RDD弹性分布式数据集 (Resilient Distributed Dataset)
RDD只读可分区,数据集可以缓存在内存中,在多次计算间重复利用。
弹性是指内存不够时可以与磁盘进行交互
join操作就是笛卡尔积的操作过程
spark streaming
实时数据流
Discretized Streams (DStreams) 离散流
Graphx
图计算
spark sql
使用SchemaRDD来操作SQL
MLBase机器学习
MLlib算法库
Tachyon
高容错分布式文件系统
scala环境
tar -xvf scala-2.11.8.tgz
mv scala-2.11.8/ scala
#配置环境变量
export SCALA_HOME=/usr/local/scala
export PATH=$SCALA_HOME/bin:$PATH
[root@sjck-node01 ~]# scala -version
Scala code runner version 2.11.8 -- Copyright 2002-2016, LAMP/EPFL
spark环境
tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
mv scala-2.11.8/ scala
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
spark配置
cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/usr/local/src/jdk/jdk1.8
export SCALA_HOME=/usr/local/scala
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SPARK_MASTER_IP=sjck-node01
export SPARK_MASTER_HOST=sjck-node01
export SPARK_LOCAL_IP=sjck-node01
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_CORES=2
export SPARK_HOME=/usr/local/spark-2.4.0-bin-hadoop2.7
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
slaves配置
cp slaves.template slaves
sjck-node02
sjck-node03
copy到slave节点,配置对应的环境变量
scp -r /usr/local/scala/ sjck-node02:/usr/local/
scp -r /usr/local/spark-2.4.0-bin-hadoop2.7/ sjck-node02:/usr/local/
vim spark-env.sh
把SPARK_LOCAL_IP改成对应的ip
启动顺序,先启动hadoop,再启动spark
/usr/local/hadoop/sbin/start-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
/usr/local/hadoop/sbin/stop-all.sh
/usr/local/spark-2.4.0-bin-hadoop2.7/sbin/stop-all.sh
[root@sjck-node01 ~]# /usr/local/spark-2.4.0-bin-hadoop2.7/sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.master.Master-1-sjck-node01.out
sjck-node02: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node02.out
sjck-node03: starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark-2.4.0-bin-hadoop2.7/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-sjck-node03.out
查看集群jps状态
[root@sjck-node01 ~]# jps
5233 Master
4595 NameNode
4788 SecondaryNameNode
5305 Jps
4942 ResourceManager
[root@sjck-node02 conf]# jps
3808 Worker
3538 DataNode
3853 Jps
3645 NodeManager
[root@sjck-node03 conf]# jps
3962 NodeManager
3851 DataNode
4173 Jps
4126 Worker
查看集群状态
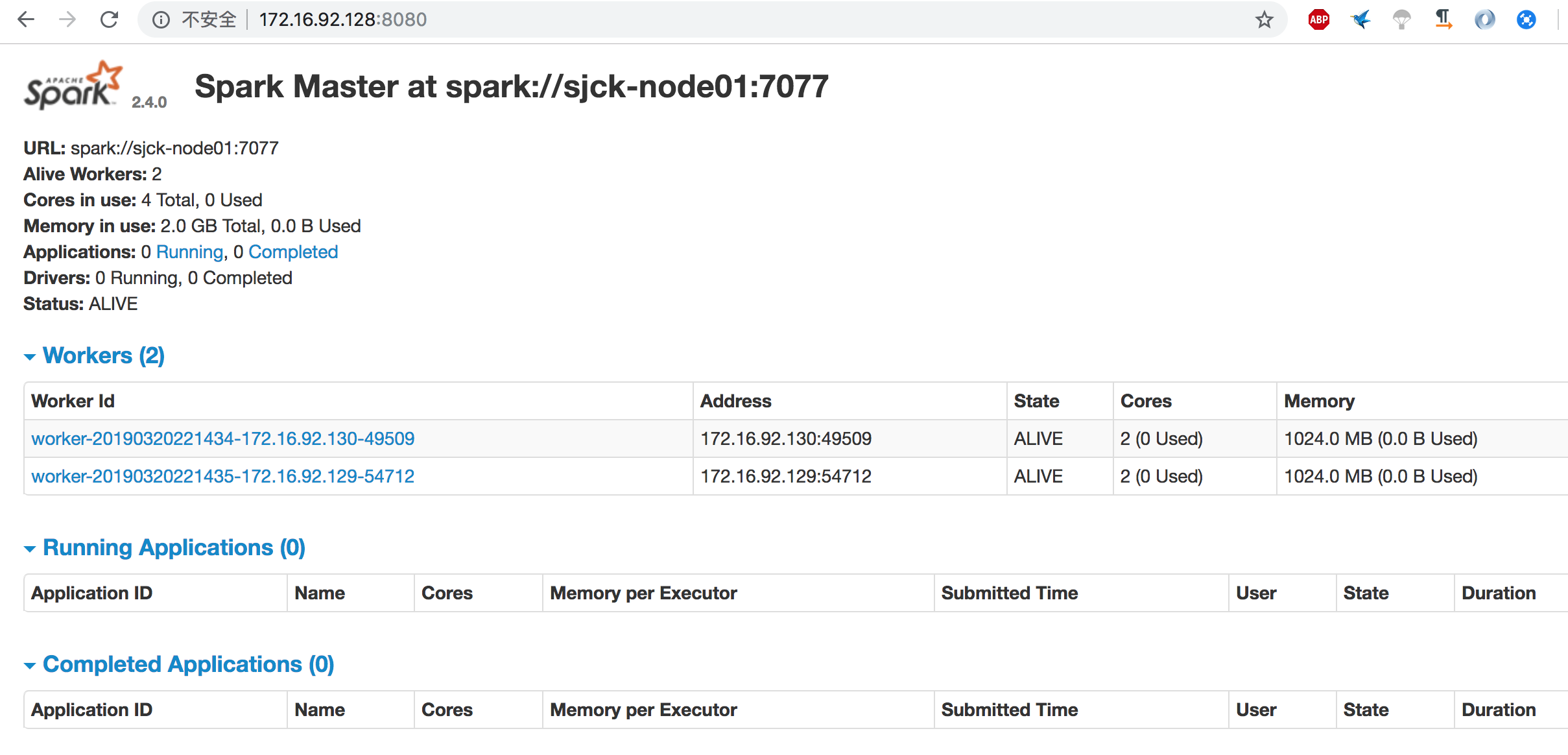
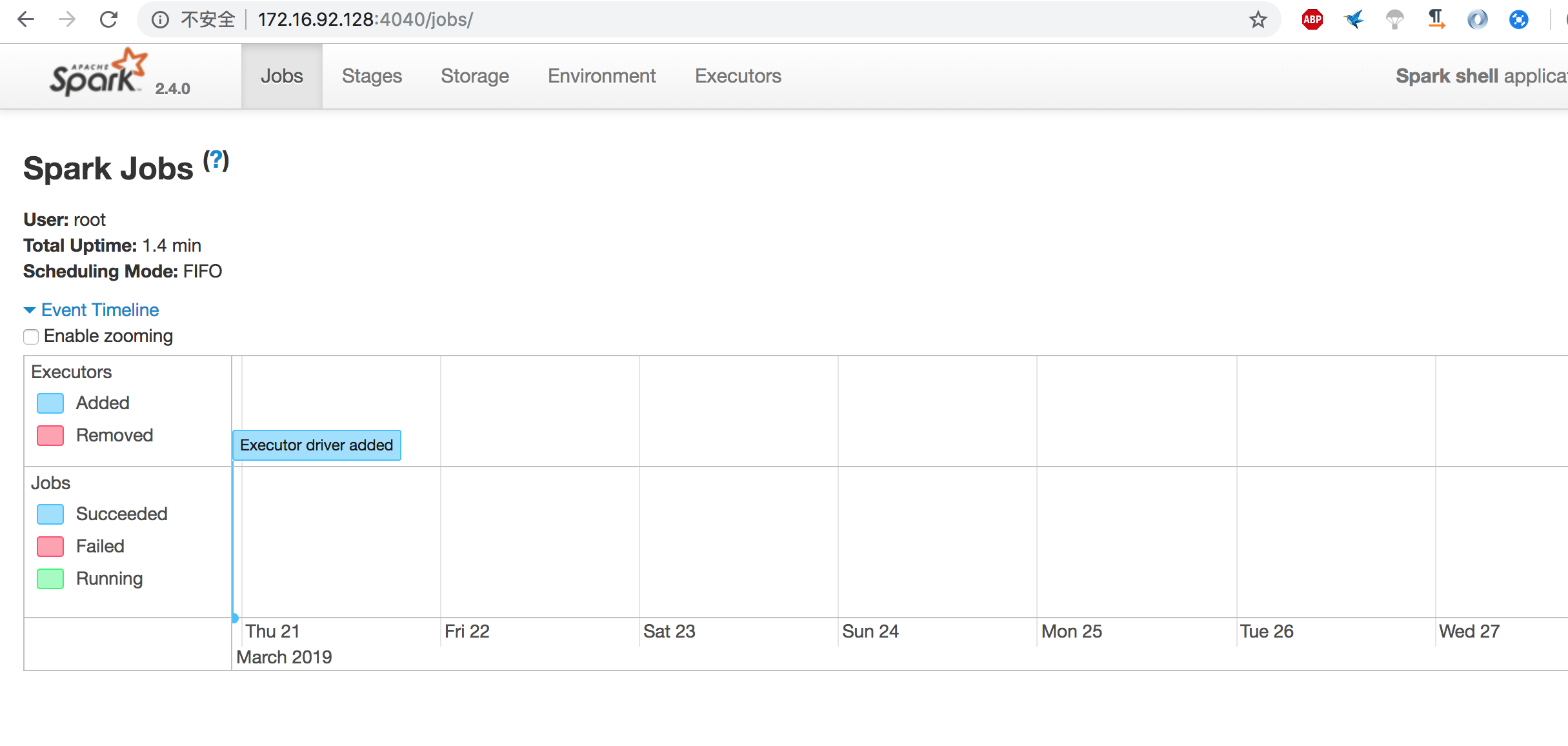
查看webui的jobs
http://172.16.92.128:4040/jobs/
pyspark,scall的是spark-shell
[root@sjck-node01 bin]# pyspark
Python 2.7.4 (default, Mar 21 2019, 00:09:49)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-23)] on linux2
2019-03-21 20:53:11 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_ version 2.4.0
/_/
Using Python version 2.7.4 (default, Mar 21 2019 00:09:49)
SparkSession available as 'spark'.
>>>
上传文件本地文件至HDFS
[root@sjck-node01 data]# hadoop fs -put /data/READ.md
[root@sjck-node01 data]# hadoop fs -ls
Found 1 items
-rw-r--r-- 2 root supergroup 3952 2019-03-23 21:07 READ.md