近几年,视频编解码技术在理论及应用方面都取得了重大的进展,越来越多的人想要了解编解码技术。因此,网易云信研发工程师为大家进行了归纳梳理,从理论及实践两个方面简单介绍视频编解码技术。
相关阅读推荐
1、视频介绍
视频的本质是图像序列,根据视觉暂留的原理,每秒播放20~25张图像,就会形成连续平滑的视觉效果,人眼将无法区分其中单幅的图像,就这样连续的画面叫做视频。每秒播放的图像数量叫作帧率。图像是由像素构成的,在彩色图像中,每个像素由R、G、B三个分量构成,每个分量用一个字节存储。分辨率用于描述图像的尺寸,例如分辨率1280x720就表示图像宽度是1280个像素、高度是720个像素。
2、压缩视频的原因
为什么要对视频进行压缩?假如有一段时长为60秒视频,它的分辨率是1280x720,帧率是25,那么这段视频的大小等于:60 x 25 x 1280 x 720 x 3 = 4147200000字节,大约是3955MB,如此庞大的数据,如果不进行压缩,那么磁盘空间将会很快被占满。
多媒体数据占了互联网数据量的80%以上,其中大部分都是图像视频数据,未压缩之前的视频非常庞大,不利于存储和传输,因此很有必要对视频进行压缩,视频压缩也叫作视频编码,它利用视频中存在的空间冗余和时间冗余,剔除人眼不敏感的信息,达到数据压缩的目的。
3、视频压缩的依据
视频能够进行压缩的根本原因是信息冗余,视频中存在两种冗余信息:
(1) 空间冗余。对于视频的每一帧图像,在一定尺度范围内,像素的变化是非常平缓的,像素之间非常相似,这就是空间冗余。
(2) 时间冗余。视频是由连续变化的图像构成的,在一个很短的时间内,相邻图像之间的变化很小,因此相邻图像很相似,这就是时间冗余。
4、视频编码的原理和细节
由于视频中存在大量的信息冗余,想要对视频进行压缩,就必须找到去除冗余信息的方法,标准的视频编码过程包含下面几个步骤:
(1) 预测编码。所谓预测就是利用前面像素值来推算当前的像素值。根据前面的知识我们知道,在空间或者时间上相邻的像素是很相似,因此只要预测方法合适,预测值和实际值会很接近,假设当前像素的实际值是X,预测值是P,那么X和P之间的残差A=X-P。如果我们只对残差数据进行编码,那么将会大大压缩数据量。这就是预测编码的原理。预测编码可以分为空间预测(帧内预测)和时间预测(帧间预测)两种。预测编码可以分为下面几个步骤:
- 利用前面已经编码并重构像素块预测当前像素块的值
- 求当前像素和预测像素的差值
- 对像素差值进行编码
- 把编码后的数据传输到解码端,在解码端按照同样的方法对像素值进行预测,再加上残差,就可以重构得到原始图像了。
为了得到最佳的预测值,编码器通常需要使用不同预测方法进行预测,然后根据某个评判标准(一般是SAD、STAD、RDO等)得到最优的预测值(注意不是预测值越接近实际值就越优,所谓最优是计算复杂度、失真和码率之间的综合考量),特别对于帧间预测来说,在预测的时候要在参考帧中找到当前块的匹配块,需要大量的计算,因此预测模块一般是编码器中计算量最大的模块,而预测方法的好坏也直接决定了视频的压缩率。
(2) 变换编码。变化编码本身不会对数据进行压缩,变换的目的是把空域信息转换为频域信息,去除了信息之间的相关性,在接下来的编码操作中可以得到更高的压缩比,变化编码是为下一步的量化编码做准备的。在视频编码中常见的变换方法是DCT变换和哈达玛变换。
