——王宇阳—根据mooc课程总结记录笔记(Code_boy)
Requests库:自动爬去HTML页面、自动网络请求提交
robots.txt:网络爬虫排除标准
Beautiful Soup库:解析HTML页面(pycharm中安装bs4即可)
re正则表达式:对HTML数据分析选择
requests.get(url[,params = None,**kwargs])
url:获取网页的url链接
params:url中的额外参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数
Response对象的属性{0.0.py}
|
属性 |
说明 |
|
r.status_code |
HTTP请求的返回状态,200表示连接成功,404表示失败 |
|
r.text |
HTTP响应内容的字符串形式,(即:url对应的页面内容) |
|
r.encoding |
从HTTP header中猜测的响应内容编码方式 |
|
r.apparent_encoding |
从内容中分析出的响应内容编码方式(备选编码方式) |
|
r.content |
HTTP响应内容的二进制形式 |
实例:
1 r = requests.get("http://www.baidu.com") 2 print(r.status_code) #返回状态码(内容值为‘200’表示访问成功) 3 #结果: 200 4 print(r.text) #返回响应内容的字符串形式 5 #结果:【即-baidu主页的源代码内容(存在乱码字符)】 6 print(r.encoding) #从HTTP header中猜测的响应内容编码方式 7 #结果: ISO-8859-1 即baidu页面的编码标准(方式 ) 8 print(r.apparent_encoding) #从内容中分析出的响应内容编码方式[备选编码方式] 9 #结果: utf-8 10 print(r.content) #内容的二进制形式 11 #结果: 总之看不懂 12 13 r.encoding = 'utf-8' #(utf-8为r.apparent_encoding得到的结果) 14 print(r.text) 15 #结果就为人可看懂的响应内容 主要是通过r.encoding的重新定义类型,而r.text是参照encoding的编码方式
通用爬虫代码框架:
1 def getHTMLText(url): 2 try: 3 r = requests.get(url,timeout = 30) 4 r.raise_for_status() #如果状态不是200 则抛出异常:requests.HTTPError(r.status_code) 5 r.encoding = r.apparent_encoding 6 return r.text 7 except: 8 return "产生异常" 9 10 if __name__ == "__main__": 11 url = 'http://www.baidu.com' 12 print(getHTMLText(url))
Requests库的异常
|
异常 |
说明 |
|
requests.ConnectionError |
网络连接错误异常,(如DNS查询失败,拒绝连接等) |
|
requests.HTTPError |
HTTP错误异常 |
|
requests.URLequired |
URL缺失异常 |
|
requests.TooManyRedirects |
超过最大重定向次数,产生重定向异常 |
|
requests.ConnectTimeout |
连接远程服务器超时异常 |
|
requests.Timeeout |
请求URL超时,产生超时异常 |
|
r.raise_for_status |
如果不是200,产生异常: requetst.HTTPError |
通用代码框架实例:
1 def getHTMLText(url): 2 try: 3 r = requests.get(url,timeout = 30) 4 r.raise_for_status() #如果状态不是200 则抛出异常:requests.HTTPError(r.status_code) 5 r.encoding = r.apparent_encoding 6 return r.text 7 except: 8 return "产生异常" 9 10 if __name__ == "__main__": 11 url = 'http://www.baidu.com' 12 print(getHTMLText(url))
Requests库的7个主要方法
|
方法 |
说明 |
|
requests.request() |
构造一个请求,支撑以下的各方法的基础方法 |
|
requests.get() |
获取HTML网页的只要方法,对应于HTTP的GET |
|
requests.head() |
获取HTML网页头信息的方法,对应于HTTP的HEAD |
|
requests.post() |
向HTML网页提交POST请求的方法,对应于HTTP的POST |
|
requests.put() |
向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
|
requests.patch() |
向HTML网页提交局部修改请求,对应于HTTP的PATCH |
|
requests.delete() |
向HTML网页提交删除请求,对应于HTTP的DELETE |
HTTP协议:
HTTP,Hypertext Transfer Protocol,超文本传输协议
HTTP是一个基于“请求与响应”模式的、无状态的应用层协议。
HTTP采用URL定位网络资源的标识
URL格式: http://host[:port][path]
host:合法的Internet主机域名或IP地址
port:端口号(缺省端口为80)
path:请求资源的路径
HTTP协议对资源的操作:
|
方法 |
说明 |
|
GET |
请求获取URL位置的资源 |
|
HEAD |
请求获取URL位置资源的响应信息报告,即获得该资源的头部信息 |
|
POST |
请求向URL位置的资源后附加新的数据 |
|
PUT |
请求向URL位置存储一个资源,覆盖原URL位置的资源 |
|
PATCH |
请求局部更新URL位置的资源,即改变该出资源的部分内容 |
|
DELETE |
请求删除URL位置存储的资源 |
理解PATCH和PUT的区别
假设URL位置有一组数据UserInfo,包括UserID、UserName等20个字段
