一.大型网站优化之MySql优化
1.优化和不优化的对比的
在业界当中我们有一个叫大数据(big data)的概念,所谓的大数据指代千万级别以上的数据作为起步的数据。所以我们现在需要对两张都具有50331650条记录的表进行查询对比,其中表名为tbl_no的表是没有做过任何优化手段的表,表名为tbl_yes的表是做过优化手段的表。这个实验的目的是观察具有优化手段和不具有优化手段的查询中速度的差别。
实验条件:
1)两张表的数据记录总数是相同的
2)两张表的数据字段结构也是一样的
3)查询的记录的where条件都是username='itcast'的用户
实验结果对比出现如下的结果:
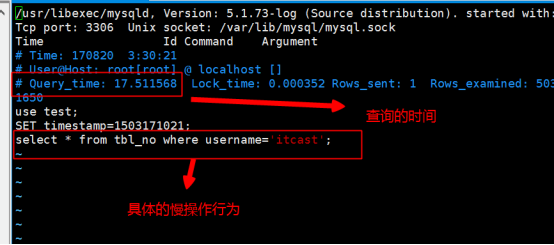
①表tbl_no查询条件为username='itcast'的用户耗时时间为15.59sec:
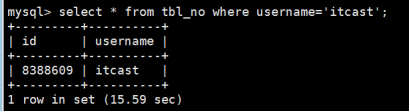
②表tbl_yes查询条件为username='itcast'的用户耗时时间为:0.01秒
最终的对比结果如下:

2.业界中对“慢”的定义[八秒原则]
在今天互联网当中有一个所谓的8秒原则,根据统计一个用户在8秒中之内如果不能打开一个网站,那么有99%的用户会选择关闭浏览器。
其实8秒原则是相对论,因为如果一个网站打开的速度超过两秒达到3秒钟才能打开其实就已经无限在挑战用户的耐心了,也就说其实我们做优化是尽可能控制速度在2秒内完成,这样才能更好的留住用户,避免挑战用户的等待耐心.

然而我们说为什么数据库的查询速度慢就会影响用户等待的耐心呢?
3.PHP+MySql架构的请求原理
在开发的当中我们使用php+mysql的架构占据了主要的开发方式,这种架构形成的请求其实真正的结果执行最终发生在MySql数据库当中,其主要流程图如下所示:
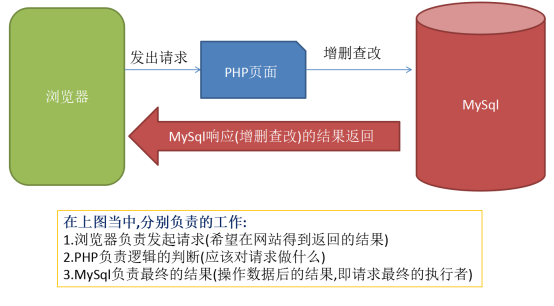
如果这个请求的过程当中,数据库响应达到了?秒,那么也就就是说浏览器的客户在不断等待网站数据返回(打开),也就是这样8秒原则的定律就会成型,用户关闭浏览器的可能性是99%的.
二.MySql优化的层面
1.表设计层面:存储引擎,索引,列类型,范式规范(冗余)
2.服务器层面:实现数据库主从复制(读写分离)
3.编程层面:避免在循环中select数据表
4.缓存层面:使用nosql技术
5.系统层面:使用Linux操作系统作为服务器底层
6.其他方面:硬件,集群服务器,靠谱的idc供应商,靠谱的技术团队
天下没有免费的午餐,任何的优化其实都具有主观的性质存在而且每一种优化的手段基本上都需要付出一定的代价。世界上没有一个非常标准的优化技术给你作为参考,优化是一门永远不会停止课题,随着你的经验的积累,那么你的优化手段和见解就有可能不同
三.MySql存储引擎
1.什么是存储引擎
MySQL中的数据是通过各种不同的技术格式存储在文件(或者内存)中的。技术和本身的特性就称为"存储引擎"。每一种需求都使用不同的存储引擎,才能获取不同的数据库性能和功能上的需求。
如果在生活把独门独户的楼房(纵向结构)和平房(平面结构)看作存储引擎的话,不同的建筑结构对于不同的需求来说就有不同的便利。对于送快递的人来说,独门独户的楼房便于快递的小哥的投递。对于装空调或者搬家具的师傅来说,平房自然更有利于空调的安装和家具的进出。
由此我们可以知道一个结论,选择不同的存储引擎就是选择不同的技术格式(结构),他们的特性决定他们对某种需求的优势,因此存储引擎的正确选择是做MySql优化的关键。
2.存储引擎的查看和默认项
在mysql数据库当中其实有5种存储引擎,并且会默认地帮用户选定其中一个,不同的数据库版本默认的选项是不一样的,所以我们可以通过以下的命令去了解当前mysql的存储引擎相关情况:
语法规则: show engines
执行命令效果如下:

(针对5.1.73的版本)
常用的存储引擎一般是MyISAM和Innodb,MyIsam是默认的存储引擎
Memory其实以前也是一个很受欢迎的引擎,然而它现在已经被Memcache和redis取代它的地位了,因此使用的人就极少了,这个引擎是一个内存机制的引擎类似Memcache,但性能不如memcache强大.(了解)
3.MyISAM表的文件及其特点
在mysql中,mysql把所有的数据库用目录来表示,把数据用文件的方式来进行存储。
mysql数据库在Linux当中它的目录路径在:/var/lib/mysql
建立一个名为demo的数据库
代码参看:code/demo.sql

查询/var/lib/mysql就会发觉多了一个名为demo的目录
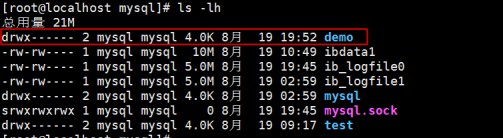
查看demo数据库中的myisam引擎下的表文件

在/var/lib/mysql/demo目录下,产生以下文件:

在mysql当中myisam引擎存储数据有3个文件组成
.frm文件用于存储建表的结构信息(字段信息)
.MYD用于储存表的记录信息
.MYI用于储存表的索引信息(例如:主键)
MyISAM存储引擎的特点:
建表结构,表记录信息和索引信息都独立存在的,由于MyISAM存储引擎的技术特点是结构和数据分离,因此可以更好地观察到该存储引擎的文件变化情况,因此大部分情况下我们做优化都是使用MyISAM引擎。
实验:创建一张产品表goods,代码如下:
代码详细请参考:code/goods.sql
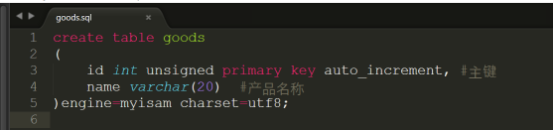
建表完成后,发觉/var/lib/mysql/demo下的文件有如下变化:

用复制数据的方法添加记录查看myisam引擎表的变化
第1步:向goods表添加3条记录

第2步:以倍增的方式复制数据

反复执行的结果如下:
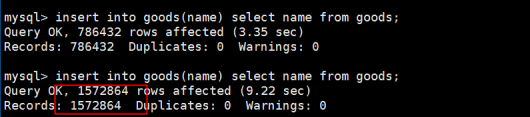
你会很快就可以插入几十万甚至几千万条数据
第3步:查看结果发现其实文件的大小变化如下图所示:
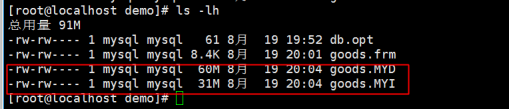
myisam引擎的表,当数据发生变化的时候,只有.MYI文件和.MYD文件会发生变化,而.frm文件不会发生改变
4.Innodb存储引擎表的文件及其特点
在mysql中,mysql把所有的数据库用目录来表示,把数据用文件的方式来进行存储。
mysql数据库在Linux当中它的路径在:/var/lib/mysql,因此无论是Innodb的引擎还是MyISAM引擎的表数据都存在于该目录当中,所以同样地我们可以在这个目录中进行Innodb引擎的表文件变化。
代码详细请参考:code/pros.sql
实验:创建一张产品表pros,代码如下:
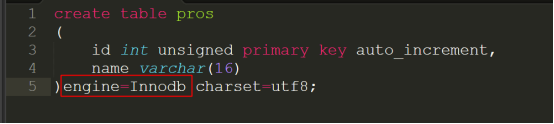
观察其实文件的变化如下:

问题来了:查看以上结果后你会发觉在Innodb只有一个.frm文件用于存储数据表的结构,那么Innodb的记录信息和索引文件存放哪里呢?
插数据来观察innodb的变化
第1步:向pros表添加3条记录
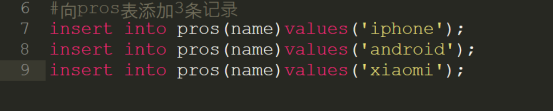
第2步:以倍增的方式复制数据

第3步:观察结果,可以得出以下结论:

被数据发觉/var/lib/msyql/demo目录没有任何的改变
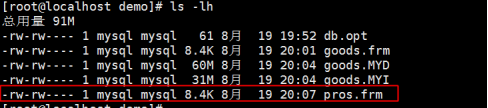
然而我们会发现如果我们继续倍增数据在/var/lib/mysql有一个文件ibdata1会发生改变,效果如下:
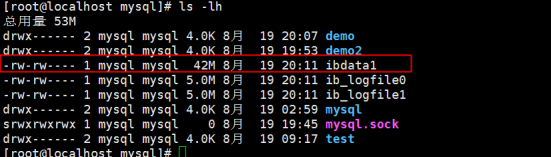
很快我们发觉会有一个这样的文件产生ibdata1,随着你对innodb的数据表pros添加数据,这个文件的大小发生了变化,因为innodb是把所有表记录信息和索引信息都共享在一个文件当中的。如果我们有10张innodb的表那么我们10张表的记录信息和索引信息都会存放到这个文件当中,因此我们要针对某一张innodb的表来做优化是很难的。所以我们证明了一点,做优化一般是针对myisam的表。
Innodb存储引擎的特点:结构和数据共享,目的是为了保证数据的完整性,为追求数据完整性和安全性而生的存储引擎。
5.MyISAM和Innodb的区别和应用场景(面试题)
Innodb
专注在数据完整性和安全性方面,例如:事务等,对查询,插入数据的效率支持就比较差
Myisam
MyIsam的是追求性能的而生的。因此我们说的mysql优化其实很多时候就是针对myisam引擎而言,但优化是要付出代价的,你要优化就要牺牲掉某些东西,如果你当前的业务要求安全性很高那么你就别谈什么优化了,也不能选择myisam了。
两种存储引擎的应用场景(引擎的选择)
大量查询(select)或者写入(update,insert,delete)就选择Myisam,例如:博客系统,论坛等
数据涉及利益和金钱交易,就需要很严谨和具有安全性,例如销售、财务,股票等系统,就选择innodb

四.MyISAM的表解压缩机制
1.应用场景
在37游戏公司当中有一个这样的业务,他们的游戏是按地区访问的,例如:你是广州的玩家,一般访问的是广州这边的游戏服务器数据,如果是你是上海的玩家那么你访问的游戏服务器数据一般是上海的,有时候总部某些游戏有更新(比如:更新的了游戏的地图),这时需要把这些游戏的更新数据进行其他地区的同步,比如同步到上海,这时就需要进行数据的迁移和复制.其原理图如下所示:
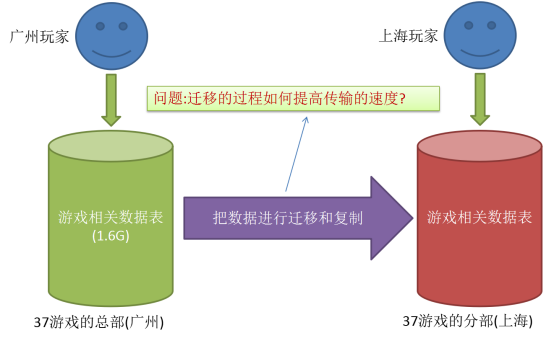
这时会产生一个这样的问题:如何提高数据迁移和复制的速度?
2.使用MyISAM的表压缩机制
压缩机制的优化其实是为了节约硬盘空间和传输文件的,对select语句的优化的最多提升能够达到0.1-0.8秒,因此解压缩机制的优化实际上并不是提高select语句的手段。
MyISAM的表压缩详细步骤如下:
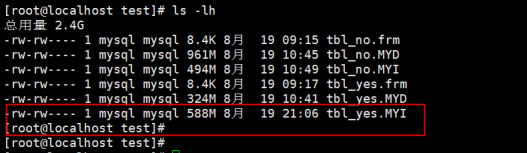
第1步:找到您需要压缩表文件,比如说如果希望压缩test数据库当中tbl_yes这张表,那么我就应该切换到/var/lib/mysql/test目录,找到tbl_yes这张表文件如下:
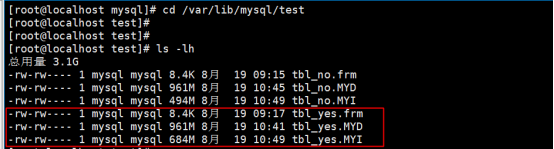
确认在没有进行压缩优化之前的
tbl_yes.frm的大小是8.4k
tbl_yes.MYD的大小是961M
tbl_yes.MYI的大小是684M
压缩其实跟您当前计算机cpu和硬盘的性能有关系,如果你硬盘读写能力很强,cpu的核数很高,那么压缩的速度就很快,反之压缩的速度就比较,压缩数据其实是有一个比率值的,如果用家庭电脑进行数据压缩,每个电脑压缩的比率值是不同,一般如果能压缩50%的比率就已经很厉害了,当然真正的服务设备一般压缩的比率高达80%以上,使用myisam的表压缩其实是一个非常伤硬盘的过程,所以真正的服务器经常要备份很多的读写硬盘进行更换,成本是非常高的.
第2步:使用命令myisampack命令进行压缩,命令的格式和机制如下,压缩必须压缩MYI索引文件,而不能直接压缩MYD文件,语法格式如下:
myisampack [数据表的索引文件全名]
执行如下:

执行压缩必须在/var/lib/mysql/test目录下进行,回车就会进行压缩优化,时间有长有短,根据设备而定,出现以下界面代表正在进行压缩优化:

如果压缩完成后就会出现以下界面:

第3步:压缩完成,我们观察压缩的结果如下所示:
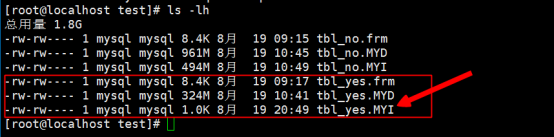
我们发觉tbl_yes.MYI文件被我们压缩坏了,因为它有原来的684M变成了1k,因此该文无法使用,因此数据也无法正常的读取了,因此出现这个问题,我们就需要重建索引文件,凡是经过压缩优化100%的可能性都是压坏索引文件,观察压缩的结果我们发觉其实mysql官方提示我们一句这样的话,记得执行myisamchk -rq

第4步:执行myisamchk -rq重建tbl_yes表的索引为文件tbl_yes.MYI
其语法格式如下:
myisamchk -rq [要重建的索引文件名称]
执行命令如下所示:
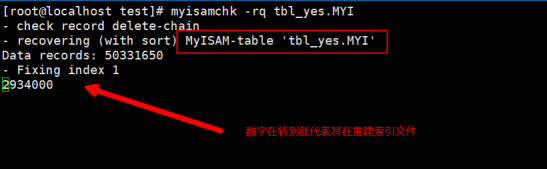
重建所以完成会重新恢复到shell标志当中,如下图所示:

重建索引之后,其实会发觉索引文件其实依然是有损坏的,因为mysql的开发者为了保证MYD文件的数据完整性,所以对索引文件进行性能的牺牲,其实压缩之后数据库表只能是只读的,不能插入任何的数据这个就是压缩的缺点,但是压缩不需要担心数据丢失和完整性,因为mysql5.1.73对Myisam压缩进行非常严谨的测试.重建索引的过程好像有点死机的感觉,但是不需要过分担心,因为这属于正常继续耐心等待.
MYD文件被压缩称为了324M,比原来的961M大大的缩减,因此提高网络传输的速度.
压缩优化完成必须刷新表
第5步:数据库的索引文件重建之后,并不代表马上就可以使用,因为这时其实索引文件重建后,无法正常读取压缩后数据,但是我们可以使用刷新表的技术,来让数据库恢复读取功能,语法如下:
mysqladmin -uroot -p登录密码 flush-table #刷新mysql当中表
mysqladmin -uroot -p123456 flush-table

执行没有返回任何的错误,那么就代表刷新表成功
第5步:登录数据库当中,重新查询tbl_yes这种表,结果如下:
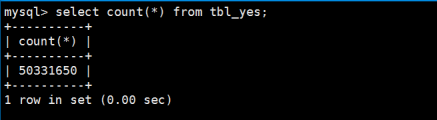
发觉压缩优化,数据不会丢失,于是接着查询username=itcast的用户
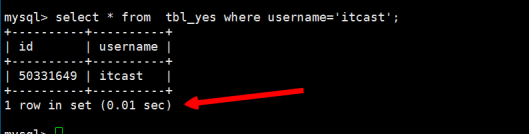
可以正常的查出信息,并且性能上没有受到任何的影响,当然也没有任何的提高,接下来插入一条数据,出现结果如下:

发觉压缩优化代价就是导致压缩后表是只读的状态,如果我们需要继续对tbl_yes这种表进行数据的插入,那么我们应该怎么办呢?答案:解压当前表
注意一个问题:在压缩优化层面,有一句俗语叫做解铃还须系铃人,也就说谁进行压缩谁就负责解压,为什么呢?因为数据其实在现实开发当中一般是由总部进行规划和统一的,分部不能随意插入数据,分部只能读取总部插入的数据,因此压缩优化就被运用在37wan这个场景
3.使用MyISAM的解压机制
如果一张表进行了压缩,那么这张表就只能是只读的,如果需要该表能够重新进行写入的操作,那么就必须使用MyISAM的解压机制.
MyISAM的表解压的详细步骤如下:
第1步:同样需要找到要进行解压的表,然后使用命令: myisamchk --unpack
进行解压操作,如果你忘记了这个命令,我们可以使用man myisamchk来进行查看
发觉有一个这样的选项:

第2步:使用命令如下:
myisamchk --unpack [索引文件名称],执行效果如下:
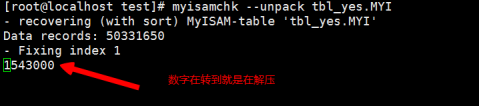
解压完成后,会出现以下界面:

