1.工作队列
工作队列是另外一种将工作推后执行的形式,它和前面的软中断以及tasklet都不相同,工作队列可以把工作推后,交由一个内核线程去执行这个下半部,但是由于是内核线程,其不能访问用户空间,最重要特点是工作队列允许重新调度甚至是睡眠。
通常,在工作队列,软中断,tasklet中做出选择非常容易,可以使用以下规则:
- 如果推后执行的任务需要睡眠,那么只能选择工作队列。
- 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时。
- 如果推后执行的任务需要在一个tick之内处理,则使用软中断或者tasklet,因为其可以抢占普通进程和内核线程。
- 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。
2.工作队列的实现
工作队列可以让你的驱动程序创建一个专门的工作者线程来处理需要推后的工作。因此,工作队列最基本的表现形式,就转变成了一个把需要推后执行的任务交给特定的通用线程的这样一种接口。
2.1.表示工作线程的数据结构
struct workqueue_struct {
struct cpu_workqueue_struct *cpu_wq;
struct list_head list;
const char *name;
int singlethread;
int freezeable; /* Freeze threads during suspend */
int rt;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
该结构是一个链表,有表示该工作线程名字的name字段,其中cpu_woekqueue_struct结构体组成的数组,它定义在kernel/woekqueue.c中,数组的每一项对应系统中的一个处理器。由于系统中每个处理器对应一个工作者线程,所以每个工作者线程对应一个这样的cpu_workqueue_struct结构体。cpu_workqueue_struct是其核心数据结构
struct cpu_workqueue_struct {
spinlock_t lock; //锁保护这种结构
struct list_head worklist; //工作列表
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq; //关联工作队列结构
struct task_struct *thread; //关联线程
} ____cacheline_aligned;
注意,每个工作者线程类型关联一个自己的workqueue_struct.在该结构体里面,给每个线程分配一个cpu_workqueue_struct, 因而也就是给每个处理器分配一个,因为每个处理器都有一个该类型的工作者线程。
2.2.表示工作的数据结构
struct work_struct {
atomic_long_t data;
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)
struct list_head entry;
work_func_t func;
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
data表示传递给处理函数的参数, func表示该工作队列的处理函数。这些结构体被连接成链表,在每个处理器上的每种类型的队列都对应这样一个链表。当一个工作者线程被唤醒的时候,它会执行它的链表上的所有工作。工作被执行完毕,它就将相应的work_struct对象从链表上移去。当链表上不再有对象的时候,它就会继续休眠。
2.3.数据够之间的关系
这些数据结构之间的关系确实让人觉得混乱,难以理清,下面给出图:
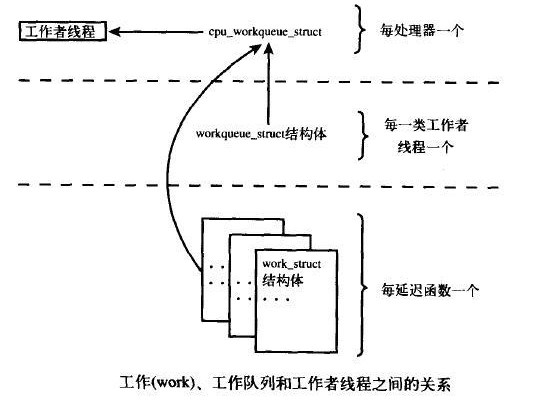
位于最高一层的是工作队列。系统允许有多种类型的工作队列存在。每一个工作队列具备一个workqueue_struct,而SMP机器上每个CPU都具备一个该类的工作者线程cpu_workqueue_struct,系统通过CPU号和workqueue_struct 的链表指针及第一个成员cpu_wq可以得到每个CPU的cpu_workqueue_struct结构。
而每个工作提交时,将链接在当前CPU的cpu_workqueue_struct结构的worklist链表中。通常情况下由当前所注册的CPU执行此工作,但在flush_work中可能由其他CPU来执行。或者CPU热插拔后也将进行工作的转移。
内核中有些部分可以根据需要来创建工作队列。而在默认情况下内核只有events这一种类型的工作队列。大部分驱动程序都使用的是现存的默认工作者线程。它们使用起来简单、方便。可是,在有些要求更严格的情况下,驱动程序需要自己的工作者线程。
3.工作队列的执行流程
所有工作者线程都是用普通的内核线程实现的,它们都要执行worker_thread函数,在它初始化完成之后,这个函数开始休眠,当有操作被插入到队列的时候,线程就会被唤醒,以便执行这些操作。当没有剩余的操作时,它又会继续睡眠。
以下为工作者线程的标准模板,所以工作者线程都使用此函数,对于用户自定义的内核线程可以参考次函数。
static int worker_thread(void *__cwq)
{
struct cpu_workqueue_struct *cwq = __cwq; //与工作者线程关联的cpu_workqueue_struct
DEFINE_WAIT(wait);
if (cwq->wq->freezeable)
set_freezable();
for (;;) {
prepare_to_wait(&cwq->more_work, &wait, TASK_INTERRUPTIBLE);
if (!freezing(current) &&
!kthread_should_stop() &&
list_empty(&cwq->worklist))
schedule();
finish_wait(&cwq->more_work, &wait);
try_to_freeze();
if (kthread_should_stop())
break;
run_workqueue(cwq);
}
return 0;
}
该函数在死循环中完成了以下的功能:
- 线程将自己设置为休眠状态(state被设置为 TASK_INTERRUPTIBLE),并把自己加入到等待队列中。
- 如果工作链表中有对象,线程不会睡眠,相反,将自己设置成TASK_RUNNING,脱离等待队列。
- 如果链表非空,调用run_woekqueue()函数执行被推后的工作。
static void run_workqueue(struct cpu_workqueue_struct *cwq)
{
spin_lock_irq(&cwq->lock);/*加上自旋锁*/
while (!list_empty(&cwq->worklist)) {/*当不为空的时候执行循环*/
struct work_struct *work = list_entry(cwq->worklist.next,
struct work_struct, entry);
work_func_t f = work->func;/*获取大执行函数*/
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map = work->lockdep_map;
#endif
trace_workqueue_execution(cwq->thread, work);
cwq->current_work = work;/*设置当前的工作*/
list_del_init(cwq->worklist.next);/*删除链表中的元素*/
spin_unlock_irq(&cwq->lock);/*接触自旋锁*/
BUG_ON(get_wq_data(work) != cwq);
work_clear_pending(work);/*移除pending*/
lock_map_acquire(&cwq->wq->lockdep_map);
lock_map_acquire(&lockdep_map);
f(work); /*执行相应的work函数*/
lock_map_release(&lockdep_map);
lock_map_release(&cwq->wq->lockdep_map);
if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {
printk(KERN_ERR "BUG: workqueue leaked lock or atomic: "
"%s/0x%08x/%d
",
current->comm, preempt_count(),
task_pid_nr(current));
printk(KERN_ERR " last function: ");
print_symbol("%s
", (unsigned long)f);
debug_show_held_locks(current);
dump_stack();
}
spin_lock_irq(&cwq->lock);
cwq->current_work = NULL;/*把当前任务设置为NUll*/
}
spin_unlock_irq(&cwq->lock);/*解锁*/
可以看出这个函数的主要功能是循环遍历链表上每个待处理的工作,执行链表每个节点上的work_struct上的func函数
4.使用工作队列
4.1.创建一个工作队列
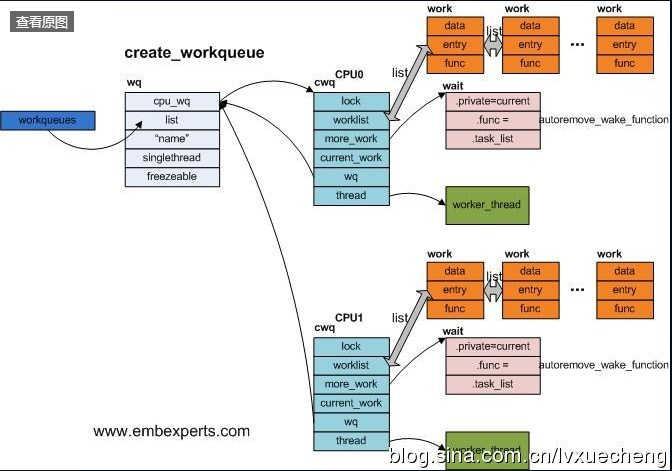
创建工作队列使用宏create_workqueue,但create_workqueue宏只是另一个函数的快捷调用,初始化了一些参数而已,最终会使用__create_workqueue。
注:也可以不自己创建工作队列,使用系统缺省得events任务队列
#define create_workqueue(name) __create_workqueue((name), 0, 0, 0)
#define create_rt_workqueue(name) __create_workqueue((name), 0, 0, 1)
#define create_freezeable_workqueue(name) __create_workqueue((name), 1, 1, 0)
#define create_singlethread_workqueue(name) __create_workqueue((name), 1, 0, 0)
我们可以看到大多数的创建工作队列的函数最终都是使用同一个函数,只是参数不同而已。创建工作队列的函数接收一个字符串作为参数,返回新创建工作队列的workqueue_struct描述符地址。
对于创建工作队列的核心代码逻辑,我们可以看如下代码:
struct workqueue_struct *__create_workqueue_key(const char *name,
int singlethread,
int freezeable,
int rt,
struct lock_class_key *key,
const char *lock_name)
{
struct workqueue_struct *wq;
struct cpu_workqueue_struct *cwq;
int err = 0, cpu;
//初始化申请工作队列的内存
wq = kzalloc(sizeof(*wq), GFP_KERNEL);
if (!wq)
return NULL;
wq->cpu_wq = alloc_percpu(struct cpu_workqueue_struct);
if (!wq->cpu_wq) {
kfree(wq);
return NULL;
}
//把 name设置为工作队列的名字
wq->name = name;
lockdep_init_map(&wq->lockdep_map, lock_name, key, 0);
wq->singlethread = singlethread;
wq->freezeable = freezeable;
wq->rt = rt;
//初始化链表头
INIT_LIST_HEAD(&wq->list);
//用于创建单个工作线程
if (singlethread) {
cwq = init_cpu_workqueue(wq, singlethread_cpu);
err = create_workqueue_thread(cwq, singlethread_cpu);
start_workqueue_thread(cwq, -1);
} else {
cpu_maps_update_begin();
spin_lock(&workqueue_lock);
list_add(&wq->list, &workqueues);//将队列插入到链表头
spin_unlock(&workqueue_lock);
