今天是2020年3月13日星期五。不知不觉已经在家待了这么多天了,从上一节EM算法开始,数学推导越来越多,用mathtype码公式真的是太漫长了。本来该笔记是打算把《统计学习方法》这本书做详细的解读,起初面对书里大量的数学推导,感到非常恐惧。假期“空窗”时间不少,才有了细嚼慢咽学习的机会。其实很大的原因是自己掌握的东西太少,知道的算法太少,所以才对这本书恐惧。买了一直放着不愿意学。现在到隐马尔可夫模型,再有一章条件随机场,监督学习部分就结束了。这一个月来,最大的收获是知道了“怎么学”。
新的章节抛出一个新的算法模型,往往丈二和尚摸不着头脑,什么都是新的。越是拖延进度越慢,更不能一口吃个胖子指望看一遍就能懂。书读百遍,其意自见,一遍不懂就再看一遍,一遍有一遍的收获。但这个过程千万不要盯着一本书看,一定要多找博客,多看知乎、CSDN,保持审视的态度,保留自己的见解。另外,我是喜欢直接看文字,实在不懂了才去翻视频看,觉得这种模式挺适合我。
学到第十章,发现书中的很多东西,没必要面面俱到,要适当的取舍和放过。因为毕竟这本书不是一次性消耗品,是值得深究和研习的。第一次不懂的东西,完全可以学习完所有章节,建立大的思维格局后,再重新考虑小细节。
接下来的所有章节,从例子出发,引入各个概念;手写推导过程;图解算法流程;最后实现代码。掰扯开来,其实也就是三个问题:该模型是什么样子的(考虑如何引入);该模型为什么可以这样做(考虑如何理解推导过程);该模型怎么应用(考虑代码实现和应用场景)。
GitHub:https://github.com/wangzycloud/statistical-learning-method
隐马尔科夫模型
引入
隐马尔科夫模型描述由隐藏的马尔可夫链随机生成观测序列的过程,属于生成模型。把这句话倒着思考一下:(1)该模型属于生成模型,会不会类似EM算法中考虑的,一个观测数据y的生成,中间需要经过一个隐藏状态z。(2)很明显这里生成的不是单个数据,而是单个数据构成的一个序列,并存在时序关系。(3)马尔可夫链是什么?在生成数据序列的过程中扮演什么角色?
先区分两个概念,“状态and观测”。在我的理解里,“状态”也好,“观测”也罢,不过是表达随机变量的一个说法。状态会有多个状态,观测会有多个观测,但同时只允许一个状态或者一个观测出现。例如,现在有四个盒子(灰、黄、绿、蓝),李华在五天内选盒子取球,规定每天只能取一个盒子(每个盒子被选的概率一样大)。问,李华这五天可能会有多少种取盒子的序列,并问取到某种序列的概率是多少?如下:

你知道的,这个组合数不小。因为每个盒子被选到的概率一样大,所以每个序列出现的概率相同。李华每天在盒子里取球(红、白),现在限制每个盒子红球、白球数目相同(红、白球各有五个)。问,李华五天内取到球的颜色的序列有多少种,并问取到某种序列的概率是多少?
显然,这个组合数要小一些。因为每个盒子中红白球数目相同,且此时盒子的选择(状态)对球的选取无影响,所以每个序列出现的概率相同。可是如果每个盒子中,红白球的数量不是五五开,各不相同呢?李华五天内取球的某个序列的概率,就不再相同了。另外,除了受到盒子内红白球的概率分布影响,还要受到某天会抽到哪个盒子的概率分布影响。
在上述例子中,把可能取到的盒子情况,称作“状态”;把可能会取到的球的情况,称作“观测”。在隐马尔科夫模型中,盒子会取到的各种状态,我们是观测不到的。而球的各种情况我们是知道的,可以被观测到。
取球要受到盒子所在状态的影响,示意图如下:
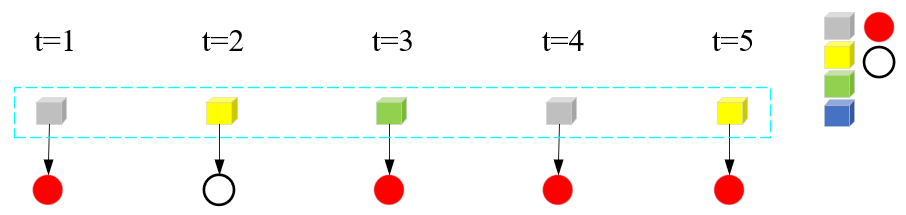
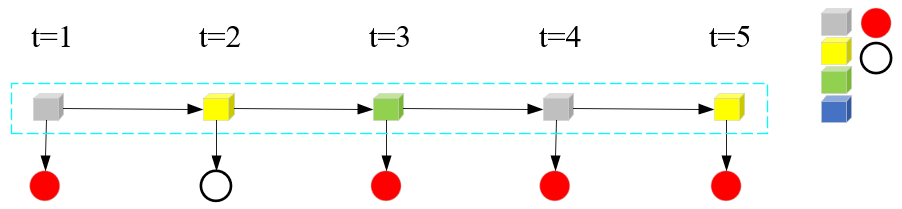
此时,还不能叫做隐马尔可夫模型的示例。需要继续给“取盒子->取球->得到观测序列”的过程施加限制条件。比如说,t时刻取到某个盒子,要受到t-1时刻盒子的状态影响。一个简单的例子,t-1时刻盒子是绿盒子,t时刻一定取灰色盒子,且t-1时刻取到绿盒子不对t+1、t+2、...、T时刻产生影响。具体一点,就是让“当前时刻隐藏状态”只受上一时刻“隐藏状态”影响,且与所处的时刻t无关。
通过一步步施加的各个条件,此时可以称作隐马尔可夫模型的示例了。
隐马尔科夫模型的基本概念
先上例子,盒子和球模型。


在这个例子中有两个随机序列,一个是盒子的序列(状态序列),也就是每次选取到的盒子序列,这个过程是隐藏的,观测不到从哪个盒子取球;一个是球的颜色序列(观测序列),我们只能知道取出来的各个球的颜色。
先分析一下取盒子环节,这是一个环环相扣的过程。从当前t-1时刻的盒子出发,考虑t时刻会取到哪个盒子,要符合规则。如当前盒子是1,根据上述规则,下一个盒子一定是盒子2。考虑t+2时刻会取到哪个盒子,要站在t+1时刻的盒子状态上,决定取哪一个盒子。所谓的马尔可夫性,很重要的一点,就是t-1时刻的状态只决定t时刻的状态(盒子1之后一定会取到盒子2),并不能决定t+1时刻状态的取值(盒子1之后,决定不了盒子2之后会取哪个盒子)。
再看一下取球环节,对应着描述中的从盒子中随机取球的过程。每个盒子里边红、白球的数目不同,不同的盒子取到红色球的概率不同。当前盒子有属于自己的概率分布,取球的概率不尽相同。
用数学语言完善完善以下过程:盒子可以构成一个集合;当前时刻的盒子如何确定下一个盒子,需要有状态转移概率;球可以够成一个集合;从不同盒子里边取球,需要知道每个盒子的概率分布;取了多少个球,需要有序列长度;最开始怎么选第一个盒子。
根据所给的条件,有以下:



重点看一下状态转移矩阵。

熟悉了这个例子,再来理解数学上的各个概念。

这里的状态随机序列就是每次取到盒子组成的序列,观测序列就是球颜色的序列。隐马尔科夫模型由状态的初始概率分布、状态中间的转移概率分布以及观测概率分布组成。

对应着看,Q就是例子中盒子的集合,V就是球颜色的集合,I是盒子序列,O是颜色序列。
令A为状态转移矩阵:

这里的变量i有点混乱,注意区分。公式10.2中,(1)aij中的i是状态转移矩阵A中的第i行的意思,aij也就是矩阵A中的第i行第j个元素,该值表示从第i个元素转移到第j个元素的概率;(2)it+1、it中的i是指该状态序列中的第t+1、第t个状态,这里i是序列的意思;(3)qi中的i是在状态集合中取到哪个状态的意思。
t+1时刻能够取到哪个状态,要受到t时刻状态的影响。也就是在t时刻状态取某个值的条件下,t+1时刻才会有什么样的取值。矩阵A维度为N*N,也就是要知道该时刻每个状态对下一时刻每个状态的影响。

观测有M种,vk可以理解为观测集合V中的第k个观测。在盒子和球的例子中,可以看到每个观测的取值,是由隐变量的状态->哪个盒子决定的,并且只与当前的盒子有关系,每个盒子有各自取球的概率分布。用概率符号表示就是公式10.4,表示在状态为第j个盒子的情况下,观测到vk的概率。
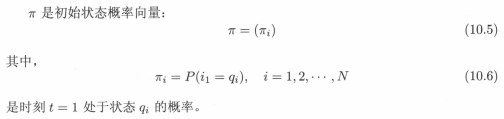
用π来表示初始概率向量,也就是t=1序列起始时,根据一定的概率分布选择第一个盒子。

在这里,状态转移概率矩阵A与初始状态概率向量π确定了隐藏的马尔可夫链,可生成不可观测的状态序列。观测概率矩阵B确定了如何从状态生成观测,与状态序列综合确定了如何产生观测序列。
从上述描述及定义10.1可以看到,隐马尔科夫模型做了两个基本假设:

(1)再次回顾盒子和球模型,盒子的选择是不是只规定了时序上前后相邻的盒子该怎么选;而没有第一次选盒子1,第三次一定会选到盒子3这样的规定。也就是在任意时刻t的状态只依赖于其前一时刻t-1的状态,这就是马尔科夫链“齐次”的重要性质。
(2)观测独立性假设是指我们观测到的每一次现象(红球、白球),只与该球所在盒子的概率分布有关,与其它盒子的概率分布没有一点关系!与其它时刻的观测没有一点关系!
观测序列的生成过程可以由算法10.1描述。

HMM和CRF,与之前学习的各个模型,差别是比较大的,学习思路是要换一换。理解了隐马尔科夫模型的基本概念,下一步就是要考虑该模型可以做什么?怎么做?这里我接触的不多,只能顺着书本的思路,学习隐马尔可夫模型的三个基本问题。
1)概率计算问题。很自然的,考虑一下某个观测序列O出现的概率P(O|λ)。
2)学习问题。已知观测序列,用极大似然估计的方法估计模型参数λ=(A,B,π)。
3)预测问题,也称解码问题。知道模型参数,给定观测序列,求最有可能的对应的状态序列。
概率计算算法
1)直接计算
已知模型参数λ=(A,B,π)和观测序列O=(o1,o2,...,oT),计算观测序列O出现的概率P(O|λ)。很容易想到,可以按照概率公式直接进行计算。把得到观测数据的过程,想象成两个阶段:选取状态和生成观测。第一步得到状态序列,第二步得到观测序列,可以应用乘法原理。不同的观测序列可以得到不同的观测序列,可以应用加法原理。类似于全概率公式,通过列举所有可能的状态序列I,求各个状态序列I上生成观测O的概率(也就是I,O的联合概率),然后对所有可能的状态序列求和,得到P(O|λ)。

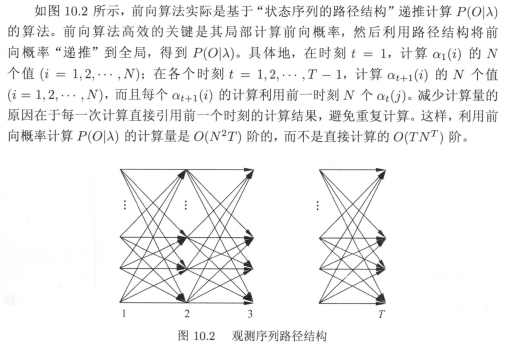
容易理解,公式(10.10)为全部状态序列中某个状态序列I的概率计算公式;公式(10.11)为在该状态序列I条件下,观测序列为O时的条件概率计算方法;公式(10.12)为联合概率公式;公式(10.13)对所有可能的状态I求和,也就是求O的边缘概率(考虑在I出现的所有情况条件下,O出现的概率)。简单分析下,若状态数目为N,一共有T个状态序列,所以状态序列的可能性为NT。每一种状态序列都要相应乘T个观测概率,所以最后的时间复杂度为O(TNT)。用这种方法计算观测序列O出现的概率,是非常低效的。接下来介绍高效的计算方式,前向-后向算法。
2)前向算法
先来看一个新概念“前向概率”:

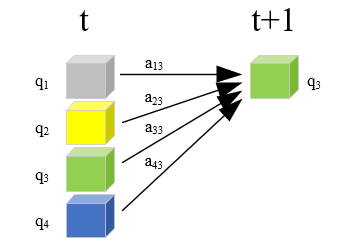
放在示意图上,如蓝色虚线框α3(i)=P(o1,o2,o3,it=qi|λ),可以从联合概率的角度理解。具体为 αt=3(灰色盒子)=P(o1=红球,o2=白球,o3=红球,it=3=灰色盒子|λ):
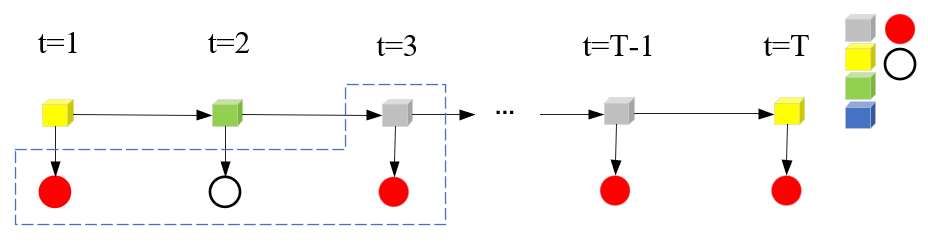
在前向概率的基础上,定义前向算法为:

步骤(1),计算初值。注意这里α1(i)应用向量来表示,在t=1,观测取到o1时,各个隐藏状态i都有到达o1的概率。计算分两步,从初始概率πi到隐状态qi,再从qi经发射矩阵到观测o1,需要对每个隐藏状态i计算。
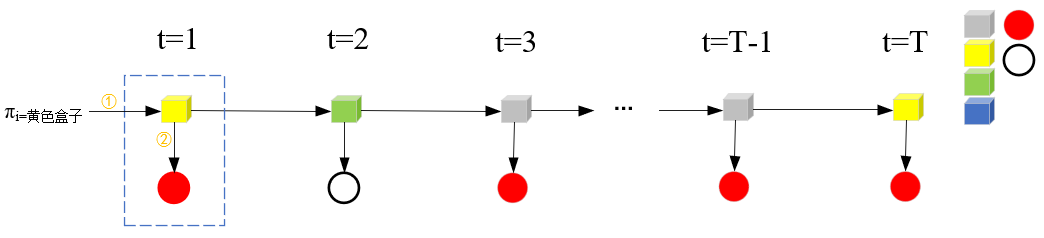
步骤(2),前向算法递推公式。αt(i)递推到αt+1(i),公式(10.16)中的bi(ot+1)可以理解为下图第二步,由所在的状态qi经发射矩阵得到观测ot+1;aji可以理解为下图中的第一步,也就是由t时刻状态qj经转移矩阵在t+1时刻状态为qi的过程。
公式(10.16)中的求和符号,实际上反映的是t+1时刻取qi时,其实t时刻的任何一个状态都可以转移到qi,因此要把t时刻的每种状态都考虑到。
步骤(3),终止。公式(10.17)的求和符号挺好理解的,因为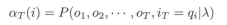 ,对iT=qi求和,实际上相当于求观测序列O的边缘概率。
,对iT=qi求和,实际上相当于求观测序列O的边缘概率。
再来看一下书中的详细解释:


通过画图,是不是要好理解一些~前向算法高效就高效在利用先前的局部计算结果,通过路径结构将局部结果“递推”到全局。
看一下例10.2,基本上就可以理解这个计算过程了。

3)后向算法
相应的,后向算法先了解“后向概率”这个概念。

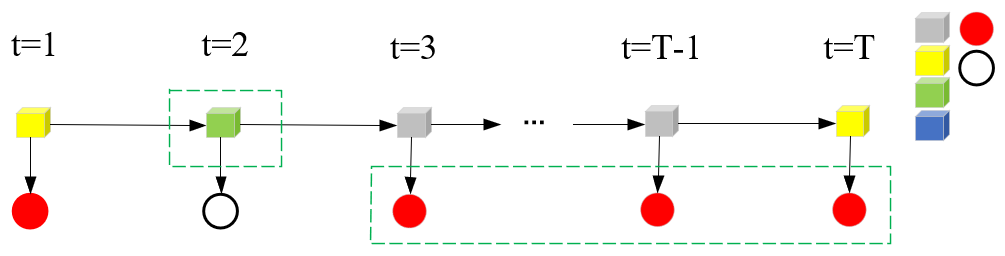
放在示意图上,如绿色虚线框β2(i)=P(o3,...,oT-1,oT,it=qi|λ),可从条件概率的角度理解。具体为βt=2(绿色盒子)=P(o3=红球,oT-1=红,oT=红球|it=2=绿色盒子,λ):
在后向概率的基础上,定义后向算法为:

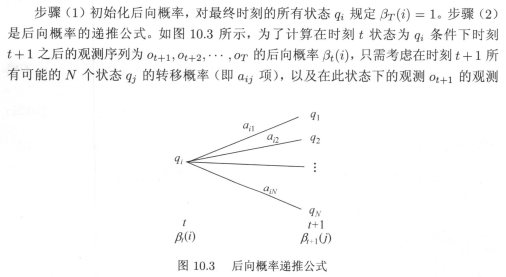
步骤(1),初始化后向概率。这里将最终时刻的所有状态qi规定为βT(i)=1以下示意图简单分析。
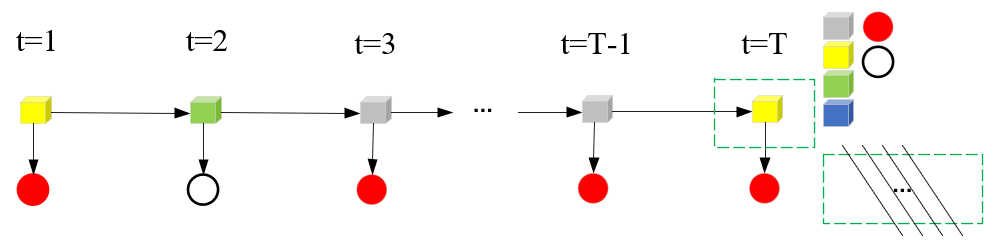
这就好像是βt(i)=P(ot+1,ot+2,…,oT|it=qi, λ)变成了βt(i)=P(it=qi, λ),此时对于it的所有取值,it=qi,是一个不争的事实。
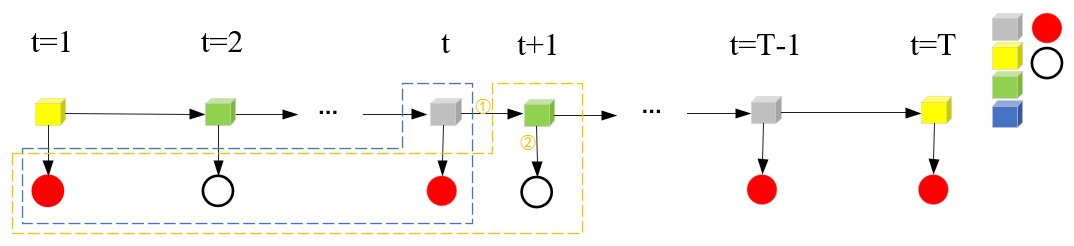
步骤(2),后向算法递推公式。这里的递推方向是反向由T+1递推到T,图示如下:
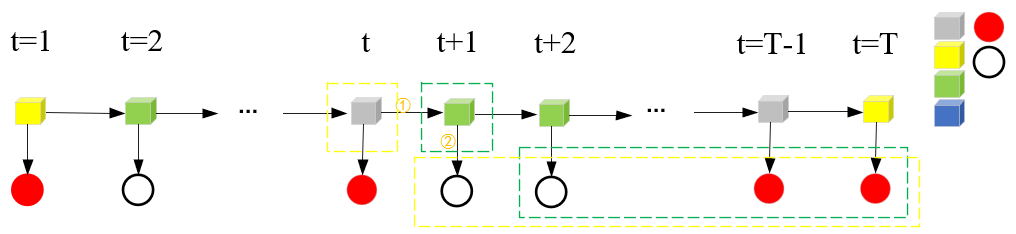
这里由T+1递推到T,仍然需要①②两处的连接。①是公式(10.20)中的aij,②是公式(10.20)中的bj(ot+1)。求和符号是t时刻qi到t+1时刻qj所有情况的汇总。取(qi=灰色盒子,ot+1=白球)进行分析:
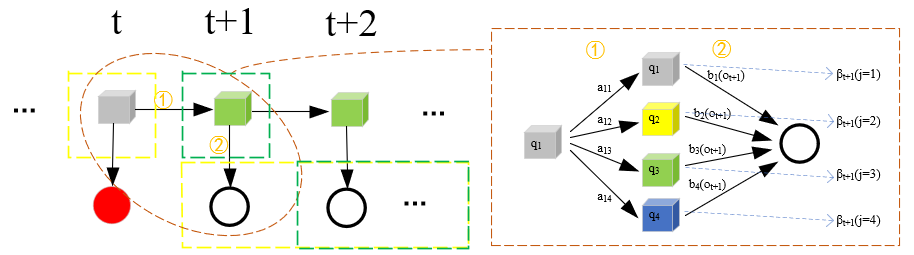
T+1递推到T,我觉得图画的应该差不多了...①②部分是怎样起到连接作用的...大概就是上图这样吧...我解释不出来...当然了,知乎也好CSDN也好,有详细推导公式,我就不班门弄斧了。书面解释如下:

于是,利用前向概率和后向概率的定义,可以将观测序列概率P(O|λ)同一写成:

示意图好像是这个样子:
公式(10.22)中,先来看前向概率的求和部分,i=1时,αt(1)是t时刻盒子为灰盒子,观测序列为(o1,o2,...ot,it=q1)的概率;相应的,αt(2)是t时刻盒子为黄盒子,观测序列为(o1,o2,...ot,it=q2)的概率;αt(3)是t时刻盒子为绿盒子,观测序列为(o1,o2,...ot,it=q3)的概率;αt(4)是t时刻盒子为蓝盒子,观测序列为(o1,o2,...ot,it=q4)的概率。那么求和自然就代表着,不考虑盒子的影响,观测序列为(o1,o2,...ot)的边缘概率。对应示意图,也就是消除了t时刻状态的影响。
同理,后向概率的求和部分,在示意图中相当于消除了t+1时刻状态的影响。①对应着公式(10.22)中的aij,建立连接。②对应着公式(10.22)中的bj(ot+1),将ot+1时刻的观测计入统计。
4)一些概率与期望值的计算
利用前向概率和后向概率,可以得到关于单个状态和两个状态概率的计算公式。头几遍看这几个公式的时候,丈二和尚摸不着头脑,不知道这几个概率计算有什么用,就没怎么好好看。编写这部分代码的时候,发现这几个公式挺重要的。在学习算法小结,对估计模型参数非常有用。公式介绍的挺具体的,这里就不在画图了...学习的时候随手画画图,就能理解了~
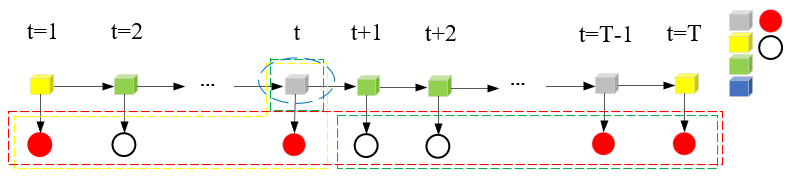
1)求单个状态的条件概率:

还是画吧,这里γt(i)反映是在给定观测序列O条件下,t时刻处于状态qi的概率。如下图,γt(i=灰色盒子)。
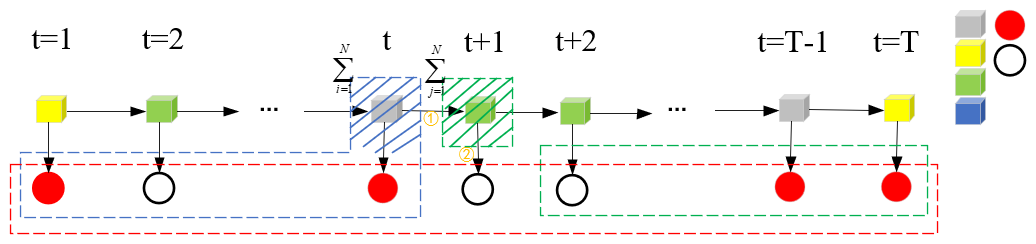
2)求两个连续状态的条件概率:

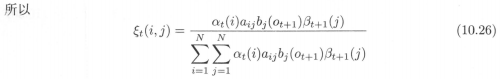
如下图所示ξt(i,j)反映的是,在给定观测序列O的条件下,t时刻状态为灰色盒子、t+1时刻状态为绿色盒子的条件概率。
3)一些有用的期望,在学习算法小节可以看到用处:

学习算法
书中提到,我们进行隐马尔可夫模型的学习,也就是对模型参数进行估计。根据训练数据是包括观测序列和对应的状态序列,还是只有观测序列,可以分别由监督学习和无监督学习实现,这里监督学习方法实际上就是利用极大似然估计。
1)监督学习方法。书中直接给出了参数估计公式,这里简单摘抄下~


2)无监督学习方法。顾名思义,无监督方法也就是只有观测序列,进行参数估计的方法。由于监督学习需要使用标注的训练数据,而人工标注训练数据往往代价很高。因此有时候就会利用无监督学习的方法。我们可以将观测序列数据看作EM算法中的不完全数据,状态序列数据看作EM算法中不可观测的隐数据,那么隐马尔可夫模型就可以看作是含有隐变量的概率模型。于是,可以通过EM算法求解。
详细过程如下:
1.确定完全数据的对数似然函数
2.EM算法的E步:求Q函数Q(λ,λ^)
3.EM算法的M步:极大化Q函数Q(λ,λ^)求模型参数A,B,π
书本上有详细的推导公式,看懂了2/3,先不摘抄了。有空了把理解了的整理上来,参数估计公式如下:


于是,有以下Baum-Welch算法,从这里可以发现一些期望的用处:

预测算法
预测算法,也就是根据已知的观测序列,找到概率最大的状态序列(最有可能的对应的状态序列)。
应用维特比算法,相当于有向无环图求最短路径,网上有大量详细的资料,暂不整理了~
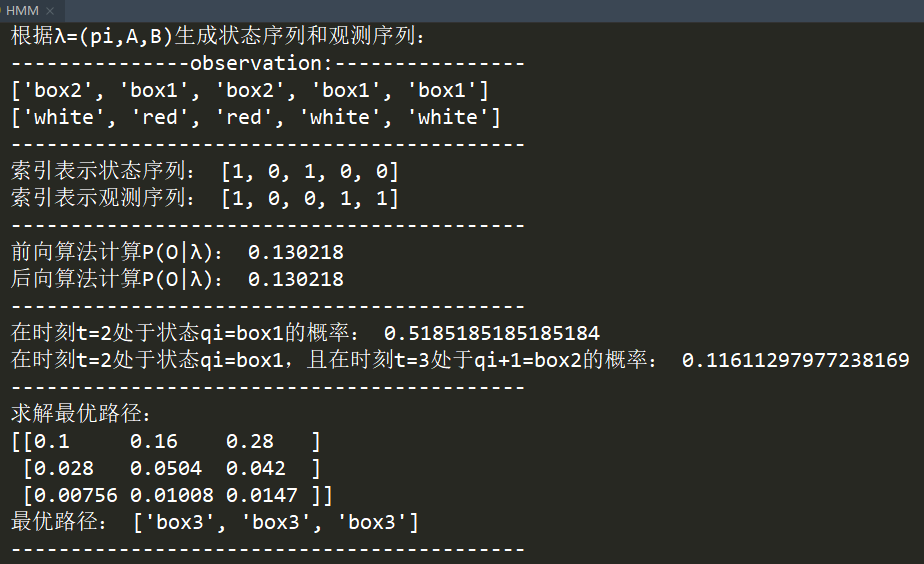
代码效果