Improving Deep Visual Representation for Person Re-identification by Global and Local Image-language Association
2018-09-29 19:36:43
1. Introduction:
本文针对 person re-ID 的问题,提出利用 Natural language 来辅助进行特征的学习(仅在 training 阶段),最终测试时,仅利用学习到的图像 feature,进行 prob-gallery 的检索。示意图如下所示:
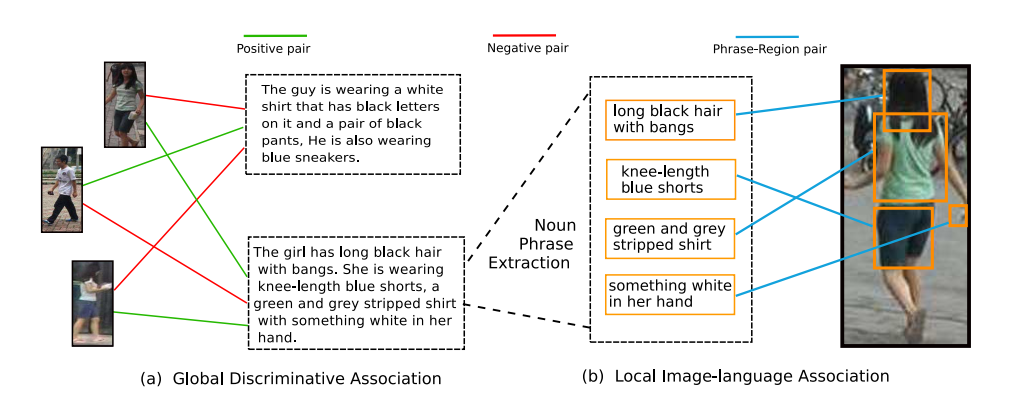
如标题所示,本文提出利用 global 的文本信息,以及 local 的单词信息来分别进行 language/phase 和 image/image patch 之间关系的学习。
在前人的工作中,也有结合其他模态的信息,来辅助提升 rgb image 的任务,如:the camera ID information, human poses, person attributes, depth maps, infrared person image。从这方面来看,学术界早已出现多模态的思路来提升某一个 task 的性能。那么,person re-ID 也不例外。本文聚焦在如何充分的利用 文本的信息来辅助提升 person re-ID 的效果。
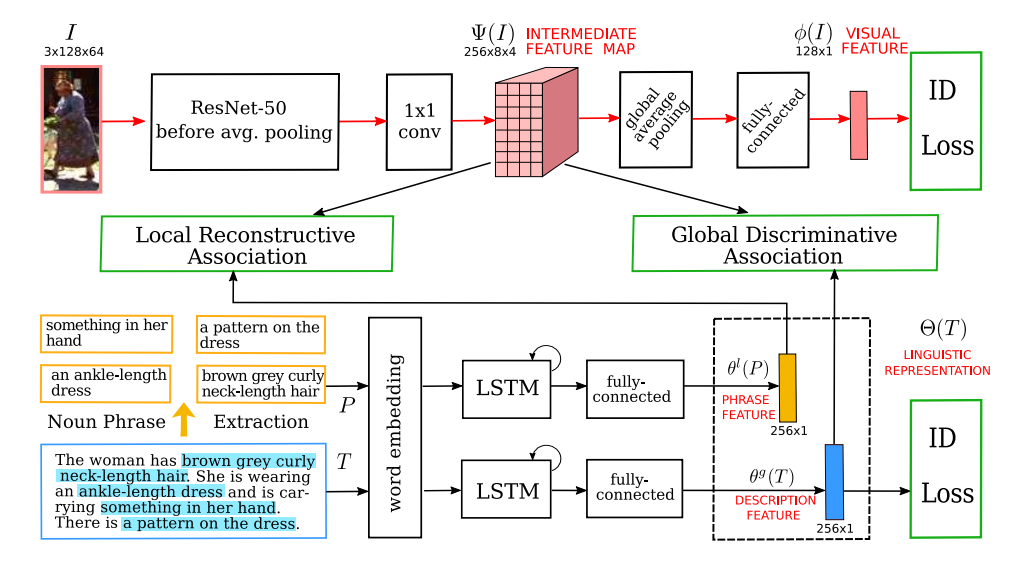
2. The Proposed Method:
(1)Visual and Linguistic Representation:
给定图像和语言描述,我们首先要进行输入的感知。
对于图像,就用 CNN 来提取 feature,得到 feature map,本文采用的是 ResNet-50,然后用 1*1 Conv 进行降维处理,得到中间的 feature map。然后用 global average pooling 进行降维后,输入到 fc layers,得到 128*1 的 visual features,此时,已经可以进行 re-ID 的训练。此处的 Loss 是 ID Loss。
对于文本,首先进行词汇的提取,然后对整个句子以及多个变长的词汇,都用 LSTM 进行编码,用最后时刻的 hidden state,表示当前文本或者词汇的特征表达。其中,词汇提取的过程,用到了 NLP 中语法树的概念,利用了 recurrsive 的思想,进行单词的有效组合,得到响应的词汇。大致过程如下所示:

作者此处也给 global 的文本信息加了一个 ID Loss,如下所示:

(2)Global Discriminative Image-language Association.
上面第一步,只是简单的对每一个模态进行了学习,但是并没有构建 image-language 之间的关联。所以,这两者之间其实可以联合的进行学习,从而实现 language 指导 visual feature 的学习。首先构成一个联合的表达:![]() 其中的圈圈代表 Hadamard product。然后通过公式(4)将该结果转换为(0,1)之间的一个 value,这里得到的其实就是网络的输出了,即:
其中的圈圈代表 Hadamard product。然后通过公式(4)将该结果转换为(0,1)之间的一个 value,这里得到的其实就是网络的输出了,即:

这里就是简单的将 positive image-language pair 设置为 label =1,negative image-language pair 设置为 label=0,通过二元交叉熵来进行该关系的学习:
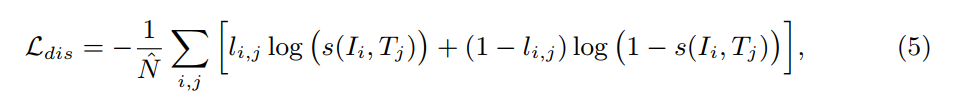
(3)Local Representation Image-language Association.
词汇信息仅仅描述了 person 的部分信息,所以,这两者之间不是对等的相关联的关系。但是,词汇仍然描述了 person image 的部分信息,所以,我们可以构建 词汇和图像特定区域的关联。
Image feature aggregation:
假设 P 是一个词汇,并且该词汇描述了图像 In 中特定的区域,我们想要预测一个向量![]() ,其反映了该区域的 feature。为了达到这个目标,我们通过加权聚合特征向量
,其反映了该区域的 feature。为了达到这个目标,我们通过加权聚合特征向量 ![]() ,来得到
,来得到 ![]() ,即:
,即:![]() 其中 rk 是 attention weight,翻译了词汇和特征向量之间的相关性,是通过一个 attention function 计算得到的。
其中 rk 是 attention weight,翻译了词汇和特征向量之间的相关性,是通过一个 attention function 计算得到的。
左侧的 ![]() ,是归一化
,是归一化![]() 之后得到的。这个过程可以表达为:
之后得到的。这个过程可以表达为:
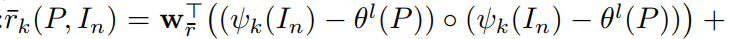
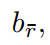
然后用 softmax 函数进行归一化,即:![]()
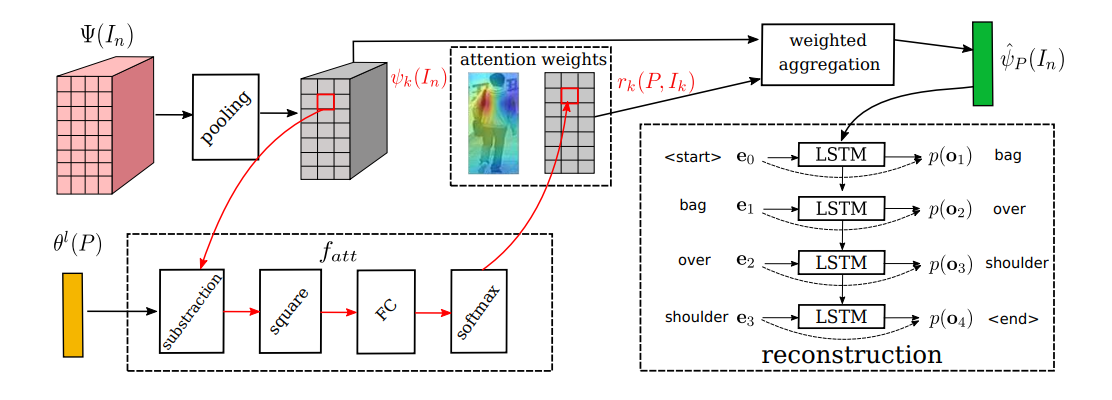
Phrase reconstruction:
为了强化 聚合后的特征图![]() 以及 输入词汇 P 之间的一致性,我们构建了一个条件概率
以及 输入词汇 P 之间的一致性,我们构建了一个条件概率 ![]() 来重构 P。由于词汇并没有固定的长度,所以通常利用 chain rule,即 链式法则,来进行建模:
来重构 P。由于词汇并没有固定的长度,所以通常利用 chain rule,即 链式法则,来进行建模:![]() 受到 Image Caption 任务的启发,我们采用 LSTM 模型来建模该概率模型。具体来说,我们首先将图像的 feature 输入到 LSTM,然后将当前单词的映射输入进去,得到下一个单词的 hidden state。下一个单词的概率是通过 hidden state $h_{m+1}$ 以及 Word embedding $e_m$。这样单词的概率分布可以表达为:
受到 Image Caption 任务的启发,我们采用 LSTM 模型来建模该概率模型。具体来说,我们首先将图像的 feature 输入到 LSTM,然后将当前单词的映射输入进去,得到下一个单词的 hidden state。下一个单词的概率是通过 hidden state $h_{m+1}$ 以及 Word embedding $e_m$。这样单词的概率分布可以表达为:
![]()
![]()
所以,重构 loss 可以表达为:
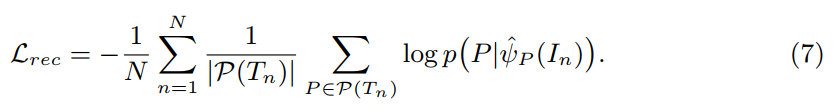
4. Training and Testing :

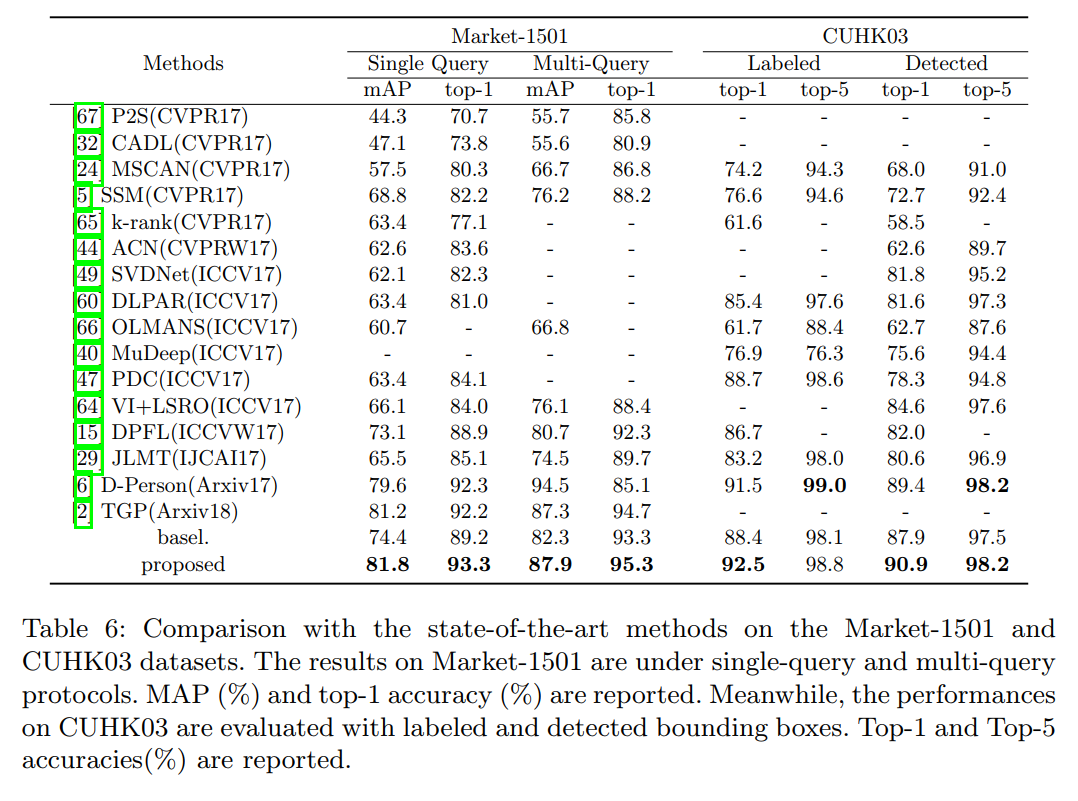
5. Experiments :