for_each_possible_cpu(cpu) {//为每个cpu创建一个工作者线程
cwq = init_cpu_workqueue(wq, cpu);
if (err || !cpu_online(cpu))
continue;
err = create_workqueue_thread(cwq, cpu);
start_workqueue_thread(cwq, cpu);
}
cpu_maps_update_done();
}
if (err) {
destroy_workqueue(wq);
wq = NULL;
}
return wq;
}
其完成的工作可以用一副图表示:
4.2.INIT_WORK
接着需要使用INIT_WERK宏将工作队列处理函数填充到任务结构体中
INIT_WORK( (struct work_struct *)work, my_wq_function );//填充结构体的过程
接着需要使用queue_work()函数把函数插入到工作队列中,它接收wq和work两个指针。
int queue_work(struct workqueue_struct *wq, struct work_struct *work)
{
int ret;
ret = queue_work_on(get_cpu(), wq, work);//检查要插入的函数是否已经在工作队列中。
put_cpu();
return ret;
}
还有一个函数是queue_delayed_work()函数,该函数和queue_work()函数相同,只是queue_delayed_work()函数多了一个以系统滴大数delay来表示时间延迟的参数。
int queue_delayed_work(struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay)
{
if (delay == 0)
return queue_work(wq, &dwork->work);
return queue_delayed_work_on(-1, wq, dwork, delay);
}
实际上queue_delayed_work依靠软定时器把work_struct描述符插入工作队列链表的实际操作向后推迟了。可以看到,如果delay为0,那么就执行queue_work()函数,否则就执行queue_delayed_work_on()函数。
4.3.删除工作队列
排入队列的工作会在工作者线程下一次被唤醒的时候执行,有时,在继续下一步工作之前,你必须保证一些操作被执行完毕了。比如,在卸载之前,需要等待工作队列的函数执行完毕,这就需要使用刷新函数flush_scheduled_work(void)函数,这个函数会一直等待,直到队列中的所有把对象被执行以后返回。该函数并不取消任何延迟执行的工作。取消工作的函数为destroy_workqueue函数
void destroy_workqueue(struct workqueue_struct *wq)
{
const struct cpumask *cpu_map = wq_cpu_map(wq); //删除工作者线程
int cpu;
cpu_maps_update_begin();
spin_lock(&workqueue_lock);
list_del(&wq->list);
spin_unlock(&workqueue_lock);
for_each_cpu(cpu, cpu_map)
cleanup_workqueue_thread(per_cpu_ptr(wq->cpu_wq, cpu));
cpu_maps_update_done();
free_percpu(wq->cpu_wq);
kfree(wq);
}
5.写一个自己的工作队列
#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/workqueue.h>
MODULE_LICENSE("GPL");
static struct workqueue_struct *my_wq;
typedef struct {
struct work_struct my_work;
int x;
} my_work_t;
my_work_t *work, *work2;
static void my_wq_function( struct work_struct *work)
{
my_work_t *my_work = (my_work_t *)work;
printk( "my_work.x %d
", my_work->x );
kfree( (void *)work );
}
int init_module( void )
{
int ret;
// system default work thread function worker_thread()
my_wq = create_workqueue("my_queue");//创建一个工作队列
if (my_wq) {
/* Queue some work (item 1) */
work = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work) {
INIT_WORK( (struct work_struct *)work, my_wq_function );//填充结构体的过程
work->x = 1;
ret = queue_work( my_wq, (struct work_struct *)work );
}
/* Queue some additional work (item 2) */
work2 = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (work2) {
INIT_WORK( (struct work_struct *)work2, my_wq_function );
work2->x = 2;
ret = queue_work( my_wq, (struct work_struct *)work2 );
}
}
return 0;
}
void cleanup_module( void )
{
flush_workqueue( my_wq );
destroy_workqueue( my_wq );
}
MODULE_AUTHOR("wangzhangjun.com");
MODULE_DESCRIPTION (" work queue of buttom half test");
MODULE_LICENSE ("GPL v2");