又到了清明时节,用python爬取了网易云音乐《清明雨上》的评论,统计词频和绘制词云图,记录过程中遇到一些问题
爬取网易云音乐的评论
一开始是按照常规思路,分析网页ajax的传参情况。看到参数都是加密过的,在网上参考别人之前爬虫的思路。发现陆续有人用模拟传参,自己加密参数来实现,主要用python和js版本的。我尝试了几次,加密过程有问题没解决。后来突然看到有人提到了一个get请求获取评论的url,实测可以用,估计是传参之后,实际调用的内部接口。
http://music.163.com/api/v1/resource/comments/R_SO_4_167882?limit=20&offset=0
尝试之后发现可以直接调用,那么就简单多了
下面截取部分爬取的内容
2014-11-25 20:01:18 年轻的记忆:高一听的歌,现在都大三了,时间好快
2016-03-26 19:15:38 这个昵称很多人用过:东瓶西镜放,是安徽古建筑习俗。客厅东部放瓶子,西边放镜子,意为终生平(瓶)静(镜)。[憨笑]
2016-06-28 17:04:09 Gorlomi:周杰伦的中国风是宫廷的,有传统的气息;许嵩的中国风是江南的,有梅雨的味道。
2016-03-16 16:48:20 树下蜗牛壳:半城烟沙半城血,清明雨上客怎眠。千百度里寻伊人,不见当年庐州月。
2015-01-05 20:18:57 等烟雨天青青:初一知道的许嵩,然后就一直听了下来,不知不觉已经大一了,忽然感觉时间过得太快了,,,,那年的我喜欢和她一起坐在操场的台阶上听着这首歌,现在的她还好么?
2015-07-05 21:33:54 lyc秋千坠:记得初二时在考场拼命背书为接下来的考试,听到别人在放《清明雨上》,激动了一下,随后又很失落。当时那么喜欢的歌手别人也在听着,像一杯好酒被别人偷喝了一半,为了骗自己兑上水,却失了原来的味道。再者,总觉得,这样的歌只适合一个人静静听,在那么宽敞的地方放,总觉得被破坏了。
2014-12-05 17:09:40 我的名字十二字不信你数数:你总说毕业遥遥无期 转眼却各奔东西.................
2016-04-04 22:28:55 妈妈说张泽华会是建筑大师:妈,我来看你了。麦苗已经长得很高是你喜欢的希望绿。跟着爸爸后面走向你小时候一起旅游的模样。那年在北京庙会我推着轮椅你新奇少数民族的各种风俗不愿再待在医院等死。现在对所有糯米类的食物迷之爱恋即使是前段时间的青团也容易让我想到当初喂你汤圆的时候你把黑芝麻吃掉把软软的汤圆皮喂给我的样子
2017-03-07 14:46:59 此乃一:十年了,想当年在安医上学的时候,你也没和我上下铺,但是也睡在我对面的下铺,有时候你在寝室哼着没有没有名字的歌曲,大家都在想着你以后可以去唱歌,有时候寝室去逍遥津玩,你也忙着去写歌,结果这么多年过去了,你果然去唱歌了,而我也按部就班的成为了一名医生,也许这就是人各有志吧,523。
2014-12-06 22:17:22 煮壶时光品良辰:传唱许嵩歌,谁知歌里愁?
2016-02-06 18:26:49 杜大官人: “庭有枇杷树,吾妻死之年所手植也,今已亭亭如盖矣”
2015-04-04 14:10:05 女侠七七可能不是流氓:又是一年清明。现在大二。当然不会忘记初中有多疯狂的迷恋他的音乐和他这个人。那时候听清明雨上会脑补如果有MV就该是黑白画面,正装许嵩站在小雨中在墓碑上放一朵白菊。晚上做的梦就不太好了,梦里墓碑上是我的照片……初中同学应该记得吧[大哭]
2014-11-10 18:44:22 蛋挞皮衣:我的许嵩许嵩许嵩。喜欢你 本来与你就无关 何须在乎更多其他的声音[可爱]
2018-04-05 07:17:10 新长征路上的-摇滚:那年刚听这歌的时候我奶奶外婆还健在,如今她们都已驾鹤西去,最大的遗憾是因为驻守在祖国的西南边陲二位最疼我的老人离世时我都在执行任务,我都没能赶会去见最后一面,送上最后一程。奶奶,外婆,又是清明节了,我再也吃不到你们做的清明果,喝不到你们采的清明茶了,你们在那边还好吗?
