在学python3.7的open函数时,我发现在pycharm里新建一个file_name.txt文本文件,输入中文保存,再用open(file_name,'r+')打开,再去读写时出现了一些小问题。利用Notepad和EditPlus进行多轮控制变量测试后,总结如下:
1、当原文件为utf8编码格式,且不包含中文,则对其进行读操作,正常;对其进行写操作(非中文),正常,文件编码格式不变;
当写入中文字符时,文件编码格式变为gbk,此时pycharm中的文件会将你输入的中文显示为16进制数,并会提示你用gbk编码reload文件。
2、当原文件为utf8编码格式,若包含中文,此时对其进行读操作,则可能报错UnicodeDecodeError,也可能不报错。是否报错跟中文内容有关。
写入中文情况与1相同。
如,新建一个文件file4.txt,里面写入"你好"两个汉字,然后去读它:

结果为:
为什么是 " 浣 犲 ソ " 这三个陌生的玩意呢?查看“你好”的utf8编码16进制表示:
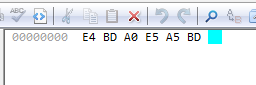
再查看这三个字符的GBK编码16进制表示:
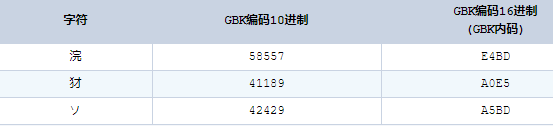
瞬间明白了:open函数用GBK解码了被UTF-8编码的file4文件。前者用两个字节表示一个汉字而后者用三个。
把“你好”换成“中国”再试一次:报错了!

注意:E4是位置0,AD是位置2
这是因为汉字“中国”的编码第三四两个字节可能没有对应的GBK编码字符,从而导致出错。

解决方法:
open的encoding默认为'gbk',可将其改为'utf-8'。
但是改后对文件进行覆盖写(r+表示可读写,光标在文件开头),有时也会出错。
如:file4.txt文件输入中英混合的:hello中国

再对其进行覆盖写:

也会报错!分析一下:
hello中国的utf8 16进制表示为:
68 65 6C 6C 6F E4 B8 AD E5 9B BD
天青色的utf8 16进制表示为:
E5 A4 A9 E9 9D 92 E8 89 B2
覆盖写入天青色后变成:
E5 A4 A9 E9 9D 92 E8 89 B2 9B BD
还剩两个字节 9B BD找不到对应的字符,自然就报错了:

注意:报错之后文件由utf-8编码转为ASCII编码。
暂时还没找到解决办法,追加写或清空写不会出现这种报错。
----------------------------------------------------------------------华丽的分割线-----------------------------------------------------------------------------
顺便补充点编码知识:
Unicode编码其实只是个字符集,把全球的字符用唯一的16进制编号表示出来,这个编号就叫“码位”。最多可表示1114111个,即10FFFF。他没有规定具体怎么存储到计算机硬盘中。而UTF-8就是具体编码的体现,是将码位转化为字节序列的一套编码规则。
utf-8的规则:
1. 单字节的字符,字节的第一位设为0,如英文字母,UTF-8码只占用一个字节,和ASCII码完全相同;
2. n个字节的字符(n>1),如中文汉字,第一个字节的前n位设为1,第n+1位设为0,后面字节的前两位都设为10,这n个字节的其余空位填充该字符unicode码,高位用0补足。
U+ 0000 ~ U+ 007F: 0XXXXXXX
U+ 0080 ~ U+ 07FF: 110XXXXX 10XXXXXX
U+ 0800 ~ U+ FFFF: 1110XXXX 10XXXXXX 10XXXXXX
U+10000 ~ U+10FFFF: 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX
如:“汉”字的Unicode编码16进制表示为:6C49(它占两个字节,6C是一个字节,49是一个字节。一个字节占8比特位,6是第一个八位的前4位0110)。0x6C49在0x0800-0xFFFF之间, 使用3字节模板: 1110xxxx 10xxxxxx 10xxxxxx。将0x6C49写成二进制是: 0110 1100 0100 1001,用这个二进制数依次代替模板中的x,得到:
11100110 10110001 10001001, 即E6 B1 89。这个就是被存到计算机中的比特流。

查看字符编码的网站地址:http://www.mytju.com/classcode/tools/encode_utf8.asp