128, activation=activations.relu)(img_1))
dense_1 = BatchNormalization()(Dense(128, activation=activations.relu)(dense_1))
dense_1 = Dense(nclass, activation=activations.softmax)(dense_1)
model = models.Model(inputs=inp, outputs=dense_1)
opt = optimizers.Adam()
model.compile(optimizer=opt, loss=losses.binary_crossentropy)
model.summary()
x_train, x_valid, y_train, y_valid = train_test_split(x_train, y_train, test_size=0.1, random_state=2017)
model.fit(x_train, y_train, batch_size=16, validation_data=(x_valid, y_valid), epochs=3, shuffle=True, verbose=2)
model.save(os.path.join(model_path, 'cnn.model'))
return model
model = model_cnn(x_train, y_train)
"""输出
Using TensorFlow backend.
2019-06-15 20:59:45.453845 task begin
./input/train/audio
2019-06-15 20:59:46.634215 xy begin
/Users/user/Library/Python/3.6/lib/python/site-packages/scipy/io/wavfile.py:273: WavFileWarning: Chunk (non-data) not understood, skipping it.
WavFileWarning)
2019-06-15 21:02:35.116550 reshape begin
2019-06-15 21:02:46.166546 model begin
WARNING:tensorflow:From /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
2019-06-15 21:02:46.278603: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 99, 81, 1) 0
_________________________________________________________________
batch_normalization_1 (Batch (None, 99, 81, 1) 4
_________________________________________________________________
conv2d_1 (Conv2D) (None, 98, 80, 8) 40
_________________________________________________________________
conv2d_2 (Conv2D) (None, 97, 79, 8) 264
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 48, 39, 8) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 48, 39, 8) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 46, 37, 16) 1168
_________________________________________________________________
conv2d_4 (Conv2D) (None, 44, 35, 16) 2320
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 22, 17, 16) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 22, 17, 16) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 20, 15, 32) 4640
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 10, 7, 32) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 10, 7, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2240) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 286848
_________________________________________________________________
batch_normalization_2 (Batch (None, 128) 512
_________________________________________________________________
dense_2 (Dense) (None, 128) 16512
_________________________________________________________________
batch_normalization_3 (Batch (None, 128) 512
_________________________________________________________________
dense_3 (Dense) (None, 12) 1548
=================================================================
Total params: 314,368
Trainable params: 313,854
Non-trainable params: 514
_________________________________________________________________
Instructions for updating:
Use tf.cast instead.
Train on 58356 samples, validate on 6485 samples
Epoch 1/3
- 737s - loss: 0.1415 - val_loss: 0.0874
Epoch 2/3
- 608s - loss: 0.0807 - val_loss: 0.0577
Epoch 3/3
- 518s - loss: 0.0636 - val_loss: 0.0499
2019-06-15 21:33:58.518621 predict begin
"""
预测
del x_train, y_train
gc.collect()
index = []
results = []
for fnames, imgs in test_data_generator(batch=32):
predicts = model.predict(imgs)
predicts = np.argmax(predicts, axis=1)
predicts = [label_index[p] for p in predicts]
index.extend(fnames)
results.extend(predicts)
df = pd.DataFrame(columns=['fname', 'label'])
df['fname'] = index
df['label'] = results
df.to_csv(os.path.join(out_path, 'sub.csv'), index=False)
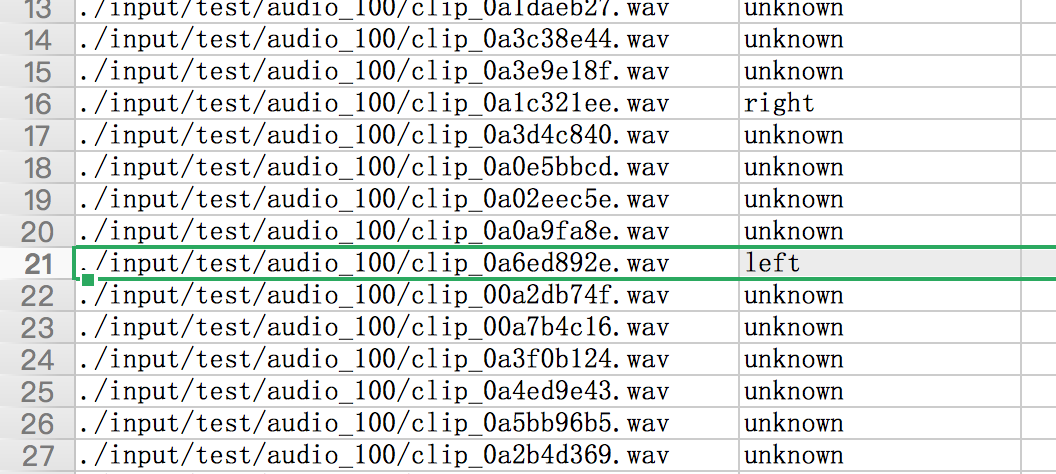 关于预测的数据集,kaggle提供的压缩包有2,3G,解压后有将近10w条音频,个人笔记本吃不消。于是只选取其中的100条来测试,根据预测出的结果,和自己听取wav音频的结果对比,是正确的。但是并没有在大规模的数据集上预测,所以准确率不可知。后续在GPU上训练时,再考虑预测所有的数据。
关于预测的数据集,kaggle提供的压缩包有2,3G,解压后有将近10w条音频,个人笔记本吃不消。于是只选取其中的100条来测试,根据预测出的结果,和自己听取wav音频的结果对比,是正确的。但是并没有在大规模的数据集上预测,所以准确率不可知。后续在GPU上训练时,再考虑预测所有的数据。