2018-04-09 15:24:03 酥酥的酱:为何是清明雨上而非雨下? 雨上是有你的天堂,雨下独留我彷徨
2019-04-05 22:28:47 vinegar醋醋:当年清明有嵩鼠给我打电话唱这首歌。转眼已经六七年
2019-04-05 22:28:46 遇见遇见遇见1997:今年的清明节没有下雨
天气很好 愿您也好❤️
2019-04-05 22:28:44 诗卿不诗情:初一的回忆
2019-04-05 22:28:30 月初寒霜冻佳人:又是清明雨上
解析json详情
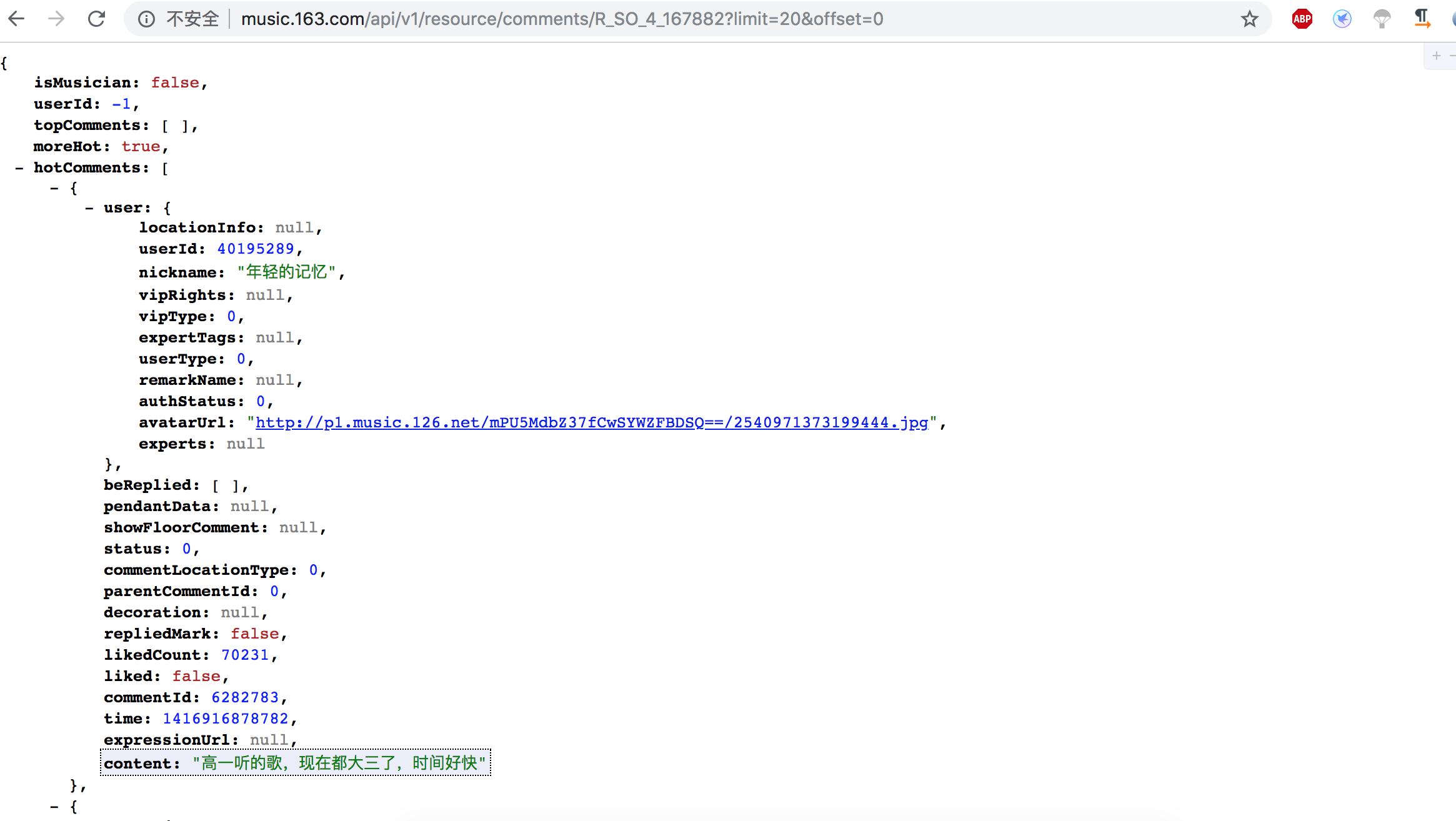 根据url容易看出limit是每页的条数,offset是步长。随便试了几个参数,验证猜想正确。解析requests返回的json结构时,开始第一页的评论内容是hotComments,就都按照hotComments来解析。但是翻页后出错,原来后面其他页的是comments。估计是网易把历史的热门评论放到第一页,后面的是按时间倒叙的日常评论
####词频统计和停止词
接下来对爬下来的txt文本进行词频统计,中文分词用的是jieba库,发现,和。等一类的无用词出现的频率也很高,于是在网上下载了一个停止词的txt文件,将一些没有的常见词过滤掉,不参与统计
根据url容易看出limit是每页的条数,offset是步长。随便试了几个参数,验证猜想正确。解析requests返回的json结构时,开始第一页的评论内容是hotComments,就都按照hotComments来解析。但是翻页后出错,原来后面其他页的是comments。估计是网易把历史的热门评论放到第一页,后面的是按时间倒叙的日常评论
####词频统计和停止词
接下来对爬下来的txt文本进行词频统计,中文分词用的是jieba库,发现,和。等一类的无用词出现的频率也很高,于是在网上下载了一个停止词的txt文件,将一些没有的常见词过滤掉,不参与统计
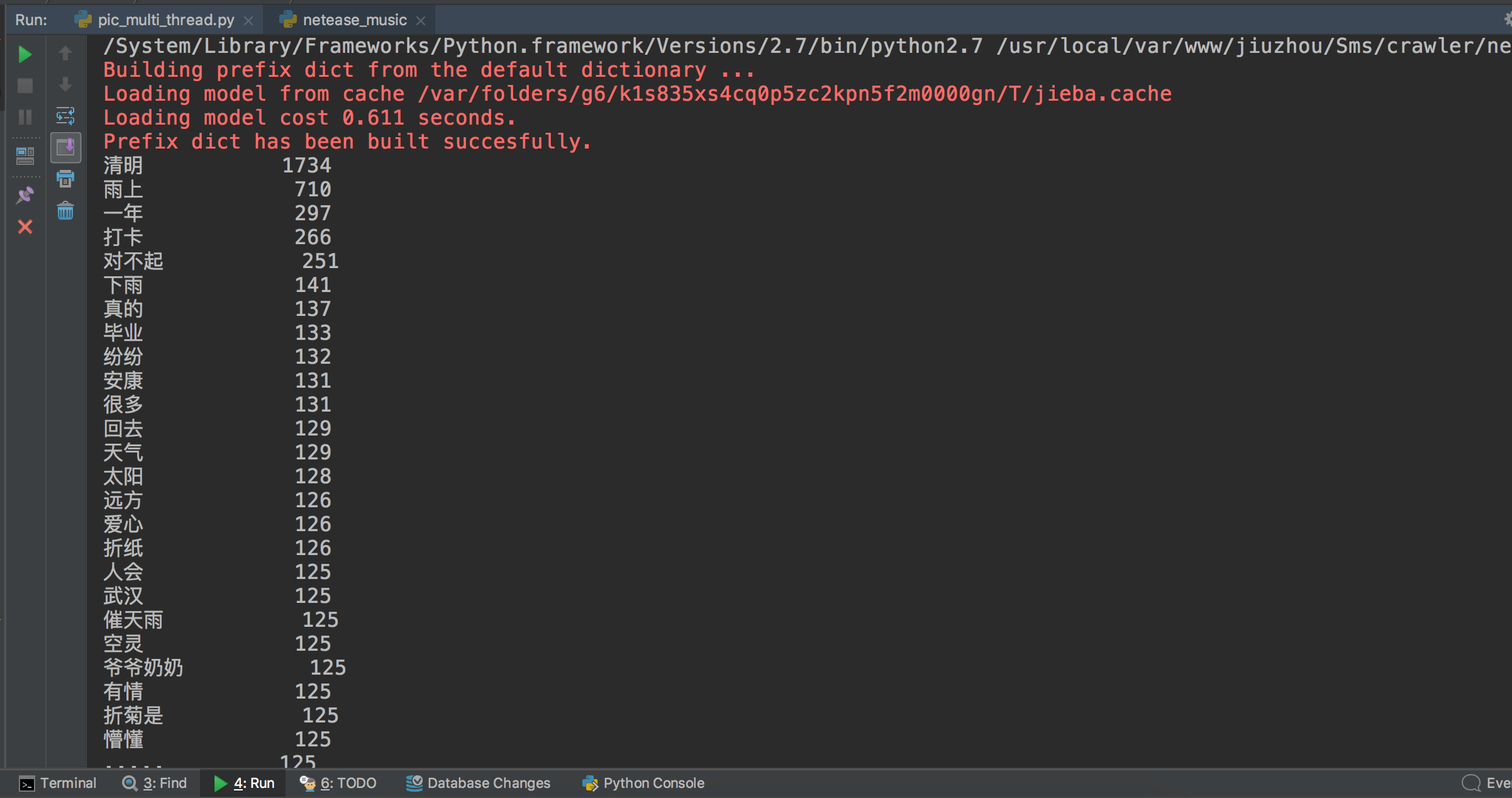 ####词云图
刚开始的时候,图片里的中文是乱码,但是英文可以正常显示。后来发现是要加上font_path='Hiragino Sans GB.ttc',不然中文字体不能正常显示,英文字体则可以直接支持。
####词云图
刚开始的时候,图片里的中文是乱码,但是英文可以正常显示。后来发现是要加上font_path='Hiragino Sans GB.ttc',不然中文字体不能正常显示,英文字体则可以直接支持。
 ####源码如下
```python
# coding: utf-8
import requests
import json
import time
from wordcloud import WordCloud
import jieba
import numpy
import PIL.Image as Image
import io
####源码如下
```python
# coding: utf-8
import requests
import json
import time
from wordcloud import WordCloud
import jieba
import numpy
import PIL.Image as Image
import io
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"referer": "http://music.163.com/song?id=167882&market=baiduqk"
}
stop_path = "./source/stopword.txt"
comment_path = "./source/coments.txt"
获取单页评论,写入文件
def get_comments(url):
res = requests.post(url, headers=headers)
comments_json = json.loads(res.text)
if ('hotComments' in comments_json):
comments = comments_json['hotComments']
else:
comments = comments_json['comments']
# w是写,a是追加
with open(comment_path, 'a') as f:
for each in comments:
comment_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(each['time'] / 1000))
f.write(comment_time + ' ' + each['user']['nickname'] + ':' + each['content'] + '
')
请求格式
host = "http://music.163.com/api/v1/resource/comments/R_SO_4_167882?limit=20&offset=0";
def get_all_comments():
# 歌曲id
id = "167882"
page = 150
base_url = "http://music.163.com/api/v1/resource/comments/R_SO_4_" + id + "?limit=20&offset="
for p in range(page):
offset = p * 20
url = base_url + str(offset)
get_comments(url)
print("page " + str(p + 1) + " finish")
统计词频
def word_count():
with io.open(comment_path, encoding="utf-8") as file:
file = file.read()
stopwords = [line.strip() for line in open(stop_path).readlines()]
words = jieba.lcut(file)
counts = {}
for word in words:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(50):
word, count = items[i]
print ("{:<10}{:>7}".format(word, count))
生成词云图
def word_cloud():
with io.open(comment_path, encoding="utf-8") as file:
file = file.read()
text = ''.join(jieba.cut(file))
mask_pic = numpy.array(Image.open("./source/1.jpg"))
stopwords = open(stop_path).read()
# 3.设置词云的背景颜色、宽高、字数
wordcloud = WordCloud(
font_path='Hiragino Sans GB.ttc',
mask=mask_pic,
stopwords=stopwords,
background_color="white",
width=1200,
height=600,
max_words=500
).generate(text)
file_name = "./pic/" + time.strftime("%Y%m%d%H%M%S", time.localtime()) + ".jpg"
wordcloud.to_file(file_name)
print("save pic finish:" + time.strftime("%Y%m%d%H%M%S", time.localtime()) + ".jpg")
image = wordcloud.to_image()
image.show()
def main():
# 获取前150页评论
get_all_comments()
# 生成词云图
word_cloud()
# 统计词频
word_count()
if name == "main":
main()