Python是一门解释型语言!
解释器类型:
cpython
pypy
ipython
Python声明解释得方法:
|
1
2
|
./yourpy.py #必须在文件头声明解释器(#!/usr/bin/env python)python yourpy.py #不需要声明解释器 |
编译型语言和解释型语言优缺点:
编译型
优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操纵系统之间移植就会有问题,需要根据运行的操纵系统环境编译不同的可执行文件。
解释型
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。

注:
JAVA既是编译型语言也是解释型语言,so 是混合型语言。
JavaScript 和 JAVA 的关系,就像雷锋和雷峰塔得区别。JavaScript是做前端使用,JAVA是做后端得。
变量定义的规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 以下关键字不能声明为变量名 ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
变量是什么,变量是一种容器。变量名起到标记数据得作用。
变量命名法:
|
1
2
|
两种命名法<br>trafficCost = windows 程序开发人员喜欢用 #驼峰命名法traffic_cost = python官方推荐 |
AGE_OF_OLDBOY = 18 #全是大写字母写得变量,叫做常量,是不变的量。
补充:
|
1
2
3
4
5
6
7
|
单词之间不以空格、连接号或者底线连结(例如不应写成:camel case、camel-case或camel_case形式)。共有两种格式:1、小驼峰式命名法(lower camel case):第一个单字以小写字母开始,第二个单字的首字母大写。例如:firstName、lastName。2、大驼峰式命名法(upper camel case):每一个单字的首字母都采用大写字母,例如:FirstName、LastName、CamelCase,也被称为 Pascal 命名法。变种:StudlyCaps,是“驼峰式大小写”的变种。补充说明,在JAVA中:类名的标识符一般用大驼峰式书写格式,方法和变量的标识符则多用小驼峰式书写格式。 |
缩进:
|
1
2
3
|
必须顶行同一级代码缩进必须一致官方建议缩四个空格 |
注释:
|
1
2
3
4
5
|
当行注视:# 被注释内容,是真注释。多行注释:""" 被注释内容 """,这不是真注释,只是把内容变成了字符串,是可以打印出来得。补充:单引号和双引号,没有任何区别,只适用于单行。 三个单引号和三个双引号,适应于多行。 |
字符编码:
python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256-1,所以,ASCII码最多只能表示 255 个符号。

关于中文
为了处理汉字,程序员设计了用于简体中文的GB2312和用于繁体中文的big5。
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。
GB2312 支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。2000年的 GB18030是取代GBK1.0的正式国家标准。该标准收录了27484个汉字,同时还收录了藏文、蒙文、维吾尔文等主要的少数民族文字。现在的PC平台必须支持GB18030,对嵌入式产品暂不作要求。所以手机、MP3一般只支持GB2312。
从ASCII、GB2312、GBK 到GB18030,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。按照程序员的称呼,GB2312、GBK到GB18030都属于双字节字符集 (DBCS)。
有的中文Windows的缺省内码还是GBK,可以通过GB18030升级包升级到GB18030。不过GB18030相对GBK增加的字符,普通人是很难用到的,通常我们还是用GBK指代中文Windows内码。
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
报错:ascii码无法表示中文
|
1
2
3
|
#!/usr/bin/env python print "你好,世界" |
改正:应该显示的告诉python解释器,用什么编码来执行源代码,即:
|
1
2
3
4
|
#!/usr/bin/env python# -*- coding: utf-8 -*- print "你好,世界" |
|
1
2
|
512 256 128 64 32 16 8 4 2 11 1 1 1 1 1 1 1 1 1 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
二进制位=bit = 8bits8bits = 1Byte = 1字节1024Bytes = 1KB = 1KB1024KB = 1MB = 100万字节 = 100万字符 = 1兆1024MB = 1GB = 一部高清电影短片, 1080p 20分钟,1024GB= 1TB1024TB = 1PB1个二进制位是计算机里的最小表示单元1个字节是计算机里最小的存储单位ASCII 256 ,每一个字符占8位GB2312 1980 67xxGBK1.0 1995 21000 2个字节GB18030 2000 27000unicode 万国码 utf-32 = 4字节 utf-16 = 2字节 utf-8 = 8bits 可变长编码 英文一个字节, 所有的中文3个字节 欧洲 2个字节 |
如果内存里都是Unicode的话,还会有乱码的问题吗?
|
1
|
|
注意:Python3里默认得是Unicode。
英文八进制的简写oct()
英文十六进制的简写hex()
习题:
怎么用16进制表示186
|
1
2
3
|
128 64 32 16 8 4 2 11 0 1 1 1 0 1 0B A |
python3
所有字符在内存里都是unicode
解释器读取文件的默认编码是utf-8
但是有个文件,编码是gbk,读到内存里,还是需要解码
数据类型初识:
1、数字
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
long(长整型)
跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
float(浮点型)
先扫盲 http://www.cnblogs.com/alex3714/articles/5895848.html
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
complex(复数)
复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
注:Python中存在小数字池:-5 ~ 257
万恶的字符串拼接:
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
字符串格式化输出2.7:
name = "alex"
print "i am %s " % name
#输出: i am alex
字符串格式化输出3.6:
name = "alex"
print("i am %s " % name)
#输出: i am alex
PS: 字符串是 %s;整数 %d;浮点数%f
字符串常用功能:
移除空白
分割
长度
索引
切片
1 name.capitalize() 首字母大写 2 name.casefold() 大写全部变小写 3 name.center(50,"-") 输出 '---------------------Alex Li----------------------' 4 name.count('lex') 统计 lex出现次数 5 name.encode() 将字符串编码成bytes格式 6 name.endswith("Li") 判断字符串是否以 Li结尾 7 "Alex Li".expandtabs(10) 输出'Alex Li', 将 转换成多长的空格 8 name.find('A') 查找A,找到返回其索引, 找不到返回-1
1 format : 2 >>> msg = "my name is {}, and age is {}" 3 >>> msg.format("alex",22) 4 'my name is alex, and age is 22' 5 >>> msg = "my name is {1}, and age is {0}" 6 >>> msg.format("alex",22) 7 'my name is 22, and age is alex' 8 >>> msg = "my name is {name}, and age is {age}" 9 >>> msg.format(age=22,name="ale") 10 'my name is ale, and age is 22' 11 format_map 12 >>> msg.format_map({'name':'alex','age':22}) 13 'my name is alex, and age is 22' 14 15 16 msg.index('a') 返回a所在字符串的索引 17 '9aA'.isalnum() True 18 19 '9'.isdigit() 是否整数 20 name.isnumeric 21 name.isprintable 22 name.isspace 23 name.istitle 24 name.isupper 25 "|".join(['alex','jack','rain']) 26 'alex|jack|rain' 27 28 29 maketrans 30 >>> intab = "aeiou" #This is the string having actual characters. 31 >>> outtab = "12345" #This is the string having corresponding mapping character 32 >>> trantab = str.maketrans(intab, outtab) 33 >>> 34 >>> str = "this is string example....wow!!!" 35 >>> str.translate(trantab) 36 'th3s 3s str3ng 2x1mpl2....w4w!!!' 37 38 msg.partition('is') 输出 ('my name ', 'is', ' {name}, and age is {age}') 39 40 >>> "alex li, chinese name is lijie".replace("li","LI",1) 41 'alex LI, chinese name is lijie' 42 43 msg.swapcase 大小写互换 44 45 46 >>> msg.zfill(40) 47 '00000my name is {name}, and age is {age}' 48 49 50 51 >>> n4.ljust(40,"-") 52 'Hello 2orld-----------------------------' 53 >>> n4.rjust(40,"-") 54 '-----------------------------Hello 2orld' 55 56 57 >>> b="ddefdsdff_哈哈" 58 >>> b.isidentifier() #检测一段字符串可否被当作标志符,即是否符合变量命名规则 59 True
4、列表
创建列表:
name_list = ['alex', 'seven', 'eric']
或
name_list = list(['alex', 'seven', 'eric'])
基本操作:
索引
切片


1 >>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] 2 >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 3 ['Tenglan', 'Eric', 'Rain'] 4 >>> names[1:-1] #取下标1至-1的值,不包括-1 5 ['Tenglan', 'Eric', 'Rain', 'Tom'] 6 >>> names[0:3] 7 ['Alex', 'Tenglan', 'Eric'] 8 >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 9 ['Alex', 'Tenglan', 'Eric'] 10 >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 11 ['Rain', 'Tom', 'Amy'] 12 >>> names[3:-1] #这样-1就不会被包含了 13 ['Rain', 'Tom'] 14 >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 15 ['Alex', 'Eric', 'Tom'] 16 >>> names[::2] #和上句效果一样 17 ['Alex', 'Eric', 'Tom']
追加
1 >>> names 2 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy'] 3 >>> names.append("我是新来的") 4 >>> names 5 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的']
插入
1 >>> names 2 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 3 >>> names.insert(2,"强行从Eric前面插入") 4 >>> names 5 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 6 7 >>> names.insert(5,"从eric后面插入试试新姿势") 8 >>> names 9 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
修改
1 >>> names 2 ['Alex', 'Tenglan', '强行从Eric前面插入', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的'] 3 >>> names[2] = "该换人了" 4 >>> names 5 ['Alex', 'Tenglan', '该换人了', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的']
删除
1 >>> del names[2] 2 >>> names 3 ['Alex', 'Tenglan', 'Eric', 'Rain', '从eric后面插入试试新姿势', 'Tom', 'Amy', '我是新来的'] 4 >>> del names[4] 5 >>> names 6 ['Alex', 'Tenglan', 'Eric', 'Rain', 'Tom', 'Amy', '我是新来的'] 7 >>> 8 >>> names.remove("Eric") #删除指定元素 9 >>> names 10 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', '我是新来的'] 11 >>> names.pop() #删除列表最后一个值 12 '我是新来的' 13 >>> names 14 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy']
扩展
1 >>> names 2 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy'] 3 >>> b = [1,2,3] 4 >>> names.extend(b) 5 >>> names 6 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
拷贝
1 >>> names 2 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3] 3 4 >>> name_copy = names.copy() 5 >>> name_copy 6 ['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计
1 >>> names 2 ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] 3 >>> names.count("Amy") 4 2
获取下标
1 >>> names 2 ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1'] 3 >>> names.index("Amy") 4 2 #只返回找到的第一个下标
排序&翻转
1 >>> names 2 ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] 3 >>> names.sort() #排序 4 Traceback (most recent call last): 5 File "<stdin>", line 1, in <module> 6 TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 7 >>> names[-3] = '1' 8 >>> names[-2] = '2' 9 >>> names[-1] = '3' 10 >>> names 11 ['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3'] 12 >>> names.sort() 13 >>> names 14 ['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] 15 16 >>> names.reverse() #反转 17 >>> names 18 ['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
长度
循环
包含
列表的复制:
|
1
2
3
4
5
6
7
8
9
|
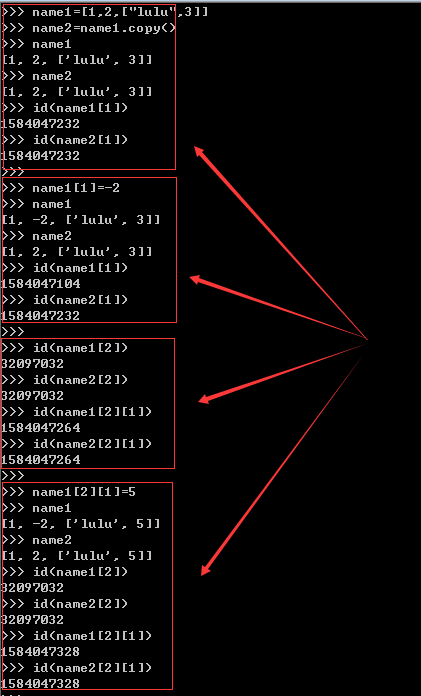
account = { 'name':'alex', 'id':1234, 'info':[200,10]}account2 = account.copy()account2['name'] = "骗子"account["info"][1] += 30print(account,account2) |
注:查看内存地址变化
字典:
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。
语法:
1 info = { 2 'stu1101': "TengLan Wu", 3 'stu1102': "LongZe Luola", 4 'stu1103': "XiaoZe Maliya", 5 }
字典的特性:
- dict是无序的
- key必须是唯一的,so 天生去重
增加
1 >>> info["stu1104"] = "苍井空" 2 >>> info 3 {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
修改
1 >>> info['stu1101'] = "武藤兰" 2 >>> info 3 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
删除
1 >>> info 2 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'} 3 >>> info.pop("stu1101") #标准删除姿势 4 '武藤兰' 5 >>> info 6 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 7 >>> del info['stu1103'] #换个姿势删除 8 >>> info 9 {'stu1102': 'LongZe Luola'} 10 >>> 11 >>> 12 >>> 13 >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 14 >>> info 15 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} #随机删除 16 >>> info.popitem() 17 ('stu1102', 'LongZe Luola') 18 >>> info 19 {'stu1103': 'XiaoZe Maliya'}
查找
1 >>> info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'} 2 >>> 3 >>> "stu1102" in info #标准用法 4 True 5 >>> info.get("stu1102") #获取 6 'LongZe Luola' 7 >>> info["stu1102"] #同上,但是看下面 8 'LongZe Luola' 9 >>> info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None 10 Traceback (most recent call last): 11 File "<stdin>", line 1, in <module> 12 KeyError: 'stu1105'
多级字典嵌套及操作
1 av_catalog = { 2 "欧美":{ 3 "www.youporn.com": ["很多免费的,世界最大的","质量一般"], 4 "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], 5 "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], 6 "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] 7 }, 8 "日韩":{ 9 "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] 10 }, 11 "大陆":{ 12 "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] 13 } 14 } 15 16 av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" 17 print(av_catalog["大陆"]["1024"]) 18 #ouput 19 ['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
其他姿势
1 #values 2 >>> info.values() 3 dict_values(['LongZe Luola', 'XiaoZe Maliya']) 4 5 #keys 6 >>> info.keys() 7 dict_keys(['stu1102', 'stu1103']) 8 9 10 #setdefault 11 >>> info.setdefault("stu1106","Alex") 12 'Alex' 13 >>> info 14 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 15 >>> info.setdefault("stu1102","龙泽萝拉") 16 'LongZe Luola' 17 >>> info 18 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 19 20 21 #update 22 >>> info 23 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 24 >>> b = {1:2,3:4, "stu1102":"龙泽萝拉"} 25 >>> info.update(b) 26 >>> info 27 {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} 28 29 #items 30 info.items() 31 dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')]) 32 33 34 #通过一个列表生成默认dict,有个没办法解释的坑,少用吧这个 35 >>> dict.fromkeys([1,2,3],'testd') 36 {1: 'testd', 2: 'testd', 3: 'testd'}
循环dict
1 #方法1 2 for key in info: 3 print(key,info[key]) 4 5 #方法2 6 for k,v in info.items(): #会先把dict转成list,数据里大时莫用 7 print(k,v)
数据运算:
布尔运算:
|
1
2
3
4
5
6
|
bool运算,以下情况都为False:[] 空列表{} 空字典() 空元组,空集合''空字符0 |
三元运算:
三元运算是if-else 语句的快捷操作,也被称为条件运算。可以让代码更加紧凑,更加美观。
|
1
2
3
|
[on_true] if [expression] else [on_false]x, y = 50, 25small = x if x < y else y |
字符串常用方法:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
strip()center()count()find()lower 或者 casefoldupperjoinsplitendswithstartswithreplaceindex |
元组:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
跟列表一样,但是它是只读列表。dir()把传入的数据类型的,所有方法以列表的形式返回。names = ("lulu1","lulu2")>>> names('aa', 'bb')>>> names[1] = "cc"Traceback (most recent call last): File "<stdin>", line 1, in <module>TypeError: 'tuple' object does not support item assignment类型错误 元组: 对象 不支持 元素 指定 |
元组的作用?
明确的表示,元组里存储的数据是不能被修改的
list(tuple元组)变成列表
tuple(list列表)变成元组
cmd查看帮助方法:
names=("aa","bb")
(1)help(names)
(2)dir(names) #下划线的不会用。
集合:set
|
1
2
3
4
5
6
|
关系测试 交集 两个都有 差集 在列表a里有,b里没有 并集 把两个列表里的元素,合并在一起,去重去重,天然去重集合也是无序的 |
数据类型:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
str # 它只是人类可读的抽象的表示形式intfloatboollisttupledictsetbytes 字节类型(二进制类型),就是一个8bits字节 所有的字符要存在内存里,硬盘里,都是bytes格式在py2里,你看到的字符串,就是bytes str==bytesstr == bytesunicode在py3里 str == unicode bytes == bytes |