卡尔曼的历史不讲了...
网上写卡尔曼滤波器的太多了...而且大(yi)多(mu)雷(yi)同(yang),所以,我也不知道谁是第一稿,谁是转载者,这里...我也是参考别人的博文。将卡尔曼滤波器用在了一个GPS的小程序里,最简单的一维模型...
首先,我们先要引入一个离散控制过程的系统。该系统可用一个线性随机微分方程(Linear Stochastic Difference equation)来描述:
X(k)=A*X(k-1)+B*U(k)+W(k)
再加上系统的测量值:
Z(k)=H*X(k)+V(k)
上两式子中,X(k)是k时刻的系统状态,U(k)是k时刻对系统的控制量。A和B是系统参数,对于多模型系统,他们为矩阵。Z(k)是k时刻的测量值,H是测量系统的参数,对于多测量系统,H为矩阵。W(k)和V(k)分别表示过程和测量的噪声。他们被假设成高斯白噪声(White Gaussian Noise),他们的covariance 分别是Q,R(这里我们假设他们不随系统状态变化而变化)。
对于满足上面的条件(线性随机微分系统,过程和测量都是高斯白噪声),卡尔曼滤波器是最优的信息处理器。下面我们来用他们结合他们的covariances 来估算系统的最优化输出。
利用系统的过程模型,来预测下一状态的系统。假设现在的系统状态是k,根据系统的模型,可以基于系统的上一状态而预测出现在状态:
X(k|k-1)=A X(k-1|k-1)+B U(k) (1)
式(1)中,X(k|k-1)是利用上一状态预测的结果,X(k-1|k-1)是上一状态最优的结果,U(k)为现在状态的控制量,如果没有控制量,它可以为0。
到现在为止,我们的系统结果已经更新了,可是,对应于 X(k|k-1)的covariance(协方差)还没更新。我们用P表示covariance:
P(k|k-1)=A P(k-1|k-1) A’+Q (2)
式(2)中,P(k|k-1)是X(k|k-1)对应的covariance,P(k-1|k-1)是X(k-1|k-1)对应的 covariance,A’表示A的转置矩阵,Q是系统过程的covariance。式子1,2就是卡尔曼滤波器5个公式当中的前两个,也就是对系统的预测。
现在我们有了现在状态的预测结果,然后我们再收集现在状态的测量值。结合预测值和测量值,我们可以得到现在状态(k)的最优化估算值X(k|k):
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-H X(k|k-1)) (3)
其中Kg为卡尔曼增益(Kalman Gain):
Kg(k)= P(k|k-1) H’ / (H P(k|k-1) H’ + R) (4)
到现在为止,我们已经得到了k状态下最优的估算值 X(k|k)。但是为了要另卡尔曼滤波器不断的运行下去直到系统过程结束,我们还要更新k状态下X(k|k)的covariance:
P(k|k)=(I-Kg(k) H)P(k|k-1) (5)
其中I 为1的矩阵,对于单模型单测量,I=1。当系统进入k+1状态时,P(k|k)就是式子(2)的P(k-1|k-1)。这样,算法就可以自回归的运算下去。
GPS测量系统建模:
物体具有惯性,系统认为物体前一时刻和后一时刻的GPS定位坐标相同,所以A=1。没有控制量,所以U(k)=0。得到:
X(k|k-1)=X(k-1|k-1) (6)
公式(2)改写成:
P(k|k-1)=P(k-1|k-1) +Q (7)
因为GPS的测量值直接获得,所以H=1。公式(3)(4)(5)改写成:
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-X(k|k-1)) (8)
Kg(k)= P(k|k-1) / (P(k|k-1) + R) (9)
P(k|k)=(1-Kg(k))P(k|k-1) (10)
为了令卡尔曼滤波器开始工作,我们需要告诉卡尔曼两个零时刻的初始值,是X(0|0)和P(0|0)。
代码:
clear
clc;
CON = 0;%初始值
tmp_y = importdata('kalman.txt');%此时importdata 读出为列数据
y = tmp_y';
N = length(y);%由于输入长度发生变化,N值需要修改
x = zeros(1,N);
x(1) = 0;
p = 10;
Q = 0.1*cov(randn(1,N));%过程噪声协方差
R = 100*cov(randn(1,N));%观测噪声协方差
for k = 2 : N
x(k) = x(k - 1);%预估计k时刻状态变量的值
p = p + Q;%对应于预估值的协方差
kg = p / (p + R);%kalman gain
x(k) = x(k) + kg * (y(k) - x(k));
p = (1 - kg) * p;
end
fid1=['Kal_output','.txt'];
c=fopen(fid1,'w');
fprintf(c,'%f\n',x);
fclose(c);
t=1:N;
figure(1);
expValue = zeros(1,N);
for i = 1: N
expValue(i) = CON;
end
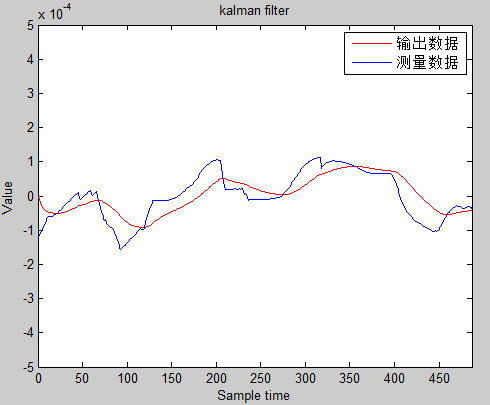
plot(t,x,'r',t,y,'b');
legend('输出数据','测量数据');
axis([0 N -0.0005 0.0005])
xlabel('Sample time');
ylabel('Value');
title('kalman filter');
效果: