在学接口自动化测试时, 需要从excel中读取测试用例的数据, 假如我的数据是这样的:
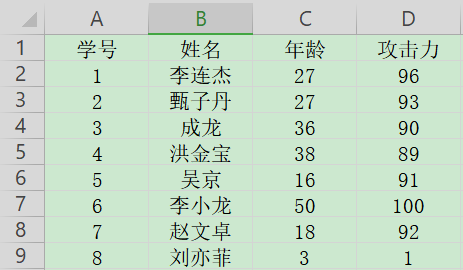
最好是每行数据对应着一条测试用例, 为方便取值, 我选择使用pandas库, 先安装 pip install pandas.
然后导入:
1 import pandas as pd 2 df=pd.read_excel('../test_data/test_data.xlsx',sheet_name='hehe')
默认第一行数据是表头,先来简单了解一下pandas的用法:
输入:
1 print(df.head()) # 矩阵式输出,无法利用数据,忽略 2 print(df.ix[0]) # 索引从第二行开始,0表示表中的第二行,表头与行数据成映射关系
输出:
学号 姓名 年龄 攻击力
0 1 李连杰 27 96
1 2 甄子丹 27 93
2 3 成龙 36 90
3 4 洪金宝 38 89
4 5 吴京 16 91
学号 1
姓名 李连杰
年龄 27
攻击力 96
输入:
1 print(df.ix[0,1]) # 第二行第二个数据,B2 2 print(df.ix[1].values) # 第3行数据 3 print(df.ix[[1,2]].values) # 第3,4行数据,注意输出多行里面应该要嵌套列表
输出:
李连杰
[2 '甄子丹' 27 93]
[ [2 '甄子丹' 27 93]
[3 '成龙' 36 90] ]
输入:
print(df.ix[[1,2],['年龄']].values) #3,4行里输出表头为'年龄'的列的数据,嵌套列表 print(df.ix[:,['攻击力']].values) # 输出所有行的表头为'攻击力'的列的数据,即D2-D9,嵌套列表 print(df.ix[:].values) # 输出所有行 print(df.values) # 输出所有行,结果与上一样
输出:
[[27]
[36]]
[[ 96]
[ 93]
[ 90]
[ 89]
[ 91]
[100]
[ 92]
[ 1]]
[[1 '李连杰' 27 96]
[2 '甄子丹' 27 93]
[3 '成龙' 36 90]
[4 '洪金宝' 38 89]
[5 '吴京' 16 91]
[6 '李小龙' 50 100]
[7 '赵文卓' 18 92]
[8 '刘亦菲' 3 1]]
输入:
1 print(df.index.values) # 输出行号 2 print(df.columns.values) # 输出所有列标题 3 print(df['年龄'].values) #输出指定标题列的数据 4 print(df.sample(3).values) #随机输出三行数据
输出:
[0 1 2 3 4 5 6 7]
['学号' '姓名' '年龄' '攻击力']
[27 27 36 38 16 50 18 3]
[[3 '成龙' 36 90]
[6 '李小龙' 50 100]
[7 '赵文卓' 18 92]]
输入:
1 print(df.ix[1,['学号','年龄']].to_dict()) # 字典的形式输出第三行特定列
输出:
{'学号': 2, '年龄': 27}
有表头的情况下, 输出的数据若有多个元素,都是<class 'numpy.ndarray'>的类型的,即[[] [] [] []],大列表嵌套多个小列表,小列表之间没有逗号隔开, 输出的数据若只有一个元素,那就是str或者int.
然而, 在自动化测试中我们需要的可能是这样的数据:
[{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}]
即大列表嵌套多字典, 每条字典就是一个测试用例的数据, 那么怎么取出这种类型的呢?
1 df=pd.read_excel('../test_data/test_data.xlsx') #默认第一个sheet 2 test_data=[] 3 for i in df.index.values:#获取行号的索引,并对其进行遍历: 4 #根据i来获取每一行指定的数据 并利用to_dict转成字典 5 row_data=df.ix[i,['学号','姓名','年龄','攻击力']].to_dict() 6 test_data.append(row_data) 7 print("最终获取到的数据是:{0}".format(test_data))
输出:
最终获取到的数据是:[{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96},
{'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93},
{'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90},
{'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89},
{'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91},
{'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100},
{'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92},
{'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}]
怎么样,大功告成了吧, 然而你会说, 好麻烦呀,有简单点的方法吗?哈哈,有!
