一、概述
用来统计词频及逆向文件频率。词语由t表示,文档用表示,词料库由D表示,词频TF(t,d)表示词语在文档中出现的频率,文件频率DF(t,D)表示包含词语的文档个数。
TF:指HashingTF,是一个转换器,在文本处理时,接收词条的集合并将其转换成固定长度的特征向量,这个算法会在哈希的同时统计词频。
IDF:是一个评估器,在一个数据集上调用它的fit()方法,产生一个IDFModel,该模型接受特征向量计算词频。IDF会减少在词料库中出现频率较高的词的权重,因为词频高代表其辨识度较低,所以降低他的重要程度。
TF-IDF定义式: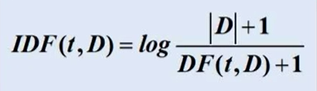
TF-IDF度量式: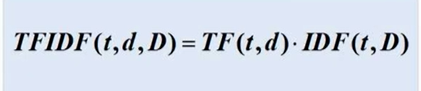
二、实现过程
首先先定义一个句子
使用分解器将句子划分成单词
对于每一个句子,使用HashingTF转化成特征向量
最后使用IDF重新调整特征向量
三、代码实现
3.1导入相关包
![]()
3.2创建一个简单的DataFrame

.toDF()方法中的两个参数含义是构建DataFrame的两个列,一个列是标签列,对应句子前的0或者1,一个列是句子列,代表句子
3.3对上面构建的二维表进行转化,把句子划分成单词

3.4将句子哈希成特征向量

3.5使用IDF进行训练

调用.fit()进行训练
3.6调整权重

四、学习视频
https://www.bilibili.com/video/BV1oE411s7h7?p=73