需求:用户修改了UserName,其他不变
*采用PATCH,仅向URL提交UserName的局部更新请求【追加】
*采用PUT,必须将所有20个字段一并提交到URL,未提交字段被删除【覆盖追加】
1 #requests库的head()方法 (请求获取URL位置资源的响应信息报告,即获得该资源的头部信息) 2 r = requests.head('http://httpbin.org/get') 3 print(r.headers) 4 ''' 5 结果: 6 {'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 7 'Date': 'Thu, 22 Nov 2018 03:52:22 GMT', 'Content-Type': 8 'application/json', 'Content-Length': '268', 9 'Access-Control-Allow-Origin': '*', 10 'Access-Control-Allow-Credentials': 'true', 'Via': '1.1 vegur'} 11 ''' 12 #requests库的post()方法(请求向URL位置的资源后附加新的数据) 13 payload = {'key1':'value1','key2':'value2'} 14 r = requests.post('http://httpbin.org/post',data = payload) 15 #向URL POST一个字典,自动编码未form(表单) 16 print(r.text) 17 ''' 18 结果: 19 { 20 "args": {}, 21 "data": "", 22 "files": {}, 23 "form": { 24 "key1": "value1", 25 "key2": "value2" 26 }, 27 "headers": { 28 "Accept": "*/*", 29 "Accept-Encoding": "gzip, deflate", 30 "Connection": "close", 31 "Content-Length": "23", 32 "Content-Type": "application/x-www-form-urlencoded", 33 "Host": "httpbin.org", 34 "User-Agent": "python-requests/2.20.1" 35 }, 36 "json": null, 37 "origin": "106.111.147.213", 38 "url": "http://httpbin.org/post" 39 } 40 ''' 41 r = requests.post('http://httpbin.org/post',data = 'abc') 42 #向URL POST一个字符串自动编码为 data 43 print(r.text) 44 ''' 45 结果: 46 { 47 "args": {}, 48 "data": "abc", 49 "files": {}, 50 "form": {}, 51 "headers": { 52 "Accept": "*/*", 53 "Accept-Encoding": "gzip, deflate", 54 "Connection": "close", 55 "Content-Length": "3", 56 "Host": "httpbin.org", 57 "User-Agent": "python-requests/2.20.1" 58 }, 59 "json": null, 60 "origin": "106.111.147.213", 61 "url": "http://httpbin.org/post" 62 } 63 ''' 64 #requests库的put()方法 (请求向URL位置存储一个资源,覆盖原URL位置的资源) 65 payload = {'key1':'value1','key2':'value2'} 66 r = requests.put('http://httpbin.org/put',data = payload) 67 #向URL PUT一个字典,自动编码未form(表单)[和post的区别是会覆盖原有内容] 68 print(r.text) 69 ''' 70 结果: 71 { 72 "args": {}, 73 "data": "", 74 "files": {}, 75 "form": { 76 "key1": "value1", 77 "key2": "value2" 78 }, 79 "headers": { 80 "Accept": "*/*", 81 "Accept-Encoding": "gzip, deflate", 82 "Connection": "close", 83 "Content-Length": "23", 84 "Content-Type": "application/x-www-form-urlencoded", 85 "Host": "httpbin.org", 86 "User-Agent": "python-requests/2.20.1" 87 }, 88 "json": null, 89 "origin": "106.111.147.213", 90 "url": "http://httpbin.org/put" 91 } 92 '''
requests库的方法功能及使用:
requests.request(method,url,**kwargs)
method:请求方法,对应get/put/post等7种方法
r = requests.request(‘GET’,url,**kwargs)
r = requests.request(‘HEAD,’url,**kwargs)
r = requests.request(‘POST’,url,**kwargs)
r = requests.request(‘PUT’,url,**kwargs)
r = requests.request(‘PATCH’,url,**kwargs)
r = requests.request(‘delete’,url,**kwargs)
r = requests.request(‘OPTIONS’,url,**kwargs)#向服务获取相关的参数
url:拟获取页面的url链接
**kwargs:控制访问的参数,共13个(可选)
params:字典或字节序列,作为参数增加到url中(链接部分系统会添加一个‘?’)
data:字典、字节序列或文件对象,作为Request的内容
json:json格式的数据,作为Request的内容
headers:字典,HTTP定制头
cookies:字典或CookieJar,Request中的cookie *
auth:元组,支持HTTP认证功能 *
files:字典类型,传输文件
timeout:设定超时时间,单位:秒(时间内为返回,则返回异常)
proxies:字典类型,设定访问代理服务器,可以增加登陆认证
pxs={'http':'http://user:pass@10.10.10.1:1234'}
r = requests.request('GET','http://www.baidu.com',proxies = pxs)
allow_redirects:True/False,默认为True,重定向开关
stream:True/False,默认为True,获取内容立即下载开关
verify:True/False,默认为True,认证SSL证书开关
cert:本地SSL证书路径
requests.get(url,params=None,**kwargs)*
url:页面的url链接
params:url中额外的参数,字典或字节流格式,可选
**kwargs:12个控制访问的参数
requests.head(url,**kwargs)
url:页面的url链接
**kwargs:13个控制访问的参数
requests.post(url,data=None,json=None,**kwargs)
url:页面的url链接
data:字典、字节序列或文件,Request的内容
json:JSON格式的数据,Request的内容
**kwargs:11个控制访问参数(data、json已使用)
requests.put(url,data=None,**kwargs)
url:页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问的参数
requests.patch(url,data=None,**kwargs)
url:页面的url链接
data:字典、字节序列或文件,Request的内容
**kwargs:12个控制访问的参数
requests.delete(url,**kwargs)
url:删除页面的url链接
**kwargs:13个控制访问的参数
网络爬虫的尺寸:
|
样式 |
爬取网页,玩转网页 |
爬取网站,爬取系列网站 |
爬取全网 |
|
规模 |
小规模,数据量小的,爬取速度不敏感(>=90%) |
中规模,数据规模较大,爬取速度敏感 |
大规模,搜索引擎,爬取速度关键 |
|
常用库 |
requests库 |
scrapy库 |
定制开发 |
网络爬虫的骚扰:
爬虫利用快速功能访问web服务器,服务器很难提供适应高速度爬虫的资源
受限于编写水平的目的,网络爬虫将会为web服务器带来巨大的资源开销
网络爬虫的法律风险:
服务器上的数据有产权归属
网络爬虫获取的数据后牟利将带来法律风险
网络爬虫==”爬亦有道”
限制爬虫条件:
>>>来源审查:判断 User-Agent 进行限制
·检查来访HTTP协议头的User-Agent域,只响应浏览器或友好爬虫的访问
>>>发布公告:Robots协议*
Robots Exclusion Standard 网络爬虫排除标准
作用:告知所有爬虫网站的爬取策略,要求爬虫遵守
形式:在网站根目录下的robots.txt文件
京东Robots协议:(https://www.jd.com/robots.txt)
|
User-agent: * Disallow: /?* Disallow: /pop/*.html Disallow: /pinpai/*.html?* User-agent: EtaoSpider Disallow: / User-agent: HuihuiSpider Disallow: / User-agent: GwdangSpider Disallow: / User-agent: WochachaSpider Disallow: / |
任何爬虫均应该遵守 不允许访问?开头的路径 不允许访问 /pop/*.html 不允许访问 /pinpai/*.html?* EtaoSpider, HuihuiSpider, GwdangSpider, WochachaSpider 被认定为恶意爬虫 被禁止爬取任何内容 |
Robots协议基本语法:
|
# |
注释 |
|
* |
代表所有 |
|
/ |
代表根目录 |
|
User-agent:* |
指定爬虫(*表示所有爬虫) |
|
Disallow:/ |
不允许爬虫访问的目录 |
爬虫基础1实例:(代码+总结){0.1.py}


1 #实例:爬取京东商品 2 import requests 3 import os 4 ''' 5 r = requests.get('https://item.jd.com/36826348085.html?jd_pop=14982c1c-64d9-4bab-ac5c-e40af7ce62a2&abt=0') 6 print(r.status_code) 7 print(r.encoding) 8 print(r.text[:1000]) 9 #实例:爬取亚马逊 10 11 kv = {'User-Agent':'mozilla/5.0'} #打造访问头(伪造成一个浏览器) 12 r=requests.get('https://www.amazon.cn/dp/B073LJR2JF/ref=cngwdyfloorv2_recs_0/459-8865541-1481366?pf_rd_m=A1AJ19PSB66TGU&pf_rd_s=desktop-2&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_r=AT12APC0BDJ216Y55VSR&pf_rd_t=36701&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_p=d2aa3428-dc2b-4cfe-bca6-5e3a33f2342e&pf_rd_i=desktop',headers=kv) 13 print(r.status_code) 14 print(r.text[:1000]) 15 print(r.request.headers) 16 ''' 17 #实例:百度搜索 18 #百度搜索的搜索url:http://www.baidu.com/s?wd:{搜索内容} 19 ''' 20 keyword = 'python' 21 try: 22 kv = {'wd':keyword} 23 r = requests.get('http://www.baidu.com/s',params = kv) 24 print(r.request.url) 25 r.raise_for_status() 26 print(len(r.text)) 27 except: 28 print("爬取失败") 29 ''' 30 #案例:网络图片爬取和存储 31 ''' 32 url = "http://img0.dili360.com/pic/2018/09/21/5ba4a6af2af103q29157813_t.jpg" 33 rot = "E://" 34 path = rot + url.split('/')[-1] #指定图片保存名为url地址中的后缀名(url) 35 try: 36 if not os.path.exists(rot): #查看有没有rot目录,没有则创建 37 os.mkdir(rot) #创建rot目录 38 if not os.path.exists(path): #查看path目录下有没有path文件 39 r = requests.get(url) #链接url地址 40 #with open(path,'wb') as f: #另一种文件打开和存储方式(???) 41 f = open(path,'wb') #打开文件 42 f.write(r.content) #r.content 响应url的二进制内容 43 f.close() 44 print("保存成功") 45 else: 46 print("文件已存在") 47 except: 48 print("爬取失败") 49 ''' 50 #爬单个视频 51 ''' 52 url = "http://video.pearvideo.com/mp4/adshort/20181121/cont-1480150-13269168_adpkg-ad_hd.mp4" 53 rot = "E://" 54 path = rot + url.split('/')[-1] #指定视频保存名为url地址中的后缀名(url) 55 try: 56 if not os.path.exists(rot): #查看有没有rot目录,没有则创建 57 os.mkdir(rot) #创建rot目录 58 if not os.path.exists(path): #查看path目录下有没有path文件 59 r = requests.get(url) #链接url地址 60 #with open(path,'wb') as f: #另一种文件打开和存储方式(???) 61 f = open(path,'wb') #打开文件 62 f.write(r.content) #r.content 响应url的二进制内容 63 f.close() 64 print("保存成功") 65 else: 66 print("文件已存在") 67 except: 68 print("爬取失败") 69 ''' 70 #IP地址归属地的自动查询 71 #IP168查询链接url:http://ip138.com/ips138.asp?ip=123.125.6.1&action=2 72 #由上得出:IP查询url:http://ip138.com/ips138.asp?ip=ip地址 73 74 url = "http://ip138.com/ips138.asp" 75 ip = {"ip":"106.111.147.213"} 76 try: 77 r = requests.get(url,params=ip) 78 r.raise_for_status() 79 print(r) 80 #print(r.status_code) 81 r.encoding = r.apparent_encoding 82 print(r.text) 83 except: 84 print("爬取失败")
小总结:
实例中可以看出,在搜索方便我们需要掌握url接口(会找、会用):中间利用到了params()函数来在url后添加新的内容,在调用该函数时最后url会在两者的结合处添加一个“?”符号
在网页爬取方面我们也看见了r.text[]的格式出现,这表示我们需要爬取网页源码的字符数;
实例中看见了图片和视频的爬取,并采用二进制的形式保存!
Beautiful Soup库:(pycharm中安装bs4){0.2 bs.py}
库的使用:
1 form bs4 import BeautifulSoup 2 3 soup = BeautifulSoup( ‘ <p>data</p> ‘ , ‘ html.parser ‘ )
Beautiful Soup库的理解:是解析、遍历、维护“标签树”的功能库
*Beautiful Soup库,也叫Beautiful Soup4或者bs4
目前常用的引用方法: for bs4 impor tBeautiful Soup
Beautiful Soup类 <<<等价>>> 标签树 <<<等价>>> HTML<>
因为形成等价,所以通过Beautiful Soup类使得标签树形成了一个变量;
简单比喻:Beautiful Soup对应HTML/XML文档的全部内容
Beautiful Soup库解析器:
|
解析器 |
使用方法 |
条件 |
|
bs4的HTML解析器 |
Beautiful Soup ( mk , ‘html.parser‘ ) |
安装bs4库 |
|
lxml的HTML解析器 |
Beautiful Soup ( mk , ‘lxml’ ) |
pip install lxml |
|
lxml的XML解析器 |
Beautiful Soup ( mk , ‘xml’ ) |
pip install lxml |
|
html5lib的解析器 |
Beautiful Soup ( mk , ‘html5lib’ ) |
pip install html5lib |
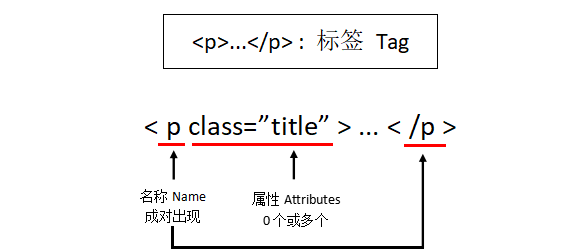
Beautiful Soup库的基本元素:
|
基本元素 |
说明 |
|
Tag |
标签,最基本的信息组织单元,分别用<>和</>标明开头和结尾 |
|
Name |
标签的名字,<p>...</p>的名字是‘p’,格式:<tag>.name |
|
Attributes |
标签的属性,字典形式组织,格式:<tag>.attrs |
|
NavigableString |
标签内非属性性字符串,<>...</>中字符串,格式:<tag>.string |
|
Comment |
标签内字符串的注释部分,一种特殊的Comment类型 |
Beautiful Soup库的函数:(表中的<tag>指标签)
|
函数 |
说明 |
备注 |
|
soup.<tag> |
获取已被解析过的网页中的标签 |
t=soup.<tag> |
|
[soup.<tag>].name |
获取<tag>标签的名称 |
|
|
[soup.<tag>].parent.name |
获取<tag>标签的上一层标签的名称 |
以此可向上类推 |
|
[soup.<tag>].attrs |
获取<tag>标签的属性 |
|
|
[soup.<tag>].string |
获取<tag>标签的非属性字符串/注释 |
|
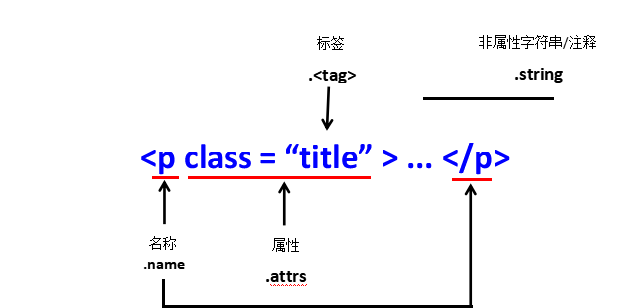
代码实例(+说明)
1 r = requests.get('http://python123.io/ws/demo.html') 2 print(r.text) 3 demo = r.text #demo == url网页代码 4 soup = BeautifulSoup(demo,'html.parser') 5 print(soup.prettify()) 6 r = requests.get('http://python123.io/ws/demo.html') 7 demo = r.text 8 soup = BeautifulSoup(demo,"html.parser") 9 print(soup.title) #查找 title 标签 10 print(soup.a.string) #打印a标签的字符串内容 11 print(soup.a.name) #打印a标签的名字 12 print(soup.a.parent.name) #打印a标签的父标签(上一层标签) 13 print(soup.a.parent.parent.name) #打印a标签的父标签的上一层标签 14 tag = soup.a #soup:查找标签a 15 print(soup.a.attrs) #打印标签的属性 16 print(tag.attrs['class']) #打印标签属性中的‘class’的内容 17 print(tag.attrs['href']) #打印标签属性中的‘href’的内容 18 print(tag) #打印a标签的内容
HTML遍历:
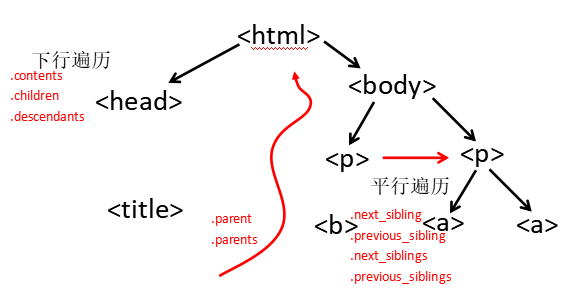
下行遍历:
|
属 性 |
说 明 |
|
.contents |
子节点的列表,将<tag>所有儿子节点存入列表 |
|
.children |
子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
|
.descendants |
子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url网页代码 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.head) #获取head标签 5 print(soup.head.contents) #返回形式是列表,list形式检索head, 6 print(soup.body.contents) #获得body标签的儿子节点(返回形式是list) 7 print(len(soup.body.contents)) #利用len测试body标签的节点总数 8 print(soup.body.contents[1]) #list形式返回,用list方式查看其中的一个节点 9 #遍历儿子节点 10 for child in soup.body.children: 11 print(child) 12 #遍历子孙节点 13 for child in soup.body.descendants: 14 print(child) |
|
上行遍历:
|
属性 |
说明 |
|
.parent |
节点的父亲标签 |
|
.parents |
节点先辈标签的迭代类型,用于循环遍历先辈节点 |
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url网页代码 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.title.parent) #title标签节点的父辈 >>> <head>标签 5 #上行遍历 6 for parent in soup.a.parents: #从a标签向上遍历父辈 7 if parent is None: 8 print(parent) #先辈如果没有则执行 9 else: 10 print(parent.name) #打印先辈的标签名称 |
|
平行遍历:
|
属性 |
说明 |
|
.next_sibling |
返回按照HTML文本顺序的下一个平行节点标签 |
|
.previous_sibling |
返回按照HTML文本顺序的上一个平行节点标签 |
|
.next_siblings |
迭代类型,返回HTML文本顺序后续所有平行节点标签 |
|
.previous_siblings |
迭代类型,返回HTML文本顺序后续所有平行节点标签 |
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text #demo == url网页代码 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.a.next_sibling) #a 的下一个平行节点是字符串 >>> 'and' 5 print(soup.a.next_sibling.next_sibling) #a 的下一个平行标签的在下一个平行标签 6 print(soup.a.previous_sibling) #a 的上一个平行标签 7 print(soup.a.previous_sibling.previous_sibling) #>>> None (空信息) 8 #遍历后续平行节点: 9 for sibling in soup.a.next_siblings: 10 print(sibling) 11 #遍历前序平行节点: 12 for sibling in soup.a.previous_siblings: 13 print(sibling) |
|
基于bs4库的HTML格式输出:
prettify()函数:打印标签(HTML格式打印)
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.a.prettify()) #输出a标签(HTML格式) 5 ''' 6 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1"> 7 Basic Python 8 </a> 9 ''' 10 soup = BeautifulSoup('<p>中文</p>','html.parser') 11 print(soup.p.string) #以[获取<tag>标签的非属性字符串/注释]输出标签 12 ''' 13 中文 14 ''' 15 print(soup.p.prettify()) #以HTML格式输出标签 16 ''' 17 <p> 18 中文 19 </p> 20 '''
信息组织和提取:{0.3.py}
信息的标记:
标记后的信息可形成信息组织结构,增加了信息维度
标记后的信息可用于通信
存储或展示
标记的结构与信息一样具有重要价值
标记后的信息更利于程序的理解和运用
HTML的信息标记:
HTML(Hyper Text Markup Language):超文本标记语言;是WWW(World Wide Web)的信息组织方式将声音、图像、视频利用超文本的方式嵌入到文本中;
HTML通过预定义的<>...</>标签形式组织不同类型的信息
信息标记的三种形式:( XML JSON YAML )
XML (eXtensible Markup Language):扩展标记语言(基于HTML)

JSON(JavsScript Object Notation):有类型的键、值对(key:value)表达方式
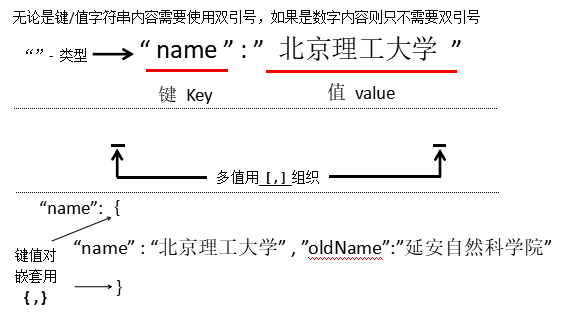
YAML(YAML Ain’t Markup Language):递归的定义;无类型的键值对 Key : Value

三种信息标记方式的比较:(实例)
|
XML实例 |
|
<person> <firstName>Tian</firstName> <lastName>Song</lastName> <address> <streetAddr>中关村南大街5号</streetAddr> <city>北京市</city> <zipcode>100081</zipcode> </address> <prof>Computer System</prof><prof>Security</prof> </person> |
过实例可以看出,其中有效的信息文本比例并不高,大多数信息被标签占用 |
|
JSON实例 |
|
|
{
“firstName” : “Tian” ,
“lastName” : “Song” ,
“addresss” : {
“streetAddr” : “中关村南大街5号”,
“city” : “北京市”,
“zipcode” : ”100081”
}
“prof” : [ “Computer System” , “Security” ]
}
|
JSON通过键值对的方式,定义相关的键<tag>,但无论如何都要用冒号和花括号来区分结构体和键值对 |
|
|
YAML实例 (YAML简洁、明了) |
||
firstName : Tiam
lastName : Song
address :
streetAddr : 中关村南大街5号
city : 北京市
zipcode : 100081
prof :
-Computer System
-security
|
||
|
信息标记 |
比较 |
应用 |
|
XML |
最早的通用信息标记语言,可扩展性好,但繁琐 |
Internet上的信息交互与传递 |
|
JSON |
信息有类型,适合程序处理(js),较XML简洁 |
移动应用云端和节点的信息交互,无注释 |
|
YAML |
信息无类型,文本信息比例最高,可读性好 |
各类系统的配置文件,有注释易读 |
信息提取的一般方法:
方法一:完整解析信息的标记形式,再提取关键信息。
XML JSON YAML_需要标记解析器,例如:bs4库的标签树遍历
优点:信息解析准确
缺点:提取过程繁琐,速度慢
方法二:无视标记形式,直接搜索关键信息。
搜索 对信息的文本查找函数即可
优点:提取过程简洁,速度较快
缺点:提取结果准确性与信息内容相关(缺乏)
融合方法:结合形式解析与搜索方法,提取关键信息
XML JSON YAML + 搜索 >>> 需要标记解析器及文本查找函数
实例:
1 import requests 2 from bs4 import BeautifulSoup 3 '''#提取HTML中所有的URL链接 4 1、搜索到所有的<a>标签(a标签的内容即url) 5 2、解析<a>标签格式,提取href后的链接内容 6 ''' 7 8 9 r = requests.get('http://python123.io/ws/demo.html') 10 demo = r.text 11 soup = BeautifulSoup(demo,'html.parser') 12 for link in soup.find_all('a'): #查找demo中的<a>标签 13 print(link.get('href')) #在<a>标签中查找“href”函数 14 15 16 ''' 17 结果: 18 http://www.icourse163.org/course/BIT-268001 19 http://www.icourse163.org/course/BIT-1001870001 20 '''
Beautiful Soup库的方法:
bs4.element.Tag:标签类型;
|
方法 |
<>.find_all (name,attrs,recursive,string,**kwargs) |
||||||||||||||||
|
说明 |
可以在soup的变量中去查找里边的信息 |
||||||||||||||||
|
参数 |
返回一个列表类型,存储查找的结果
|
||||||||||||||||
|
简短检索 |
<tag>(...) 等价于 <tag>.find_all(..) soup (...) 等价于 soup.find_all(..) |
||||||||||||||||
|
扩展方法 |
|
name实例:
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text 3 soup = BeautifulSoup(demo,"html.parser") 4 print(soup.find_all('a')) #list形式返回soup(文本)中的标签字符串(检索a标签) 5 print(soup.find_all(['a','b'])) 6 for tag in soup.find_all(True): #遍历soup中的所有标签 7 print(tag.name) #打印(获得)所有标签的name(名称)!! 8 ''' 9 [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" 10 id="link1">Basic Python</a>, <a class="py2" href="http://www.icourse163.org 11 /course/BIT-1001870001" id="link2">Advanced Python</a>] 12 [<b>The demo python introduces several python courses.</b>, <a class="py1" 13 href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic 14 Python</a>, <a class="py2" href="http://www.icourse163.org/course/ 15 BIT-1001870001" id="link2">Advanced Python</a>] 16 html 17 head 18 title 19 body 20 p 21 b 22 p 23 a 24 a 25 '''#结果
attrs实例:
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.find_all('p', 'course')) #返回带有course属性的P标签 5 print(soup.find_all(id='link1')) #返回ID属性==link1的内容 6 7 ‘’’ 8 9 [<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: 10 11 <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>] 12 13 [<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>] 14 15 ‘’’
recursive实例:
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup.find_all('a')) #检索a标签 5 print(soup.find_all('a',recursive=False))#返回一个空列表,说明a的下层节点没有a标签(False下只检索一层(儿子层))
string实例:
1 r = requests.get('http://python123.io/ws/demo.html') 2 demo = r.text 3 soup = BeautifulSoup(demo,'html.parser') 4 print(soup) #输出经过解析器解析的完整HTML代码 5 print(soup.find_all(string = 'Basic Python')) #列表返回检索到的字符串信息
中国大学排名定向爬虫案例{0.4 bs.py}
1 import requests 2 import bs4 3 from bs4 import BeautifulSoup 4 #soup = BeautifulSoup(demo,'html.parser') 5 def getHTML(url):#标准框架 6 try: 7 r = requests.get(url) 8 r.raise_for_status() 9 r.encoding = r.apparent_encoding 10 return (r.text) 11 except: 12 print("链接爬取失败") 13 14 def uitHTML(ulist,demo): 15 soup = BeautifulSoup(demo,'html.parser') 16 for tr in soup.find('tbody').children: 17 18 #.find(..)搜索标签结果返回 .children同时遍历儿子(下层)节点 19 if isinstance(tr,bs4.element.Tag): 20 21 #检测tr的类型,如果不是标签类型,则过滤(避免遍历到字符串内容)isinstance判断变量类型 22 tds = tr('td') #等价于tr.find(...)>>>查找 td 标签 (返回的对象是list) 23 #print(tds) #检验使用:查看tds内容 24 #tds此时得到了url的HTML中所有tr中td标签的HTML格式(list格式返回) 25 ulist.append([tds[0].string, tds[1].string, tds[3].string]) 26 #将tds中需要的数据(只提取.string>>字符串 区域)存入ulist列表中 27 28 def uitUlist(ulist,num): 29 print("{:^16} {:^16} {:^16}".format("排名","学校名称","总分")) 30 for i in range(num): 31 u = ulist[i] 32 print("{:^16} {:^16} {:^16}".format(u[0],u[1],u[2])) 33 34 def main(): 35 ulist = [] 36 url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" 37 demo = getHTML(url) 38 uitHTML(ulist,demo) 39 uitUlist(ulist,20) 40 41 main()
正则表达式:re库:(https://www.cnblogs.com/wangyuyang1016/p/10034868.html)
正则表达式的常用操作符
|
. |
表示任何单个字符 |
|
|
[ ] |
字符集,对单个字符给出取值范围 |
[a,b,c]表示a,b,c ; [a-z]表示a到z的单个字符 |
|
[^] |
非字符集,对单个字符给出排除范围 |
[^a,b,c]表示非a非b非c的单个字符 |
|
* |
前一个字符0次或无限次扩展 |
abc*表示ab, abc, abcc, abccc 等 |
|
+ |
前一个字符1次或无限次扩展 |
abc+表示abc,abcc,abccc 等 |
|
? |
前一个字符0次或1次扩展 |
abc?表示ab,abc |
|
| |
左右表达式任意一个 |
abc|def表示abc或def |
|
{m} |
扩展前一个字符m次 |
ab{2}c表示abbc |
|
{m,n} |
扩展前一个字符m至n次(含n) |
ab{1,2}c表示abc、abbc |
|
^ |
匹配字符串开头 |
^abc表示abc且在一个字符串的开头 |
|
$ |
匹配字符串结尾 |
abc$表示abc且在一个字符串的结尾 |
|
( ) |
分组标记,内部只能使用 | 操作符 |
(abc)表示abc,(abc|def)表示abc、def |
|
d |
数字,等价于[0-9] |
|
|
w |
单词字符,等价于[A-Za-z0-9] |
|
re库主要功能函数
|
re.search() |
在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
|
re.match() |
在一个字符串的开始位置起匹配正则表达式,返回match对象 |
|
re.findall() |
搜索字符串,以列表类型返回全部能匹配的子串 |
|
re.split() |
将一个字符串按照正则表达式匹配结果进行分割,返回list类型 |
|
re.finditer() |
搜索字符串,返回一个匹配结果的迭代(iterable)类型,每个iterable元素是match对象 |
|
re.sub() |
在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
功能函数详讲:
|
语法 |
re.search ( pattern , string , flags=0 ) |
||||||
|
参数 说明 |
|
||||||
|
flags控制标记 |
|
|
语法 |
re.match ( pattern , string , flags=0 ) |
||||||
|
参数 说明 |
|
||||||
|
flags控制标记 |
|
|
语法 |
re.findall ( pattern , string , flags=0 ) |
||||||
|
参数 说明 |
|
||||||
|
flags控制标记 |
|
|
语法 |
re.split ( pattern , string , maxsplit=0 , flags=0 ) |
||||||||
|
参数 说明 |
|
||||||||
|
flags控制标记 |
|
|
语法 |
re.finditer ( pattern , string , flags=0 ) |
||||||
|
参数 说明 |
|
||||||
|
flags控制标记 |
|
|
语法 |
re.sub ( pattern , repl , string , count=0 , flags=0 ) |
||||||||||
|
参数 说明 |
|
||||||||||
|
flags控制标记 |
|
re.compile():面向对象用法(操作):
|
语法 |
regex = re.compile( pattern , flags = 0) |
||||
|
说明 |
·将正则表达式的字符串形式编译成正则表达式对象(object)
match = regex.search(‘string’) #compile()后的re函数功能使用和原来一样
|

Match对象的属性
|
属性 |
说明 |
|
.string |
待匹配的文本 |
|
.re |
匹配时使用的pattern对象(正则表达式) |
|
.pos |
正则表达式搜索文本的开始位置 |
|
.endpos |
正则表达式搜索文本的结束位置 |
Match对象的方法
|
方法 |
说明 |
|
.group(0) |
获得匹配后的字符串 |
|
.start() |
匹配字符串在原始字符串的开始位置 |
|
.end() |
匹配字符串在原始字符串的结束位置 |
|
.span() |
返回(.start() , .end()) |
实例:
1 import re 2 match = re.search(r'[1-9]d{5}','BIT 100081') 3 #Match对象的属性 4 print(match.string) #返回匹配时的待匹配字符串 5 print(match.re) #返回匹配时的re表达式 6 print(match.pos) #返回匹配的搜索文本开始的位置 7 print(match.endpos) #返回匹配的搜索文本结束的位置 8 #Match对象的方法 9 print(match.group(0)) #返回匹配后的字符串(第一次匹配结果) 10 print(match.start()) #匹配原始字符串开始的位置 11 print(match.end()) #匹配原始字符串结束的位置 12 print(match.span()) #元组形式返回 .start()和.end()
re库的贪婪匹配和最小匹配
1 match = re.search(r'PY.*N','PYANBNCNDN') #贪婪匹配(re库默认贪婪匹配,即输出最长的子串匹配) 2 print(match.group(0)) 3 match = re.search(r'PY.*?N','PYANBNCNDN') #最小匹配 4 print(match.group(0))
最小匹配操作符
|
操作符 |
说明 |
|
*? |
前一个字符0次或无限次扩展,最小匹配 |
|
+? |
前一个字符1次或无限次扩展,最小匹配 |
|
?? |
前一个字符0次或1次扩展,最小匹配 |
|
{m,n}? |
扩展前一个字符m至n次(含n),最小匹配 |