使用浏览器看到返回的数据是类似下图中的:
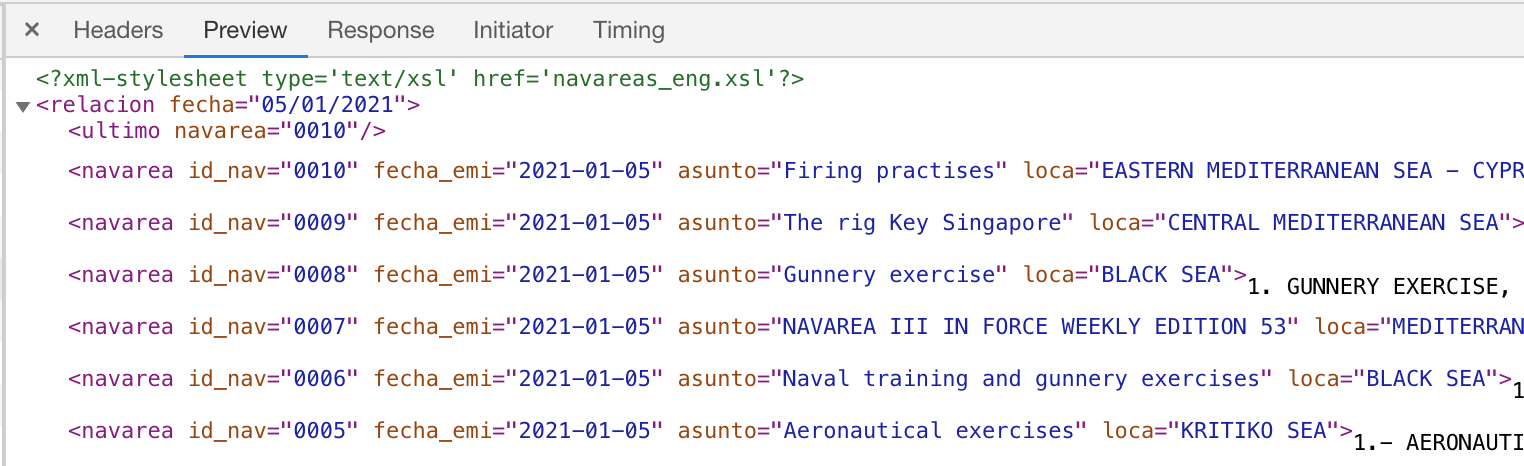
可以看到是xml格式的
解析方式:
from lxml import html
...
ret = requests.get(url, headers=headers)
tree = html.fromstring(ret.content)
navareas = tree.xpath('//relacion/navarea')
...
爬虫、机器学习、数据分析接单,请关注公众号:聚变发动机,回复接单拉你进接单群。

使用浏览器看到返回的数据是类似下图中的:
可以看到是xml格式的
解析方式:
from lxml import html
...
ret = requests.get(url, headers=headers)
tree = html.fromstring(ret.content)
navareas = tree.xpath('//relacion/navarea')
...
爬虫、机器学习、数据分析接单,请关注公众号:聚变发动机,回复接单拉你进接单群。