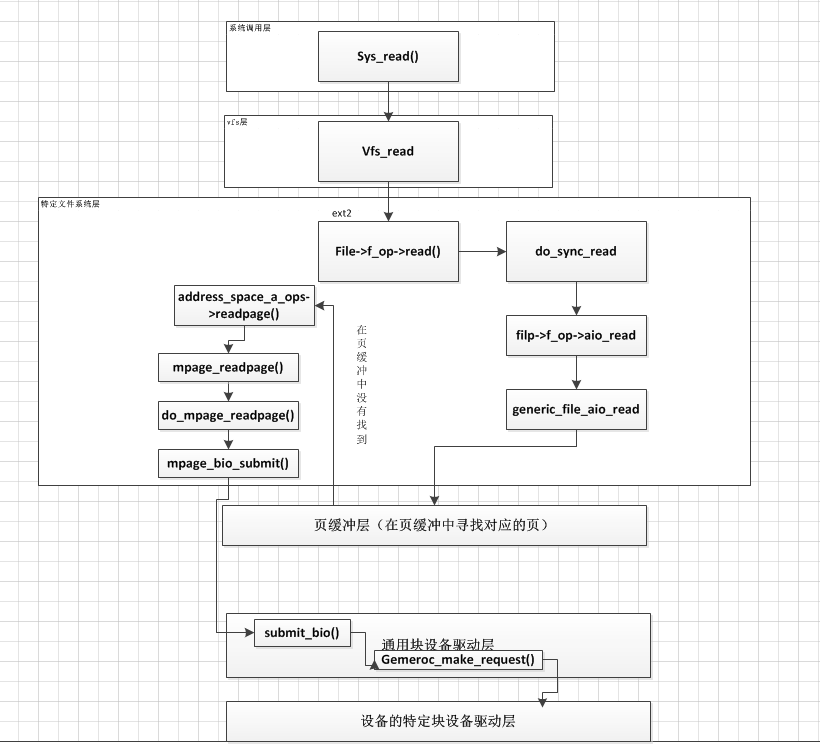
本文从read函数入手,主要讲述从页缓冲,一直到具体的块请求被提交给块设备驱动程序的过程,以下是本文讲述的一张概图,也是对本文的一个概括,可以结合本图,首先由一个从全局上有个清楚的认识,然后再去查看具体的代码,当然本文只是从大体流程上对页缓冲的处理流程进行分析,还有很多小的细节没有搞清楚,后面还需要继续研究。
1.具体文件系统
我们知道通用文件系统也就是虚拟文件系统,只是定义了一组接口,具体的实现是由具体文件系统来实现的。我们以ext2文件系统为例,来查看。
const struct file_operations ext2_file_operations = {
.llseek = generic_file_llseek,
.read = do_sync_read,
.write = do_sync_write,
.aio_read = generic_file_aio_read,
.aio_write = generic_file_aio_write,
.unlocked_ioctl = ext2_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext2_compat_ioctl,
#endif
.mmap = generic_file_mmap,
.open = generic_file_open,
.release = ext2_release_file,
.fsync = simple_fsync,
.splice_read = generic_file_splice_read,
.splice_write = generic_file_splice_write,
};
1.1.可以看到ext2的read其实际上执行的是do_sync_read()函数。
ssize_t do_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
kiocb.ki_left = len;
for (;;) {
ret = filp->f_op->aio_read(&kiocb, &iov, 1, kiocb.ki_pos); //读操作开始
if (ret != -EIOCBRETRY)
break;
wait_on_retry_sync_kiocb(&kiocb);
}
if (-EIOCBQUEUED == ret)
ret = wait_on_sync_kiocb(&kiocb);
*ppos = kiocb.ki_pos;
return ret;
1.相同的参数沿着上一层的读函数传递下来,这些参数有:文件指针filp,指向内存缓冲区的指针buf(要读取的内容将被保存在这个缓冲区中),读入的字符数count以及从文件的哪个位置开始读ppos.