我们来看to_dict方法:

作用是把数据格式转换成字典型的,两个参数,into不管它,前面orient有很多值,我先输出几个看看:
1 import pandas as pd 2 p=pd.read_excel('../test_data/test_data.xlsx') 3 4 print("orient='list'-->",p.to_dict(orient='list')) # <class 'dict'>将表头作为key,将每列的值放在列表中,将列表作为value 5 print("orient='index'-->:",p.to_dict(orient='index')) # 将行的索引值作为key,将存放数据的字典作为value 6 print("orient='records'-->",p.to_dict(orient='records')) # 大列表嵌套多字典,适合测试用例 7 print(p.to_dict(orient='dict')) 8 print(p.to_dict(orient='split'))
结果:
1 orient='list'--> {'学号': [1, 2, 3, 4, 5, 6, 7, 8], '姓名': ['李连杰', '甄子丹', '成龙', '洪金宝', '吴京', '李小龙', '赵文卓', '刘亦菲'], '年龄': [27, 27, 36, 38, 16, 50, 18, 3], '攻击力': [96, 93, 90, 89, 91, 100, 92, 1]} 2 orient='index'-->: {0: {'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, 1: {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}, 2: {'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90}, 3: {'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89}, 4: {'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91}, 5: {'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100}, 6: {'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92}, 7: {'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}} 3 orient='records'--> [{'学号': 1, '姓名': '李连杰', '年龄': 27, '攻击力': 96}, {'学号': 2, '姓名': '甄子丹', '年龄': 27, '攻击力': 93}, {'学号': 3, '姓名': '成龙', '年龄': 36, '攻击力': 90}, {'学号': 4, '姓名': '洪金宝', '年龄': 38, '攻击力': 89}, {'学号': 5, '姓名': '吴京', '年龄': 16, '攻击力': 91}, {'学号': 6, '姓名': '李小龙', '年龄': 50, '攻击力': 100}, {'学号': 7, '姓名': '赵文卓', '年龄': 18, '攻击力': 92}, {'学号': 8, '姓名': '刘亦菲', '年龄': 3, '攻击力': 1}] 4 {'学号': {0: 1, 1: 2, 2: 3, 3: 4, 4: 5, 5: 6, 6: 7, 7: 8}, '姓名': {0: '李连杰', 1: '甄子丹', 2: '成龙', 3: '洪金宝', 4: '吴京', 5: '李小龙', 6: '赵文卓', 7: '刘亦菲'}, '年龄': {0: 27, 1: 27, 2: 36, 3: 38, 4: 16, 5: 50, 6: 18, 7: 3}, '攻击力': {0: 96, 1: 93, 2: 90, 3: 89, 4: 91, 5: 100, 6: 92, 7: 1}} 5 {'index': [0, 1, 2, 3, 4, 5, 6, 7], 'columns': ['学号', '姓名', '年龄', '攻击力'], 'data': [[1, '李连杰', 27, 96], [2, '甄子丹', 27, 93], [3, '成龙', 36, 90], [4, '洪金宝', 38, 89], [5, '吴京', 16, 91], [6, '李小龙', 50, 100], [7, '赵文卓', 18, 92], [8, '刘亦菲', 3, 1]]}
发现我们测试需要的数据格式也在其中, 那就是orient='records', 所以两行代码解决了从excel中取出测试数据的事情, 好开心!
1 p=pd.read_excel('../test_data/test_data.xlsx') 2 print(p.to_dict(orient='records'))
取出数据测试完毕后想写回测试结果该怎么办呢,这就要谈谈另一个模块了:openpyxl
这里我把读取数据写成一个类, 利用openpyxl也可以拿出大列表嵌套多字典的数据类型, 但稍微麻烦了点, 不过它还可以写回数据. 如下:
1 from openpyxl import load_workbook 2 from tools.read_config import ReadConfig 3 4 class ReadExcel: 5 button = ReadConfig().read_config('case.config','MOD','button') 6 def read_excel_openpyxl(self,file_name,sheet_name): 7 '''从excel读取数据并以大列表嵌套多字典的形式输出''' 8 wb=load_workbook(file_name) 9 sheet=wb[sheet_name] 10 tit = [] 11 test_data = [] 12 row = sheet.max_row + 1 13 column = sheet.max_column + 1 14 for i in range(1, row): 15 ele = {} 16 for j in range(1, column): 17 if i == 1: 18 res = sheet.cell(i, j).value 19 tit.append(res) 20 else: 21 ele[tit[j - 1]] = sheet.cell(i, j).value 22 test_data.append(ele) # 此时的test_data里面第一个是空列表 23 24 test_data_new = [] 25 for item in test_data: 26 if item != {}: # 去除空列表 27 test_data_new.append(item) 28 return self.get_which_row(test_data_new) 29 30 def write_back_unittest(self,file_name,sheet_name,value,row,cloumn): 31 '''unittest框架用这个''' 32 wb=load_workbook(file_name) 33 sheet=wb[sheet_name] 34 sheet.cell(row,cloumn).value=value 35 wb.save(file_name) 36 37 def get_which_row(self,test_data_new): 38 '''根据button值决定取出哪些行的数据作为测试用例''' 39 test_data_final=[] 40 if self.button == 'all': 41 return test_data_new 42 else: 43 for i in eval(self.button): # 配置文件里button的值是字符串类型,切记!!! 44 test_data_final.append(test_data_new[i-1]) 45 return test_data_final
END