索引
其实在计算机中我们早已接触过跟索引有关的东西,比如数据库里的索引(index),还有硬盘文件系统中其实也有类似的东西,简而言之,索引是一种为了方便找到自己需要的东西而设计出来的条目,你可以通过找索引找到自己想要内容的位置。索引过程是: 关键字->索引->文档。在图书馆内的书分门别类,就是一种按类别来分的索引。当然索引还有很多其他的实现。
仅仅有索引的概念是不够的。虽然分门别类是一种方法,但是我们在拥有一堆文档的时候必须要有从文档到索引的规范过程,并且索引的结构要提供快速查找的功能。面对一条长长的没有处理的索引列表,甚至还没有排好序,你可能要用O(N)的时间去看,头都大了。
为了满足这个要求,B+树,哈希表可以是比较好的选择,它们的复杂度分别是O(log N) 和 O(1)。
但是事实上为了满足特殊的要求,有些时候还要设计更加特殊的数据结构,比如后缀树组和trie树用来处理非文本的序列子串搜索。
在主要的搜索引擎中,还是靠文本搜索,而索引的设计其实并不固定,还要跟搜索策略结合,这些都是搜索引擎的部分。
倒排索引
倒排索引是索引的子集。在搜索引擎之中,正排索引跟倒排索引其实都有应用。
正排索引:知道文档d,得到d的关键字的位置序列,实现方式是 文档编号+关键字数组
倒排索引:知道关键字w,找到包含关键字的文档d1,d2,d3.... 实现方式是:关键字key做键的字典,值是文档编号数组
无论是哪一种索引,都要用一种能够快速检索的数据结构的来实现,否则它们都会面临大规模甚至超大规模的数据下无法工作的问题。
哈希表
哈希表,根据键找到值,复杂度为O(1)。它的实现是一组桶,每个桶=头部键+尾部链表。数据结构课程中对哈希表已经讲得很清楚了。它的问题在于空间消耗太大,而且可能会有哈希分配不平衡的问题。
跳表
参考一下 https://juejin.im/post/587c6cec61ff4b006501e006
跳表是一种特殊的链表,又称跳跃表,可以达到O(log N)的查询速度。这里的图说明了跳表的元素其实都在底层,但是可以有一些重复的层级为了方便检索。它的问题在于怎样平衡空间和时间效率上。
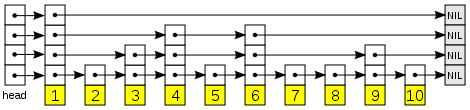
跳表中用到了概率,它设定某个跳表元素的i副本出现在i+1层的概率为p,根据概率对每个值求和得到元素k的期望出现次数 (∑p^k=1/(1-p), k = 1,2,...)。现实中并不会完全按照概率来进行设计,而是用一个固定的步长来设计多级的并联链表。
结论
倒排索引和跳表是为了方便检索和加快速度而设计的结构,并且在搜索引擎中为后续的其他操作提供了基础。现实中经常讲到的是倒排索引,以及跟它关联的tfidf。为了实现数据的快速搜索,还需要跟具体的数据结构相结合。