2.这个函数一进来就对struct iovec进行初始化,由其初始化的代码可知,该结构体包含用户空间缓冲区的地址和长度,读入的数据就被存入到了这个缓冲区。
3.接下来的struct kiocb,用来表示内核的I/O控制块。它用来跟踪正在运行的同步和异步的I/O操作。在这里用文件指针来初始化kiocb,即将正在进行的I/O操作与该文件对象关联起来。
4.接下来就进入实际的读操作。由上面的ext2_file_operation可知其调用的是generic_file_aio_read函数
注意
kiocb和iovec是Linux内核中协助异步I/O操作的两个数据类型。当进程希望执行输入输出操作,但并不需要等一会儿就马上得到操作结果时,异步I/O是非常合适的。内核I/O控制块(kiocb)是辅助管理I/O向量所需要的结构,它帮助管理I/O向量如何异步的操作以及如何操作。
1.2.generic_file_aio_read函数
在该函数中,分为两路:一路是当设置了O_DIRECT标志:
if (filp->f_flags & O_DIRECT) {
loff_t size;
struct address_space *mapping;
struct inode *inode;
mapping = filp->f_mapping;
inode = mapping->host;
if (!count)
goto out; /* skip atime */
size = i_size_read(inode);
if (pos < size) {
retval = filemap_write_and_wait_range(mapping, pos,
pos + iov_length(iov, nr_segs) - 1);
if (!retval) {
retval = mapping->a_ops->direct_IO(READ, iocb,
iov, pos, nr_segs);
}
if (retval > 0)
*ppos = pos + retval;
if (retval) {
file_accessed(filp);
goto out;
}
}
当设置了这个标志时,表示读操作是直接I/O,其可以绕过页缓冲,是某些设备非常有用的特性。大多数的文件I/O把我们的访问路径视为页缓冲,它的效率很高。所以我们来看另一条路,即走页缓冲的那一条路
for (seg = 0; seg < nr_segs; seg++) {
read_descriptor_t desc;
//将iovec结构转换成read_descriptor_t的结构
desc.written = 0;
desc.arg.buf = iov[seg].iov_base;
desc.count = iov[seg].iov_len;
if (desc.count == 0)
continue;
desc.error = 0;
do_generic_file_read(filp, ppos, &desc, file_read_actor);
retval += desc.written;
if (desc.error) {
retval = retval ?: desc.error;
break;
}
if (desc.count > 0)
break;
}
out:
return retval;
1.首先将iovec结构体转换成read_descriptor_t的结构体,read_descriptor_t结构体记录读的状态
typedef struct {
size_t written; //存放不断变换着的已传送的字节数
size_t count; //存放不断变化着的未传送的字节数
union {
char __user *buf; //缓冲区的当前位置
void *data;
} arg;
int error; //读操作期间遇到的任何的错误码
} read_descriptor_t;
初始化完read_descriptor_t之后,进入read的内部do_generic_file_read()函数,由上面的代码可知,do_generic_read函数执行完毕之后,会计算一系列的已读字节数,最后返回给上层调用。
2.追踪页缓存
2.1.do_generic_file_read函数
static void do_generic_file_read(struct file *filp, loff_t *ppos,
read_descriptor_t *desc, read_actor_t actor)
{
struct address_space *mapping = filp->f_mapping; //获取页高速缓存
struct inode *inode = mapping->host;//获取inode
struct file_ra_state *ra = &filp->f_ra;
pgoff_t index;
pgoff_t last_index;
pgoff_t prev_index;
unsigned long offset; /* offset into pagecache page */
unsigned int prev_offset;
int error
. ............................
.............................
在这个函数中首先通过 filp->f_mapping去获取address_space,filp->f_ra是一个存放文件预读状态地址的结构。所以就把文件的读取转换成了对页缓冲的读取。
index = *ppos >> PAGE_CACHE_SHIFT; //确定本次读取的是文件中的第几个页
prev_index = ra->prev_pos >> PAGE_CACHE_SHIFT; //上次读取的是第几个页,即原来预读保存了上次的位置
prev_offset = ra->prev_pos & (PAGE_CACHE_SIZE-1);
last_index = (*ppos + desc->count + PAGE_CACHE_SIZE-1) >> PAGE_CACHE_SHIFT; //下次读操作完成后的位置
offset = *ppos & ~PAGE_CACHE_MASK; //请求的第一个字节在页内的偏移量
index为对应页缓存中的页号,而offset是对应的页内偏移,接下来就是在address_space中根据index的页号,找对应的页。
for (;;) {
struct page *page;
pgoff_t end_index;
loff_t isize;
unsigned long nr, ret;
cond_resched();
find_page:
page = find_get_page(mapping, index);
if (!page) {
page_cache_sync_readahead(mapping,
ra, filp,
index, last_index - index);
page = find_get_page(mapping, index);
if (unlikely(page == NULL))
goto no_cached_page;
}
if (PageReadahead(page)) {
page_cache_async_readahead(mapping,
ra, filp, page,
index, last_index - index);
}
if (!PageUptodate(page)) {
if (inode->i_blkbits == PAGE_CACHE_SHIFT ||
!mapping->a_ops->is_partially_uptodate)
goto page_not_up_to_date;
if (!trylock_page(page))
goto page_not_up_to_date;
if (!mapping->a_ops->is_partially_uptodate(page,
desc, offset))
goto page_not_up_to_date_locked;
unlock_page(page);
}
find_get_page()使用地址空间的基树查找索引为index的页。尝试去找到第一个被请求的页。如果这个页不在页缓存中,就跳转到标号no_cached_page处,如果该页不是最新的,就跳转到标号page_not_up_to_date_locked处,如果在尝试去获取这个页面的独占权,即加锁的时候,没有获取成功,则跳转到page_not_up_to_date处。
page_ok: //表示页已经在页高速缓存中了
isize = i_size_read(inode); //对应的文件的大小
end_index = (isize - 1) >> PAGE_CACHE_SHIFT; //最后的页缓存序号
if (unlikely(!isize || index > end_index)) {
page_cache_release(page);
goto out;
}
/* nr is the maximum number of bytes to copy from this page */
nr = PAGE_CACHE_SIZE;
if (index == end_index) {
nr = ((isize - 1) & ~PAGE_CACHE_MASK) + 1;
if (nr <= offset) {
page_cache_release(page);
goto out;
}
}
nr = nr - offset;
.............
