看到一个题目,问冒泡排序和选择排序的区别,我发现我好像忘了,所以来回顾一下。
冒泡排序
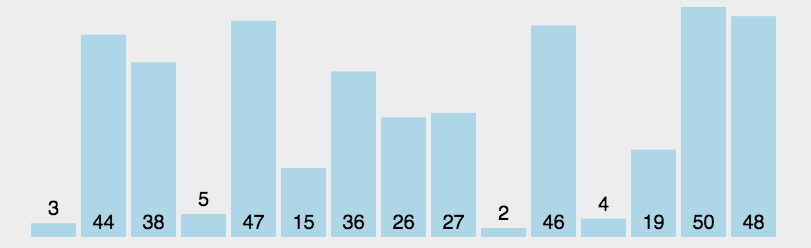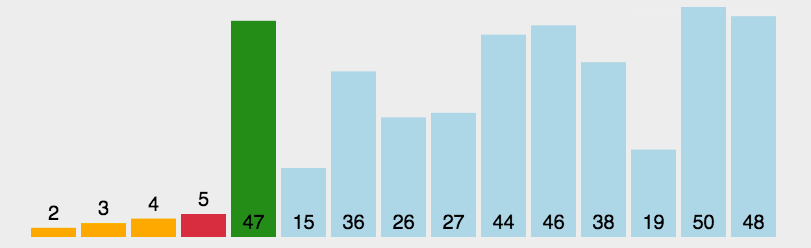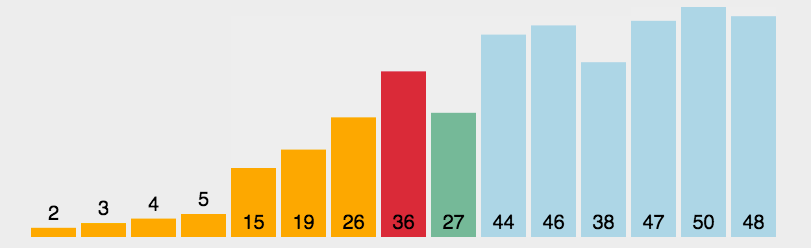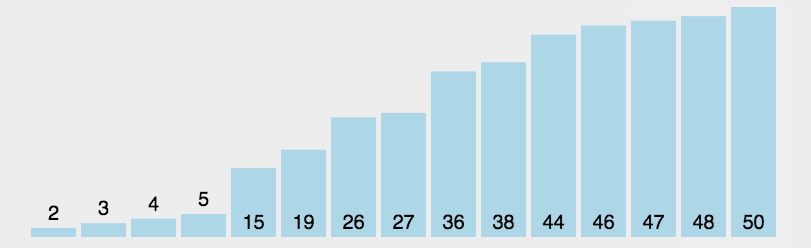
L=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48]
要将列表L里的15个元素进行从小到大排序,用冒泡排序的过程是:
列表有n个元素,则应比较n-1轮,第一轮比较n-1次,第一次将列表的第一个元素和第二个元素相比,如果第一个大于第二个,则两个元素交换位置,将较大的那个排在后面。第二次将第二个元素和第三个元素相比,将大的放在后面,以此类推,第一轮结束后最大的那个数排到了最后,可以不管了,第二轮只需要比较n-1个数,共比较n-2次,以此类推。故只需写两个for循环,第一个for控制轮数,第二个for控制每轮的次数即可。
L=[3,44,38,5,47,15,36,26,27,2,46,4,19,50,48] def bubble_sort(list): for i in range(len(list) - 1): # 轮数 for j in range(len(list) - 1 - i): # 每轮次数 if list[j] > list[j + 1]: list[j], list[j + 1] = list[j + 1], list[j] return list print(bubble_sort(L))
排序动态过程:
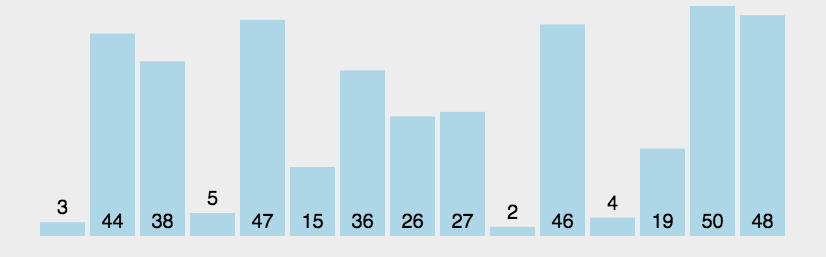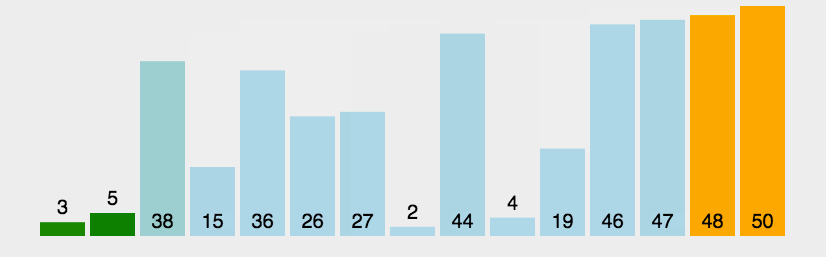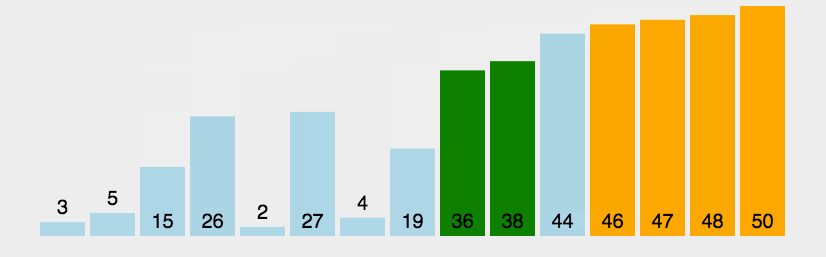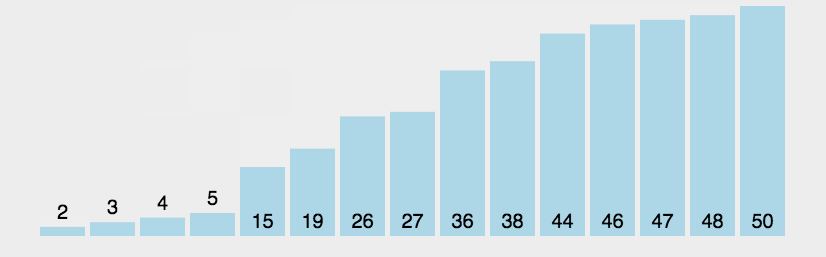
选择排序
选择排序的原理跟冒泡排序有些不同。它是通过自定义的最小值元素的下标在内层循环进行比较, 如果发现比自定义最小值元素下标还要小的值,则将该值的下标赋值给自定义的最小值元素下标,即最小值元素的宝座让位了。在比较的过程中不移动元素的位置,在一轮内层循环结束后,才会将最小值元素交换至列表的最左端。第二轮循环中的元素已经不包括第一轮产生的最小值元素了。
# 选择排序 def select_sort(list): n = len(list) for i in range(n-1): # 比较轮数n-1 min_index = i # 假设每轮开始第一个元素值最小 for j in range(i+1,n): # 每轮比较次数n-1-i if list[j] < list[min_index]: min_index = j # 最小值元素的下标变为j list[i], list[min_index] = list[min_index], list[i] # 每轮结束之后最小值置首 select_sort(L) print(L)
排序动态过程:
相比较而言,冒泡排序有着更多的比较操作,在性能优化和执行效率方面不及选择排序。然而在稳定性方面,选择排序是不稳定的,而冒泡排序是稳定的。如列表[1,3,3,2],第一个3跟2交换后就造成了两个3 的位置在整个列表中颠倒了,破坏了原有的秩序,这就是不稳定的体现。
| 算法 | 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n2) | O(n) | O(n2) | O(1) | 稳定 |
| 选择排序 | O(n2) | O(n2) | O(n2) | O(1) | 不稳定 |