Visual Semantic Navigation Using Scene Priors
2018-10-21 19:39:26
Paper: https://arxiv.org/pdf/1810.06543.pdf
Demo:https://www.youtube.com/watch?v=otKjuO805dE&feature=youtu.be
本文将首先定义什么是 visual semantic navigation, 然后描述怎么利用深度强化学习的框架来解决该问题,以及该任务的 baseline model。
1. 任务的定义:
视觉语义导航(Visual Semantic Navigation),即在给定的环境中,当我们所要找的目标物体在我们的视野中,并且距离该物体比较近(低于某一阈值)。

2. The Baseline Model:
我们将该问题定义为 DRL 的框架,给定语义任务的目标 g,智能体接收到一个状态 s,然后根据策略 π 从可能的动作集合 A 中采样出一个动作 a。我们用 deep Policy network 来估计该策略。由于 visual states 和 semantic objective 来自于不同的模态,我们设计两支子网络,来将该两个输入映射到联合的特征映射中去(a joint visual-semantic feature embedding)。
Visual Network:如图2所示,该网络输入为 224*224 RGB images,产生一个 512-D 的 feature vector。所用的 backbone 网络结构是 ResNet-50,本文所提取的 feature 是经过全连接层 和 ReLU layer 之后得到的 512-D 的特征作为 visual-semantic feature。
Semantic Network:语义任务的目标是通过物体的种类来描述的,例如:微波炉,电视等等。本文用 fastText 来计算 100-D 的 embedding。然后将这些 Word embedding 映射为 512-D feature。
Actor-Critic Policy Network:我们采用 A3C 的模型来在每一个时刻进行 policy 的估计。A3C model 的输入就是联合的 current state 和 semantic task objective 的特征表示,即:1024-D feature vector。该网络产生两个输出,即:the policy and the value。我们从预测的 policy 中采样出 action。
Reward:我们考虑 reward 的设计,使其能够最小化与目标物体的轨迹长度:
如果在一定的步数之内,接近了目标种类中的任何物体,都给 agent 一个大的 positive reward 10;
否则,我们惩罚每一个 step,用一个小的 negative reward -0.01.
而对于不同类型的 action,作者也给定不同类型的 reward,即:是否是 stop action。
3. Generalization with Graph Convolutional Networks:
3.1. Knowledge graph construction:
我们的知识图谱提供了两个优势:
1). 其编码了不同物体种类之间的空间关系(the spatial relationships between different object categories)
2). 其提供了 the spatial and visual relationships between the known objects and novel categories in cases that we have not seen any visual examples of the novel categories.
我们将知识图谱表示为:G=(V, E), 其中,V 和 G 分别表示 nodes 和 edges。具体的来说,每一个节点 v 代表了 an object category, 每一个 edge e 表示了a pair of object categories 之间的关系。作者采用 Visual Genome dataset (https://link.springer.com/content/pdf/10.1007%2Fs11263-016-0981-7.pdf, Project Page:https://visualgenome.org/) 作为构建 the knowledge graph 的来源。Visual Genome consists of over 100K natural images. Each image is annotated with objects, attributes and the relationships between objects. Since there is no predefined object category list, the annotators are free to label any objects in the image, which results in very diverse object categories.

在我们的实验当中,我们构建了一个知识图谱,将所有的出现在 AI2-THOR 环境中的物体种类都囊括中该 graph 中。每一个种类表示为 graph 中的一个 node。我们计算统计了 the Visual Genome dataset 中出现的 object-to-object relationships 的次数。当两个节点之间的出现频率超过三次的时候,我们就用一条边来连接这两个节点。图3展示了部分示例,如下所示:

3.2. Incorporating Semantic Knowledge into Actor-Critic Model:

3.2.1 GCN:

3.2.2 GCN for Navigation:
这里作者就是利用 GCN 来建模多个物体词汇之间的关系,从而协助 agent 更好的感知所接触到的环境。
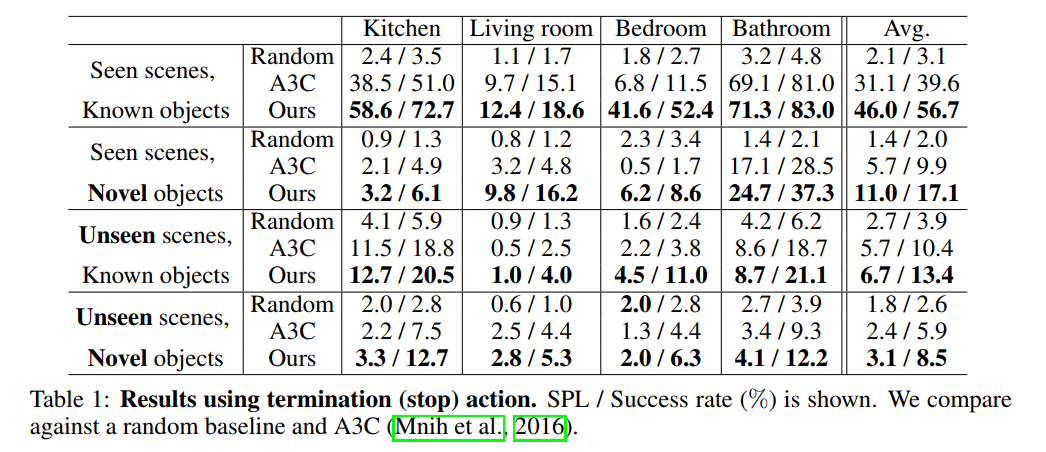
4. Experiments: