一、黏包现象
须知:只有TCP有粘包现象,UDP永远不会粘包!
同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种现象就是黏包。
基于udp协议实现的黏包:
server端:
#_*_coding:utf-8_*_ from socket import * import subprocess ip_port=('127.0.0.1',8888) BUFSIZE=1024 tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) while True: conn,addr=tcp_socket_server.accept() print('客户端',addr) while True: cmd=conn.recv(BUFSIZE) if len(cmd) == 0:break res=subprocess.Popen(cmd.decode('utf-8'),shell=True, stdout=subprocess.PIPE, stdin=subprocess.PIPE, stderr=subprocess.PIPE) stderr=res.stderr.read() stdout=res.stdout.read() conn.send(stderr) conn.send(stdout)
client端
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8888) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) act_res=s.recv(BUFSIZE) print(act_res.decode('utf-8'),end='')
二、黏包成因
主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的。
此外,发送方引起的粘包是由TCP协议本身造成的,TCP为提高传输效率,发送方往往要收集到足够多的数据后才发送一个TCP段。若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成一个TCP段后一次发送出去,这样接收方就收到了粘包数据。
1、TCP是面向连接的,面向流的,提供高可靠性服务。收发两端(客户端和服务器端)都要有一一成对的socket,因此,发送端为了将多个发往接收端的包,更有效的发到对方,使用了优化方法(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样,接收端,就难于分辨出来了,必须提供科学的拆包机制。 即面向流的通信是无消息保护边界的。
2、UDP是无连接的,面向消息的,提供高效率服务。不会使用块的合并优化算法,, 由于UDP支持的是一对多的模式,所以接收端的skbuff(套接字缓冲区)采用了链式结构来记录每一个到达的UDP包,在每个UDP包中就有了消息头(消息来源地址,端口等信息),这样,对于接收端来说,就容易进行区分处理了。 即面向消息的通信是有消息保护边界的。
3、tcp是基于数据流的,于是收发的消息不能为空,这就需要在客户端和服务端都添加空消息的处理机制,防止程序卡住,而udp是基于数据报的,即便是你输入的是空内容(直接回车),那也不是空消息,udp协议会帮你封装上消息头。
注意:
1、udp的recvfrom是阻塞的,一个recvfrom(x)必须对唯一一个sendinto(y),收完了x个字节的数据就算完成,若是y>x数据就丢失,这意味着udp根本不会粘包,但是会丢数据,不可靠
2、tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
会发生黏包的两种情况:
情况一 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据了很小,会合到一起,产生粘包)


#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello'.encode('utf-8')) s.send('egg'.encode('utf-8'))
情况二 接收方的缓存机制 接收方不及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
#_*_coding:utf-8_*_ from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(2) #一次没有收完整 data2=conn.recv(10)#下次收的时候,会先取旧的数据,然后取新的 print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()
#_*_coding:utf-8_*_ import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(ip_port) s.send('hello egg'.encode('utf-8'))
黏包现象只发生在tcp协议中:
1.从表面上看,黏包问题主要是因为发送方和接收方的缓存机制、tcp协议面向流通信的特点。
2.实际上,主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的
三、黏包解决方案(自定义报头)
首先了解一个 struct模块
>>> struct.pack('i',1111111111111) struct.error: 'i' format requires -2147483648 <= number <= 2147483647 #这个是范围
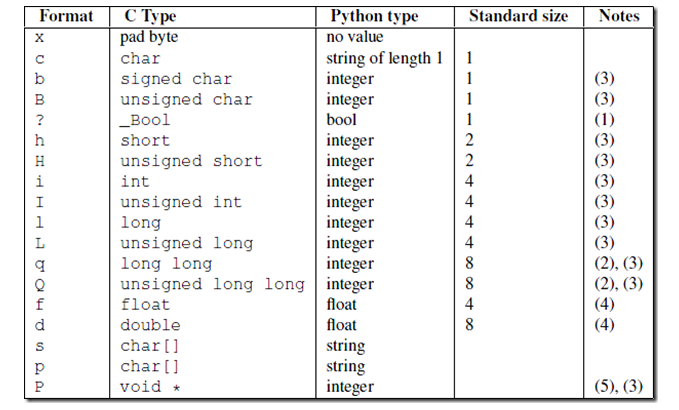
import json,struct #假设通过客户端上传1T:1073741824000的文件a.txt #为避免粘包,必须自定制报头 header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T数据,文件路径和md5值 #为了该报头能传送,需要序列化并且转为bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化并转成bytes,用于传输 #为了让客户端知道报头的长度,用struck将报头长度这个数字转成固定长度:4个字节 head_len_bytes=struct.pack('i',len(head_bytes)) #这4个字节里只包含了一个数字,该数字是报头的长度 #客户端开始发送 conn.send(head_len_bytes) #先发报头的长度,4个bytes conn.send(head_bytes) #再发报头的字节格式 conn.sendall(文件内容) #然后发真实内容的字节格式 #服务端开始接收 head_len_bytes=s.recv(4) #先收报头4个bytes,得到报头长度的字节格式 x=struct.unpack('i',head_len_bytes)[0] #提取报头的长度 head_bytes=s.recv(x) #按照报头长度x,收取报头的bytes格式 header=json.loads(json.dumps(header)) #提取报头 #最后根据报头的内容提取真实的数据,比如 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)
关于struct模块的用法:
#_*_coding:utf-8_*_ #http://www.cnblogs.com/coser/archive/2011/12/17/2291160.html __author__ = 'Linhaifeng' import struct import binascii import ctypes values1 = (1, 'abc'.encode('utf-8'), 2.7) values2 = ('defg'.encode('utf-8'),101) s1 = struct.Struct('I3sf') s2 = struct.Struct('4sI') print(s1.size,s2.size) prebuffer=ctypes.create_string_buffer(s1.size+s2.size) print('Before : ',binascii.hexlify(prebuffer)) # t=binascii.hexlify('asdfaf'.encode('utf-8')) # print(t) s1.pack_into(prebuffer,0,*values1) s2.pack_into(prebuffer,s1.size,*values2) print('After pack',binascii.hexlify(prebuffer)) print(s1.unpack_from(prebuffer,0)) print(s2.unpack_from(prebuffer,s1.size)) s3=struct.Struct('ii') s3.pack_into(prebuffer,0,123,123) print('After pack',binascii.hexlify(prebuffer)) print(s3.unpack_from(prebuffer,0)) 关于struct的详细用法
conclusion:
自定义复杂报头 完成发送一些额外的信息 例如文件名
1.将要发送的额外数据打包成一个字典
2.将字典转为bytes类型
3.计算字典的bytes长度 并先发送
4.发送字典数据
5.发送真实数据
服务器端示例: # 为了方便存取 可以把需要的信息打包为一个字典 dic{ "filename":"仓老师视频教学 如何做炸鸡!", "md5":"xzxbzxkbsa1212121", "total_size":2121221 } # 字典转字符串? json head_dic = str(dict) bytes = head_dic.encode("utf-8") # 先发送这个字典字符串的长度 dic_len = len(head_dic) #将长度转为了 字节 bytes_len = struct.pack("i",dic_len) # 发送报头的长度 c.send(bytes_len) # 发送真实数据 c.send(xxx.mp4.bytes)
TCP能传的只有字节