//对index和offset进行处理,目的是选择下一个要获取的页。
ret = actor(desc, page, offset, nr);
offset += ret;
index += offset >> PAGE_CACHE_SHIFT;
offset &= ~PAGE_CACHE_MASK;
prev_offset = offset;
page_cache_release(page); //释放这个页,数据已经从内核态拷贝到了用户空间,
if (ret == nr && desc->count)//nr表示需要拷贝的字节数,如果没有拷贝完成,continue
continue;
goto out;
当页面不在缓冲区中时,就要从文件系统中获取数据
page_not_up_to_date_locked:
/* Did it get truncated before we got the lock? */
//有可能在锁页面的时候`有其它的进程将页面移除了页缓存区
//在这种情况下:将page解锁`并减少它的使用计数,重新循环```
//重新进入循环后,在页缓存区找不到对应的page.就会重新分配一个新的page
if (!page->mapping) {
unlock_page(page);
page_cache_release(page);
continue;
}
/* Did somebody else fill it already? */
//在加锁的时候,有其它的进程完成了从文件系统到具体页面的映射?
//在这种情况下,返回到page_ok.直接将页面上的内容copy到用户空间即可
if (PageUptodate(page)) {
unlock_page(page);
goto page_ok;
}
当该页不是最新的时候,就再检查一次;如果该页现在是最新的,就立刻返回给标号page_ok处,(注释中解释了原因)否则,将去获取该页的独占访问;这将有可能导致睡眠,知道获得对该页的独占访问。获的页的访问权限后,来看看这个页是否企图从页缓存中删除自己。(另一个进程可能会删除它),如果是,再返回到for循环顶部前赶紧继续向前。如果依然存在并且现在是最新的,就对页解锁并跳转到标号page_ok处。接下来就要真正的开始读取页面了
readpage:
/* Start the actual read. The read will unlock the page. */
error = mapping->a_ops->readpage(filp, page); //调用具体的readpage函数,在后面会分析。
if (unlikely(error)) { //如果发生了AOP_TRUNCATED_PAGE错误,则回到find_page重新进行获取
if (error == AOP_TRUNCATED_PAGE) {
page_cache_release(page);
goto find_page;
}
goto readpage_error;
}
//如果PG_uptodata标志仍然末设置.就一直等待,一直到page不处于锁定状态
// 在将文件系统的内容读入page之前,page一直是处理Lock状态的。一直到
//读取完成后,才会将页面解锁
if (!PageUptodate(page)) {
error = lock_page_killable(page);
if (unlikely(error))
goto readpage_error;
if (!PageUptodate(page)) {
if (page->mapping == NULL) {
/*
* invalidate_inode_pages got it
*/
unlock_page(page);
page_cache_release(page);
goto find_page;
}
unlock_page(page);
shrink_readahead_size_eio(filp, ra);
error = -EIO;
goto readpage_error;
}
unlock_page(page);
}
goto page_ok; //读取成功
在这里调用实际的读page的操作mpping->a_ops->readpage()对该页进行读取。如果成功读取了一个页,检查其是否是最新的,如果是最新的,则跳转到标号page_ok处。如果发生了同步读错误,就设置其error,并跳转到readpage_error处。
no_cached_page:
/*
* Ok, it wasn't cached, so we need to create a new
* page..
*/
//新分匹一个页面
page = page_cache_alloc_cold(mapping);
if (!page) {
desc->error = -ENOMEM;
goto out;
}
//将分得的页加到页缓存区和LRU
error = add_to_page_cache_lru(page, mapping,
index, GFP_KERNEL);
//向缓存中添加页时,如果因为页已经存在而产生错误,就跳转到find_Page处再试一次
if (error) {
page_cache_release(page);
if (error == -EEXIST)
goto find_page;
desc->error = error;//如果不是已经存在的错误,而是其他的错误,则记录该错误,并跳出for循环
goto out;
}
goto readpage;//当成功的分配页,并将页加入页缓存和LRU后,就让指针page指向新页,并挑战到readpage,开始读取。
}
这里主要讲述了当没有改页时时如何处理的。最后我们来看下do_generic_file_read函数的out
out:
ra->prev_pos = prev_index;
ra->prev_pos <<= PAGE_CACHE_SHIFT;
ra->prev_pos |= prev_offset;
*ppos = ((loff_t)index << PAGE_CACHE_SHIFT) + offset; //计算实际的偏移量
file_accessed(filp);//更新文件的最后一次访问时间。
}
这个函数终于分析完了,它描述了页缓存的核心,这使得Linux内核不用考虑底层文件系统的结构,用页缓存就可以缓存各种各样的页。一次,页缓存能够同时容纳来自MINX,EXT2等的页。
3.readpage()函数
页缓存维护着文件系统层之间的差异,每个特定的文件系统都需要维护自己的readpage函数,对于ext2文件系统而言
const struct address_space_operations ext2_aops = {
.readpage = ext2_readpage,
.readpages = ext2_readpages,
.writepage = ext2_writepage,
.sync_page = block_sync_page,
.write_begin = ext2_write_begin,
.write_end = generic_write_end,
.bmap = ext2_bmap,
.direct_IO = ext2_direct_IO,
.writepages = ext2_writepages,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
};
在ext2_readpage函数中。调用mpage_readpage()
static int ext2_readpage(struct file *file, struct page *page)
{
return mpage_readpage(page, ext2_get_block);
}
这个函数的第二个参数是一个回调函数ext2_get_block(),这个函数将文件起始的块号转换成文件系统的逻辑块号,在这里要介绍一个结构体struct bio
struct bio {
sector_t bi_sector;//该bio结构所要传输的第一个(512字节)扇区:磁盘的位置
struct bio *bi_next; //请求链表
struct block_device *bi_bdev;//相关的块设备
unsigned long bi_flags//状态和命令标志
unsigned long bi_rw; //读写
unsigned short bi_vcnt;//bio_vesc偏移的个数
unsigned short bi_idx; //bi_io_vec的当前索引
unsigned short bi_phys_segments;//结合后的片段数目
unsigned short bi_hw_segments;//重映射后的片段数目
unsigned int bi_size; //I/O计数
unsigned int bi_hw_front_size;//第一个可合并的段大小;
unsigned int bi_hw_back_size;//最后一个可合并的段大小
unsigned int bi_max_vecs; //bio_vecs数目上限
struct bio_vec *bi_io_vec; //bio_vec链表:内存的位置
bio_end_io_t *bi_end_io;//I/O完成方法
atomic_t bi_cnt; //使用计数
void *bi_private; //拥有者的私有方法
bio_destructor_t *bi_destructor; //销毁方法
};
对于这个结构体理解还不够,其大概的意思就是bio结构记录着与块I/O相关的信息,既描述了磁盘的位置,又描述了内存的位置,是上层内核与下层驱动的连接纽带,故当上层内核与下层的驱动层连接时,这个bio结构体就显得很重要了。
int mpage_readpage(struct page *page, get_block_t get_block)
{
struct bio *bio = NULL;
sector_t last_block_in_bio = 0;
struct buffer_head map_bh;
unsigned long first_logical_block = 0;
map_bh.b_state = 0;
map_bh.b_size = 0;
bio = do_mpage_readpage(bio, page, 1, &last_block_in_bio,
&map_bh, &first_logical_block, get_block);
if (bio)
mpage_bio_submit(READ, bio);
return 0;
}
do_mpage_readpage()函数完成的主要工作就是将address_space的逻辑页转换成由实际的页和块组成的bio结构体,bio结构记录着与块相关的信息。最后将新创建的bio发送给mpage_bio_submit()函数。
4.讲到这里是时候对读操作做个总结了
1.从open返回的文件描述符,得到索引节点。
2.文件系统层在内存的页缓存中检查和给定索引节点对应的一个或多个页。
3.如果没有找到所需的页,文件系统层使用特定文件系统的驱动程序把所请求的文件转换成特定设备上的I/O块。
4.在页缓存的address_space中为页分配空间,通过struct bio,把新分配的页与块设备上的扇区对应起来。
通过上面的mpage_readpage只是把bio结构建立起来,此时页中还是没有数据的。这时,文件系统层需要块设备的驱动程序来完成到设备的实际接口。这时由mpage_bio_submit()中的submit_bio()函数来完成的。(对于后面的还没有仔细去看,还需要仔细去研究)