(3) 量化编码。量化是视频产生失真的根本原因。经过预测编码、变换编码之后得到的数据被称为变换系数,虽然变换系数相对于原始数据数来说已经很小了,但是系数值的变化范围仍然很大,利用量化把变换系数的连续取值转换成有限的离散值,这样可大大提高压缩率。假设有这样一组数据[16,96,100,600,50],量化参数是25,那么量化之后数据是round([16 / 25, 96 / 25, 100 / 24, 600 / 25, 50 / 25]) = [0,4,4,24,2],可以看到,量化之前的数据范围是16~600,需要大量的比特数才能表示,量化之后的数据范围是0~24,只需要少量比特数就可以表示,实现了压缩数据的目的。编码是一个不可逆的操作,它是失真产生的根本原因。
(4) 环路滤波。环路滤波和压缩没有很大关系,却和视频的画面质量有很大关系。视频编码是以块为单位进行的,在经过量化模块时,可能每个块选择的量化系数不同,导致每个块产生的失真不一样,造成像素块的边界不连续,因此人眼观看视频的时会有方块效应(也就是有很多马赛克现象)。为了提高视频质量,有必要对方块效应进行消除,这就是环路滤波模块的功能。经过量化操作之后的数据块,再经过反量化、反变换,然后进行重构,接着进入去方块滤波进行去方块操作,得到的像素块就可以作为参考像素块给预测模块使用。环路滤波是一个可选模块。
(5) 熵编码。熵编码的目的是去除统计冗余,实现数据的进一步压缩。这么说可能有点抽象,举个例子,假设有这样一组数据[0,4,4,24,2],如果使用定长编码来进行编码,这段数据可以表示为[00000,00100,00100,11000,00010],每个数据需要5 bit来表示,这段数据的总长度是5 bit x 5=25 bit;如果我们使用哈夫曼来编码,这个数组中每个元素概率值分别如下:数值0的概率是20%,数值4的概率是40%,数值24的概率是20%,数值2的概率是20%,即[20%,40%,20%,20%],根据每个元素的概率构造哈夫曼树(节点中括号内的是数组元素值),如下图所示,因此这段数据可以表示为[0,10,110,111],数据的总长度是11 bit。
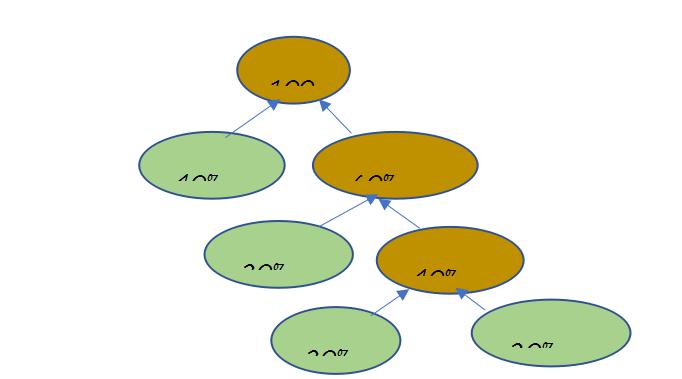
由此可见使用哈夫曼编码可以去除统计冗余,实现数据压缩的目的,哈夫曼编码就是一种熵编码方法,但是由于哈夫曼编码对错误非常敏感,不适合实际应用,因此实际应用中通常使用变长编码(CAVLC)和算术编码(CABAC)作为熵编码算法。算术编码利用一个0到1之间的浮点数来描述一个信号序列,然后用这个浮点数来表示这个信号序列,极大的压缩了数据。算术编码可以使用一个简单的例子说明,假设有一个二进制串“10101110”,符号0和1的概率值都是50%,算术编码的过程如下:
(1) 设置定一个区间,通常这个区间我们设定为[0,1),然后使用low指向区间的下界,用high指向区间的上界,现在low指向0,rhigh指向1.
(2) 输入每一个符号,按照符号的不同对low和high进行调整,调整方法如下面公式所示,最后把low指向的浮点数作为这个符号串的码字,表示这个二进制串,可以看到算术编码的压缩效率比哈夫曼编码高很多,在x264中使用CABAC(上下文自适应的二进制算数编码)作为熵编码算法。

以上就是编解码技术的基础知识介绍,该系列第二篇文章将会介绍视频编解码技术的实践。
更多即时通讯、音视频技术的干货文章,请关注网易云信博客。