文件解压后的变化如下:
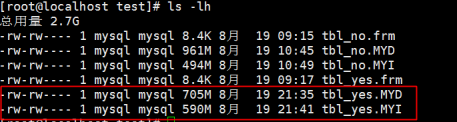
其实解压也无法恢复到没有压缩的数据状态,文件依然有所损坏的,包括MYD文件也是有所损坏的但不影响任何的操作
第3步(建议步骤):解压完成后,同样不要马上进行数据的插入,因为如果这时进行数据的插入,可能会为表的后续发展产生一些bug,建议也是解压后进行刷新恢复之后再进行插入.其实这一步不是必须的.执行命令:mysqladmin -uroot -p123456 flush-table

刷新之后,必须要退出mysql的登录然后再重新登录
第4步:登录mysql数据进行数据插入和查询操作,结果如下:
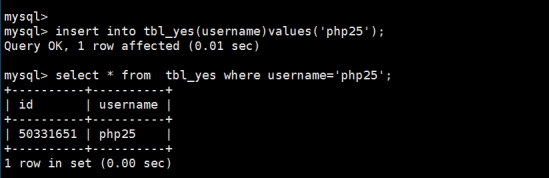
五.MySql的explain执行计划
1.什么是执行计划
explain是一个Mysql性能显示的工具,它显示了MySQL如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。在开发当中我们一般用explain来查看索引的使用情况,explain你可以把它理解成为一个查看索引使用情况的工具,但官方对它的定义是explain是一个mysql执行计划(ex=execute),不过这种概念的东西不需要过分的纠结,反正你知道有这么一回事就可以了。
语法规则:explain [select 语句]
执行explain select * from tbl_no where username='itcast' 结果如下:

explain执行计划最重要的选项:

2.explain执行计划分析tbl_yes

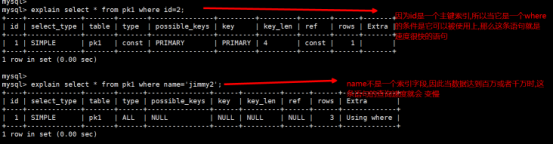
比对explain扫描tbl_yes和tbl_no的结果你会发现其实只要使用索引,那么速度就会很快,而且只要 使用到索引那么就一定不会是全表扫描all的方式,并且扫描的记录行数也大大缩减,因此这个就是为什么tbl_yes比tbl_no快的主要原因,关键一点就是tbl_yes有使用到索引.
六.索引的概述
1.为什么要使用索引
数据库的索引其实就好像书本的目录一样,假设你拿一本新华字典来查一个字,如果新华字典的拼音字母的目录不见了,笔画部首的目录被撕掉了,这时你去找这个字你就慢了。但如果重新把这个目录给你,你的查找这个字的速度肯定快了很多。索引就相当于这个目录的作用,它能提高select语句查找记录的速度。

在Mysql当中尽管索引查找的速度非常快,然而Mysql的任何一种优化都是需要付出一定代价的,添加索引会占据很多的磁盘的空间,也会降低写操作(delete , update , insert)语句的效率。其实索引我们很早就接触过,主键就是一种索引。主键也是所有索引当中最高效率的。

在数据库当中,索引优化有一个原则:使用上索引就一定会快,并且使用上索引就不会是ALL
2.常见索引的分类
在Mysql的常用引擎Innodb和MyISAM当中它们的索引结构是一种叫Btree的类型,因为它们是根据一种叫“二叉树”的算法创建出来的。在Mysql当中常见的索引使用有4种,分别为:
主键索引( Primary Key )
普通索引( Key )
唯一性索引(Unique)
全文索引(FullText):这个索引其实被sphinx取代了其地位
特殊的索引有1种:前缀索引
3.查看索引的方法
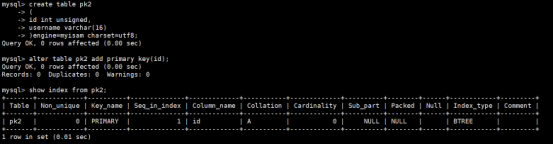
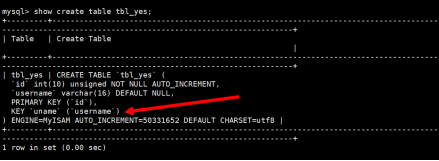
1.语法规则:show index from [表名称]
使用命令: show index from tbl_yes

primary是一个主键索引,它作用在id字段中
uname的普通索引,它作用在username字段中
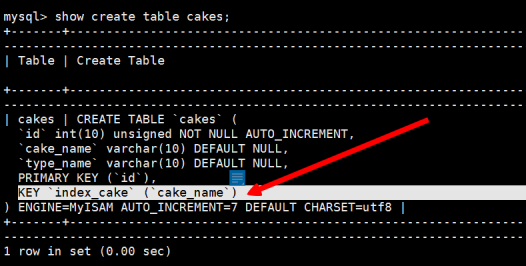
2.语法规则:show create table from [表名称]
使用命令:show create table tbl_yes
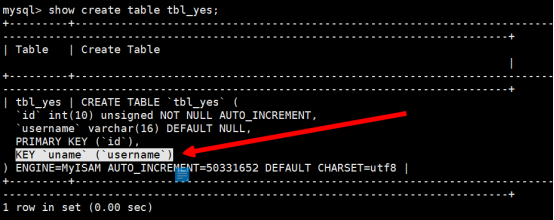
以上方法其实是通过查看建表的结构来查看索引的相关信息
七.主键索引
主键索引的原则和场景:
在开发当中我们往往需要对一些重复性的数据进行区分,那么这时我们就需要使用主键索引,主键索引既不能为null,也不能重复,更不能为空字符串。在id字段中出现最多,通常还会配合自增长一起使用,主键索引也是所有索引当中查询速度最快的索引。
1.在创建表的时候创建主键索引
代码详细请参考:code/pk1.sql
语法规则:primary key关键字
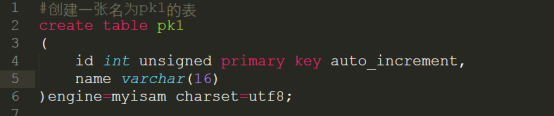
插入一些数据测试主键:

使用explain执行计划查看主键是否会被使用上:
使用命令explain select * from pk1 where id=2;和explain select * from pk1 where name='jimmy2';进行对比,结果如下所示:
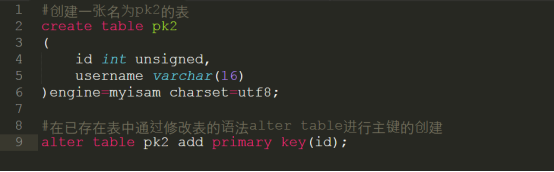
3.在已有表中创建主键索引
代码详细请参考:code/pk2.sql
语法规则:alter table 表名 add primary key(字段名称)
执行结果如下:
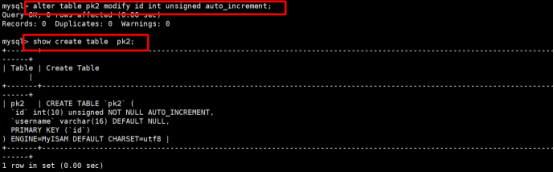
有时候我们在创建主键索引的时候,遇到id字段我们还需要配合设置
整型数据类型的自增长,这时可以使用以下语法在已有的表中进行建立
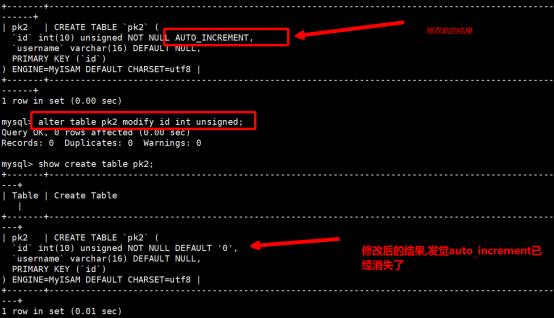
语法规则:Alter table 表名 modify 字段名 字段类型 auto_increment

执行后,效果如下:
4.删除表中的主键索引
代码详细请参考:code/pk3.sql
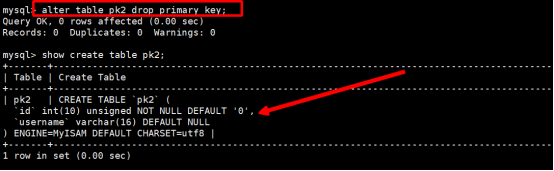
语法规则:Alter table 表名 drop primary key;
主键删除的详细步骤:
1)主键含有自动增长的特性,需要首先删除自增长的属性,否则就会报错,如下图所示:

执行效果如下:

2)使用Alter table语句修改去除主键字段的自动增长属性,如下图所示:

执行结果如下:
3)使用删除主键的语法规则对主键进行删除.

执行结果:
八.唯一性索引
唯一索引的原则和场景:
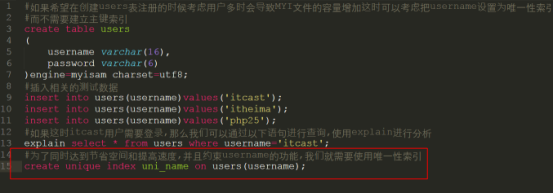
在开发当中,有时我们在网站使用用户名进行注册需要对用户进行唯一性约束,这时唯一性索引就可以起到约束的作用,同时唯一索引也能提高数据查找的速度,因此唯一性索引在开发中使用十分广泛。
1.创建唯一性索引
代码详细请参考:code/unique1.sql
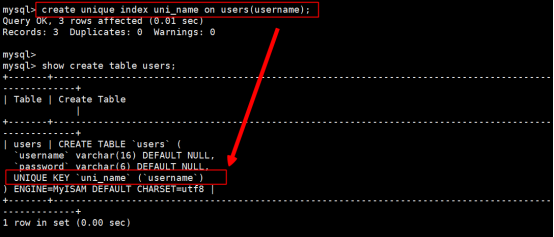
语法规则:create unique index 索引的名称 on 表名(字段名称)
执行效果如下:
插入一些数据测试唯一索引的约束性:
添加一个username为tommy的数据进行测试,效果和步骤如下:
第1次插入:

第2次插入:
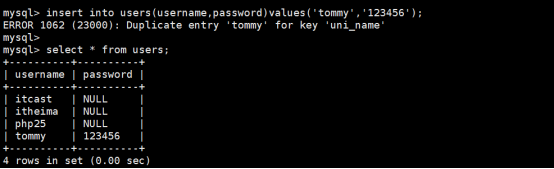
以上例子给我们的启示是可以在注册用户的使用多用唯一性所以进行唯一约束。
使用explain执行计划查看唯一性索引是否会被使用上:
执行命令:

2.删除唯一索引
代码详细请参考:code/unique2.sql
语法规则: alter table 表名 drop index 索引的名称

执行结果如下:
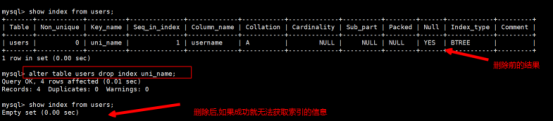
3.唯一性索引的注意事项
代码详细请参考:code/unique3.sql
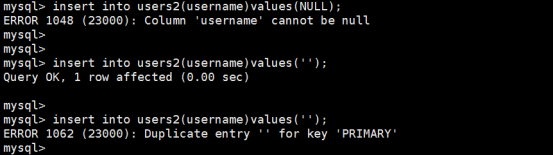
1.在唯一索引当中,null是可以重复的

如果重复插入null值结果如下:
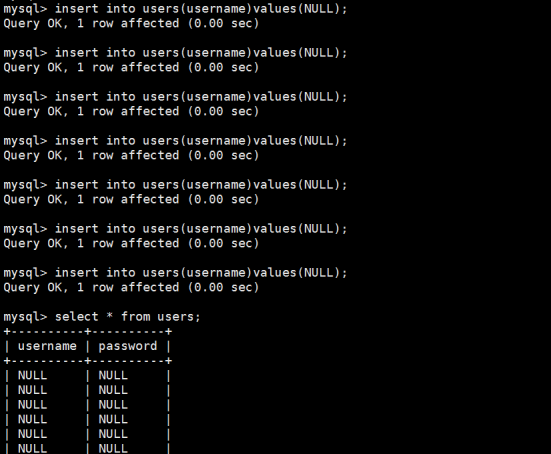
发觉唯一性索引对NULL值不起任何的约束作用,这个是唯一性索引的缺点
2.在唯一索引当中空字符串是不能重复的

重复插入空字符串进行测试的结果如下:


发觉以上唯一性索引的特性后,我们可以把users表修改成为以下形式,把唯一性索引在该应用场合中使用主键进行替代,查看效果:
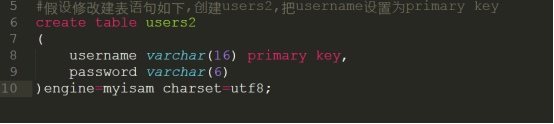
执行结果如下:
面试题:唯一索引和主键的区别是什么?
唯一性索引可以插入NULL值,但对NULL不起任何的约束作用,唯一性所以对空串可以插入一次但对空串起唯一性约束作用,主键不可以插入NULL值,空串也可以插入一次并且起唯一性的约束作用,但主键多用于id列,一般是用int的形式比较多,所以在注册的时候,我们可以常使用使用唯一索引而省略id的主键索引,以上只是一个参考而不是一个标准.
九.普通索引
普通索引的原则和场景:
在开发当中,如果我们仅仅是为了提升查询的效率但不需要用到任何的约束性行为,那么就可以使用普通索引
1.创建普通索引
代码详细请参考:code/normal.sql
创建表和数据如下:
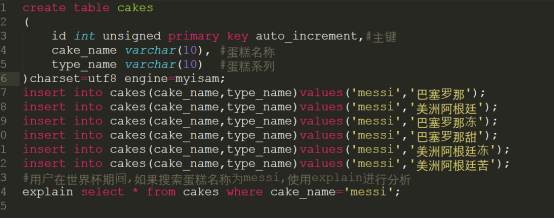
如果这时不对cake_name字段进行索引的创建,那么就会产生如下explain执行结果:

发觉用户如果按蛋糕名称进行搜索,那么就会产生全表扫描,整个效率就太差了。但是我们又必须不能对cake_name进行唯一索引的约束,这时普通索引的应用场景就出现了。
语法规则:create index 索引名称 on 表名称(字段名称)

执行效果如下:

在表具备数据记录后再创建其实对表的数据发生任何的改变,效果如下:
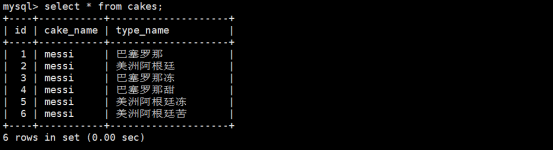
查看建表的结构如下:
使用explain执行计划查看普通索引是否会被使用上:

查询tbl_yes的表结构如下:
建立普通索引就算数据有5千多万条查询的速度依然可以很快,只要索引可以被使用上即可
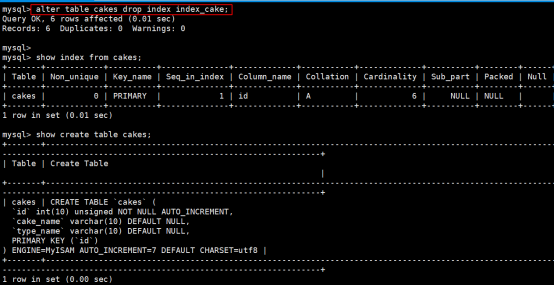
2.删除普通索引
语法规则: alter table 表名 drop index 索引的名称

执行结果如下:

十.全文索引
1.like查询的索引原则
代码详细请参考:code/like.sql
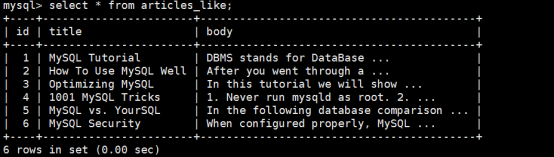
如果我们需要查看articles_like表中title字段含有mysql关键字的数据记录,那么我们可以创建以下的实验步骤:
第1步:建立articles_like表,并且把title字段设置为普通索引

第2步:为articles_like表插入一些测试数据

执行结果如下:
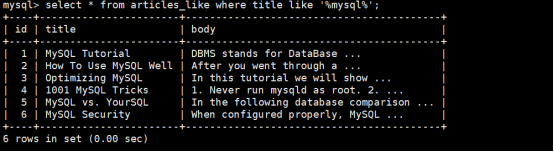
第3步:我们使用以下数据库like语句查询标题中含有mysql关键字的数据库记录
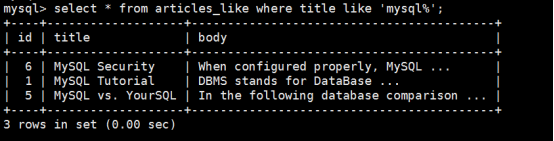
使用命令:select * from articles_like where title like '%mysql%';
执行效果如下:
我们的title字段是有索引的,是一个普通索引tit,但是这时使用like进行模糊搜索,这个索引是否可以被使用上呢?
第4步:使用explain执行计划查看like语句是否使用到索引
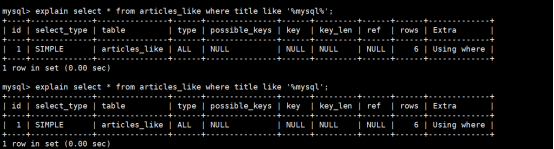
使用命令: explain select * from articles_like where title like '%mysql%';

发觉like语句使用不了索引,原因就在于在MySql数据库中,如果使用like条件语句当中%
出现在查询关键字之前,那么将无法使用到索引。所以以下情况都是不可能使用到索引的:
①select * from articles_like where title like '%mysql%';
②select * from articles_like where title like '%mysql';
如果把%放在查询关键字之后,那么就有可能使用上索引,但是这个只是可能性比较高罢了,而不是100%可以使用上的.
以下情况like有可能用得索引,但搜索出来结果不是你想要的:
使用命令: explain select * from articles_like where title like 'mysql%';
执行结果如下:

如果%号出现在搜索关键字之后,那么like是可以使用关键字的,然而查询的结果是会丢失记录的:
但是如果我们真的需要使用到索引,有必须保证查询结果的完整性,那么我们应该怎么办呢?
全文索引应运而生.
2.全文索引(FullText)
全文索引是为取代Like而生,然而mysql自带的全文所以不支持中文.一般人会使用sphinx+coreseek词库来代替它,这个主题我们会在第3天的时候着重讲解
全文索引的原则和场景:
全文索引能很好取代like的查询,且功能比like强大,但MySql自带的全文索引FullText在MySql5.6以下的版本并不支持中文,而MySql5.6的数据库版本使用的用户很少.因此MySql自带的全文索引在真正的大型网站开发当中会被Sphinx这个第3方的工具所取代,但自带的全文索引可以使用在一些英文的小型网站当中。
代码详细请参考:code/fulltext.sql
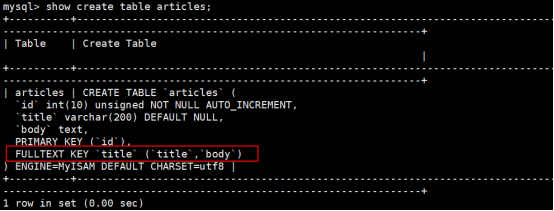
如果我们需要查看articles表中title或者body字段含有database关键字的数据记录,那么我们如果我们要满足以上的要求,就必须使用全文索引
1)创建全文索引
语法规则: fulltext(一个或者多个字段名称)
注意:一般使用fulltext的时候很少使用一个字段作为全文索引,因为使用给一个字段全文索引的意义就失去了

执行结果如下:
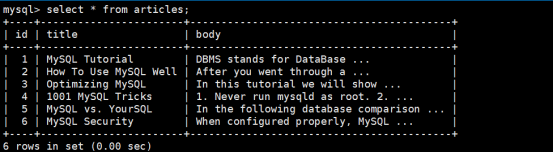
2)为articles表插入测试数据

执行结果如下:
3)全文索引的布尔模式查询原则
语法规则:match(全文索引的字段列) against( ‘+关键字’ in boolean mode)
①查看articles表中title或者body字段含有database关键字的数据记录
使用命令:

执行结果如下:

②查看articles表中title或者body字段含有mysql关键字的数据记录
使用命令:

结果如下:

发觉以上的查询没有成功,正常来说应该查询出6条记录,但是为什么一条也查不出来的呢?原因是全文索引其实是根据算法生成的所以,支持一种叫布尔查询的模式,因此如果不使用布尔查询那么就有可能查询的结果不准确,因此使用全文索引必须使用布尔查询模式,使用布尔查询模式修改上面的查询语句如下所示:

执行结果如下所示,发觉查询正确了:
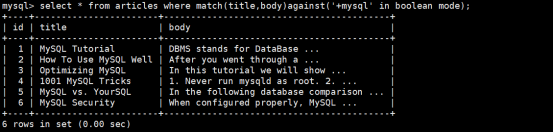
我们发觉全文索引其实可以完成like的功能,但是它会使用到索引吗?
使用explain查看全文索引是否有使用到索引:

执行explain语句那么发觉fulltext索引是可以被用上,也就是说Like以后你可以不要使用了,like是可以完全使用fulltext来取代的,但是fulltext不支持中文,所以只能应用在英文网站当中,如果希望使用中文的全文所以必须使用第三方工具sphinx+coreseek
十一.MySql的查询缓存机制
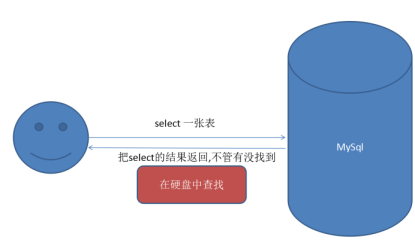
1.查询缓存机制的概述
在mysql所有数据查询都是实时的过程,不管一次查询数据是否有找到,那么数据库的编译器都必须在硬盘中做一次数据的查找响应,原理如下所示:
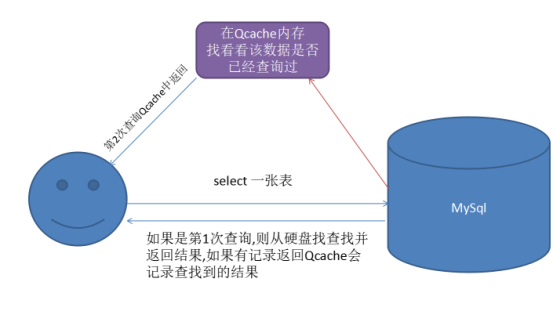
Mysql提供了一个机制,就是开启一个叫Qcache的空间缓存,这个缓存空间存在Mysql编译器内存当中,有一个用户发起了一次请求编译器会判断当前是否已经发起过,如果发起过,那么编译器将不会继续在硬盘当中做出查找的响应,而是把Qcache当中的结果进行返回,如果用户发起的请求是第一次的发起,那么mysql依然会从硬盘当中查找数据,但是同时也会把查找结果保存到Qcache空间当中,准备下一次查询响应,其原理如下所示:
2.开启Mysql的查询缓存
开启Mysql查询缓存就是开启编译器中的Qcache空间,这个空间默认的情况下以字节的大小来计算空间的大小,所以我们需要使用子字节换算来开启Qcache空间的大小
1k = 1024字节
1M = 1024k = 1024 * 1024字节
如果希望表示一个64M的字节大小,那么我们可以换算成为以下形式公式:
64M = 64 *1024 * 1024字节
开启MySql查询缓存的语法格式如下:
set global query_cache_size = 字节大小
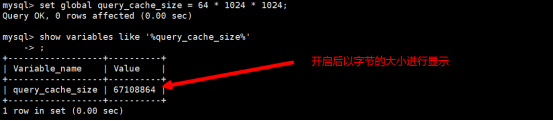
需求1:开启64M的查询缓存空间(Qcache),代码如下:
set global query_cache_size = 64 *1024*1024
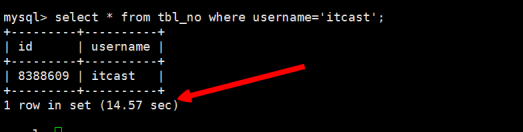
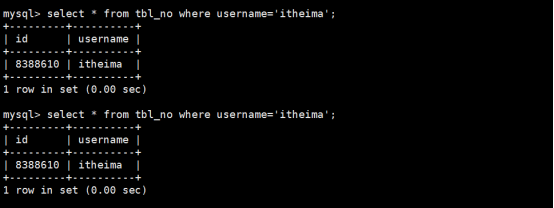
如果没有开启查询缓存时,使用select语句查询tbl_no的username=itcast的信息记录如下所示:
第1次查询如下,用时17.47sec:
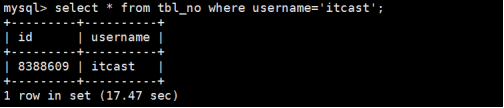
第2次查询如下,用时14.57sec,虽然有所提升,但是并不稳定,也不够理想
这时我们使用查询缓存机制,开启一个64M的Qcache空间,如下所示:

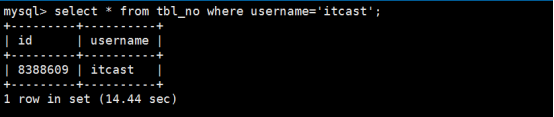
开启成功后,我们重新对tbl_no表username=itcast进行查询
第1次查询:由于第1次查询Qcache并没有任何的记录,所以mysql会从硬盘中查找
耗时:14.44sec
第2次查询:由于第2次查询时Qcache已经记录当前的查询结果,因此mysql不会去硬盘中查找数据,直接从Qcache当中返回数据,因此耗时接近0秒甚至达到0秒
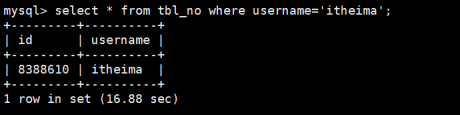
假设这时我们换一个查询条件,查询username=itheima的信息如下:
第1次查询:发觉这时又没有缓存的结果,因为这是第1次查询,耗时16.88sec
第2次查询,发觉耗时接近0秒甚至达到0秒,查询缓存的开启就会让第1次查询很慢之后都会很快,所以达到一定的优化过程
查询缓存的缺点是:如果查询缓存的累积空间达到64M的上限,那么mysqld就会自动释放Qcache空间,使得原来缓存消失,并且开启过多的Qcache空间会导致mysql编译器内存空间被占用过多,因此后来有人使用Memcache和redis进行取代,但是如果你的数据不算非常多,那么使用查询缓存是非常值得,因为查询缓存的开启方式和使用方式非常的简单
3.关闭mysql的查询缓存
关闭mysql的查询缓存有两种方法:
1)重启mysqld服务,使用service mysqld restart
2)使用命令: set global query_cache_size = 0 (建议使用该方法)

关闭之后,查询查询username=itcast的信息如下:
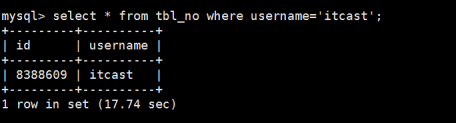
发觉查询缓存消失,数据查询重新开始变慢
4.查看查询缓存是否已经开启
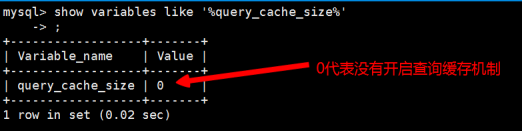
有时候我们需要直到这个查询缓存是否已经开启,我们可以使用以下命令进行查看:
show variables like '%query_cache_size%'
如果开启了查询缓存,那么查询结果如下:
十二.Mysql的慢查询日志
1.慢查询日志的概述
在开发当中,有时候我们希望能够捕捉到慢操作的相关具体命令,那么这时我们就需要使用慢查询日志(query_slow_logs),然而慢查询日志不只是记录select语句的慢操作,其他的语句如:insert update delete如果慢的话也会被日志所记录
慢查询日志有以下重要的函数(命令):
#表示当前MySql的认为慢操作的时间
show variables like 'long_query_time'
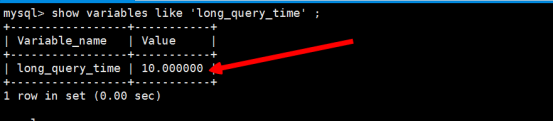
mysql默认情况下认为达到10秒钟的操作才算慢,这就与8秒原则相矛盾了,因此我们需要调整这个long_query_time的时间,根据自己的喜欢认为怎么样才算慢去调整,一般调整为2秒钟
#显示当前MySql的慢查询日志相关选项
show variables like '%slow%';

#显示当前MySql的慢操作总数
show status like 'Slow_queries';

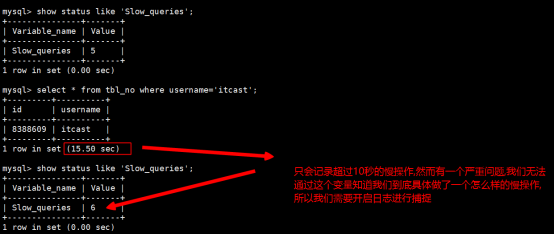
2.开启慢查询日志
如果希望开启慢查询日志,我们就必须要在Mysql配置文件中打开对应的配置选项,Mysql的配置文件存放在/etc/my.cnf当中,使用vim打开/etc/my.cnf

内容如下所示:
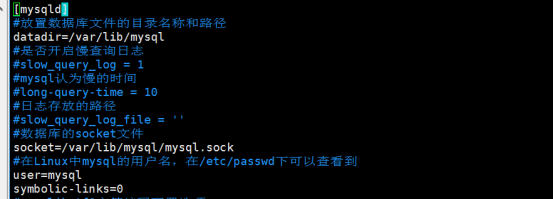
我们需要迅速找到以下几项:

修改以上3项内容如下所示:

保存并退出(:x),然后重启mysqld服务

如果重启没有报错,就代表配置选项设置成功,退出mysql登录重新登录,重看相关选项

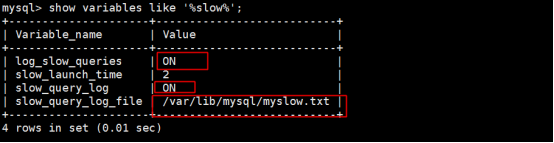
然后我们检查配置无误后,我们到/var/lib/mysql目录下查看,发觉有以下文件:
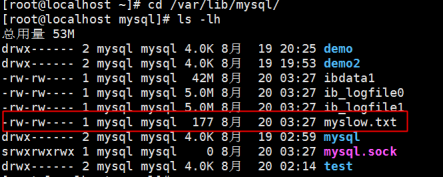
然后我们使用一个超过2秒钟的慢查询语句,如下所示:
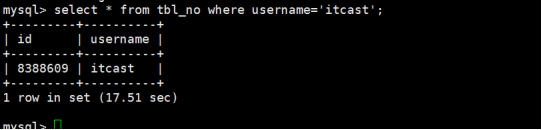
这时我们打开/var/lib/mysql/myslow.txt文件查看,使用vim打开

内容如下所示: