Learning to Learn
A key aspect of intelligence is versatility – the capability of doing many different things. Current AI systems excel at mastering a single skill, such as Go, Jeopardy, or even helicopter aerobatics. But, when you instead ask an AI system to do a variety of seemingly simple problems, it will struggle. A champion Jeopardy program cannot hold a conversation, and an expert helicopter controller for aerobatics cannot navigate in new, simple situations such as locating, navigating to, and hovering over a fire to put it out. In contrast, a human can act and adapt intelligently to a wide variety of new, unseen situations. How can we enable our artificial agents to acquire such versatility?
There are several techniques being developed to solve these sorts of problems and I’ll survey them in this post, as well as discuss a recent technique from our lab, called model-agnostic meta-learning. (You can check out the research paper here, and the code for the underlying technique here.)
Current AI systems can master a complex skill from scratch, using an understandably large amount of time and experience. But if we want our agents to be able to acquire many skills and adapt to many environments, we cannot afford to train each skill in each setting from scratch. Instead, we need our agents to learn how to learn new tasks faster by reusing previous experience, rather than considering each new task in isolation. This approach of learning to learn, or meta-learning, is a key stepping stone towards versatile agents that can continually learn a wide variety of tasks throughout their lifetimes.
So, what is learning to learn, and what has it been used for?
Early approaches to meta-learning date back to the late 1980s and early 1990s, including Jürgen Schmidhuber’s thesis and work by Yoshua and Samy Bengio. Recently meta-learning has become a hot topic, with a flurry of recent papers, most commonly using the technique for hyperparameter and neural network optimization, finding good network architectures, few-shot image recognition, and fast reinforcement learning.

Various recent meta-learning approaches.
Few-Shot Learning
In 2015, Brendan Lake et al. published a paper that challenged modern machine learning methods to be able to learn new concepts from one or a few instances of that concept. As an example, Lake suggested that humans can learn to identify “novel two-wheel vehicles” from a single picture (e.g. as shown on the right), whereas machines cannot generalize a concept from just a single image. (Humans can also draw a character in a new alphabet after seeing just one example). Along with the paper, Lake included a dataset of handwritten characters,Omniglot, the “transpose” of MNIST, with 1623 character classes, each with 20 examples. Two deep learning models quickly followed with papers at ICML 2016 that used memory-augmented neural networks and sequential generative models; showing it is possible for deep models to learn to learn from a few examples, though not yet at the level of humans.

How Recent Meta-learning Approaches Work
Meta-learning systems are trained by being exposed to a large number of tasks and are then tested in their ability to learn new tasks; an example of a task might be classifying a new image within 5 possible classes, given one example of each class, or learning to efficiently navigate a new maze with only one traversal through the maze. This differs from many standard machine learning techniques, which involve training on a single task and testing on held-out examples from that task.

Example meta-learning set-up for few-shot image classification, visual adapted from Ravi & Larochelle ‘17.
During meta-learning, the model is trained to learn tasks in the meta-training set. There are two optimizations at play – the learner, which learns new tasks, and the meta-learner, which trains the learner. Methods for meta-learning have typically fallen into one of three categories: recurrent models, metric learning, and learning optimizers.
Recurrent Models
These approaches train a recurrent model, e.g. an LSTM, to take in the dataset sequentially and then process new inputs from the task., In an image classification setting, this might involve passing in the set of (image, label) pairs of a dataset sequentially, followed by new examples which must be classified.
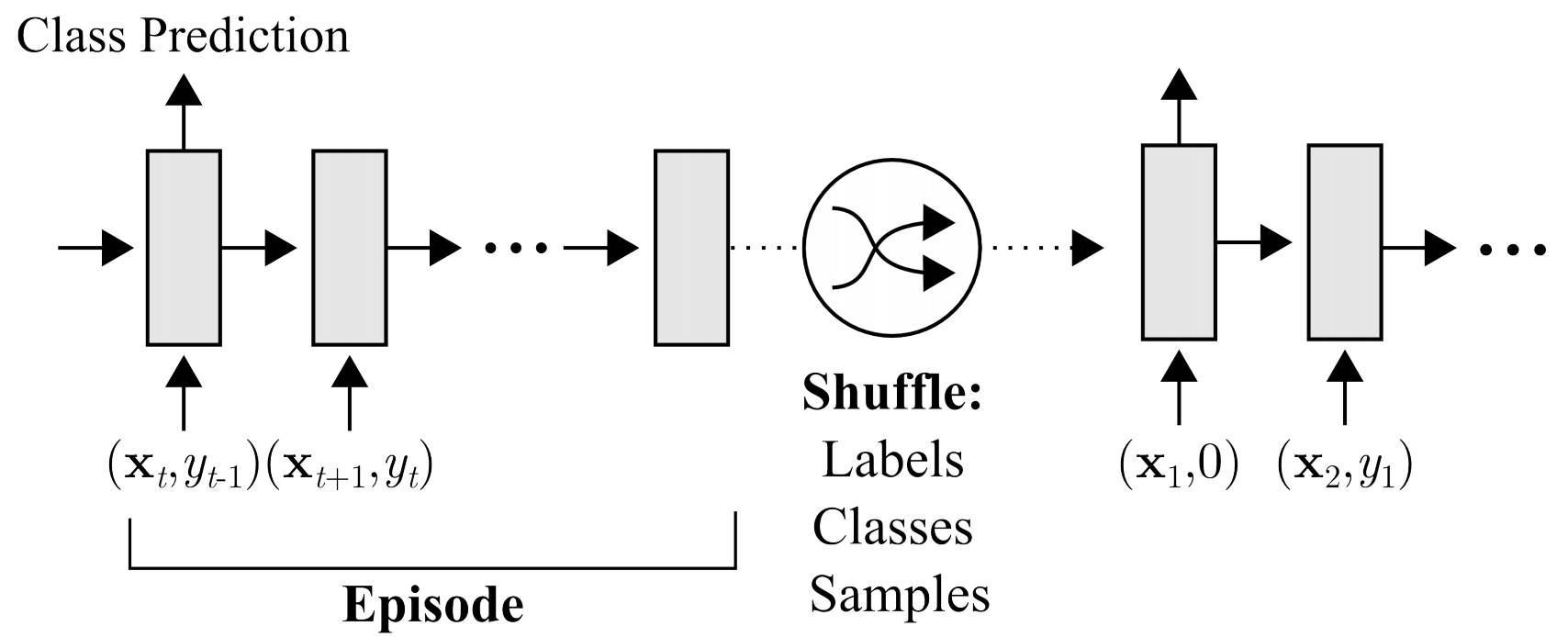
Recurrent model approach for inputs $mathbf{x}_t$ and corresponding labels $y_t$, figure from Santoro et al. '16.
The meta-learner uses gradient descent, whereas the learner simply rolls out the recurrent network. This approach is one of the most general approaches and has been used for few-shot classification and regression, and meta-reinforcement learning. Due to its flexibility, this approach also tends to be less (meta-)efficient than other methods because the learner network needs to come up with its learning strategy from scratch.
Metric Learning
This approach involves learning a metric space in which learning is particularly efficient. This approach has mostly been used for few-shot classification. Intuitively, if our goal is to learn from a small number of example images, than a simple approach is to compare the image that you are trying to classify with the example images that you have. But, as you might imagine, comparing images in pixel space won’t work well. Instead, you can train a Siamese network or perform comparisons in a learned metric space. Like the previous approach, meta-learning is performed using gradient descent (or your favorite neural network optimizer), whereas the learner corresponds to a comparison scheme, e.g. nearest neighbors, in the meta-learned metric space. These approaches work quite well for few-shot classification, though they have yet to be demonstrated in other meta-learning domains such as regression or reinforcement learning.
Learning Optimizers
The final approach is to learn an optimizer. In this method, there is one network (the meta-learner) which learns to update another network (the learner) so that the learner effectively learns the task. This approach has been extensively studied for better neural networkoptimization. The meta-learner is typically a recurrent network so that it can remember how it previously updated the learner model. The meta-learner can be trained with reinforcement learning or supervised learning. Ravi & Larochelle recently demonstrated this approach’s merit for few-shot image classification, presenting the view that the learner model is an optimization process that should be learned.
Learning Initializations as Meta-Learning
Arguably, the biggest success story of transfer learning has been initializing vision network weights using ImageNet pre-training. In particular, when approaching any new vision task, the well-known paradigm is to first collect labeled data for the task, acquire a network pre-trained on ImageNet classification, and then fine-tune the network on the collected data using gradient descent. Using this approach, neural networks can more effectively learn new image-based tasks from modestly-sized datasets. However, pre-training only goes so far. Because the last layers of the network still need to be heavily adapted to the new task, datasets that are too small, as in the few-shot setting, will still cause severe overfitting. Furthermore, we unfortunately don’t have an analogous pre-training scheme for non-vision domains such as speech, language, and control.1 Is there something to learn from the remarkable success of ImageNet fine-tuning?
Model-Agnostic Meta-Learning (MAML)
What if we directly optimized for an initial representation that can be effectively fine-tuned from a small number of examples? This is exactly the idea behind our recently-proposed algorithm, model-agnostic meta-learning (MAML). Like other meta-learning methods, MAML trains over a wide range of tasks. It trains for a representation that can be quickly adapted to a new task, via a few gradient steps. The meta-learner seeks to find an initialization that is not only useful for adapting to various problems, but also can be adapted quickly (in a small number of steps) and efficiently (using only a few examples). Below is a visualization – suppose we are seeking to find a set of parameters $ heta$ that are highly adaptable. During the course of meta-learning (the bold line), MAML optimizes for a set of parameters such that when a gradient step is taken with respect to a particular task $i$ (the gray lines), the parameters are close to the optimal parameters $ heta_i^*$ for task $i$.
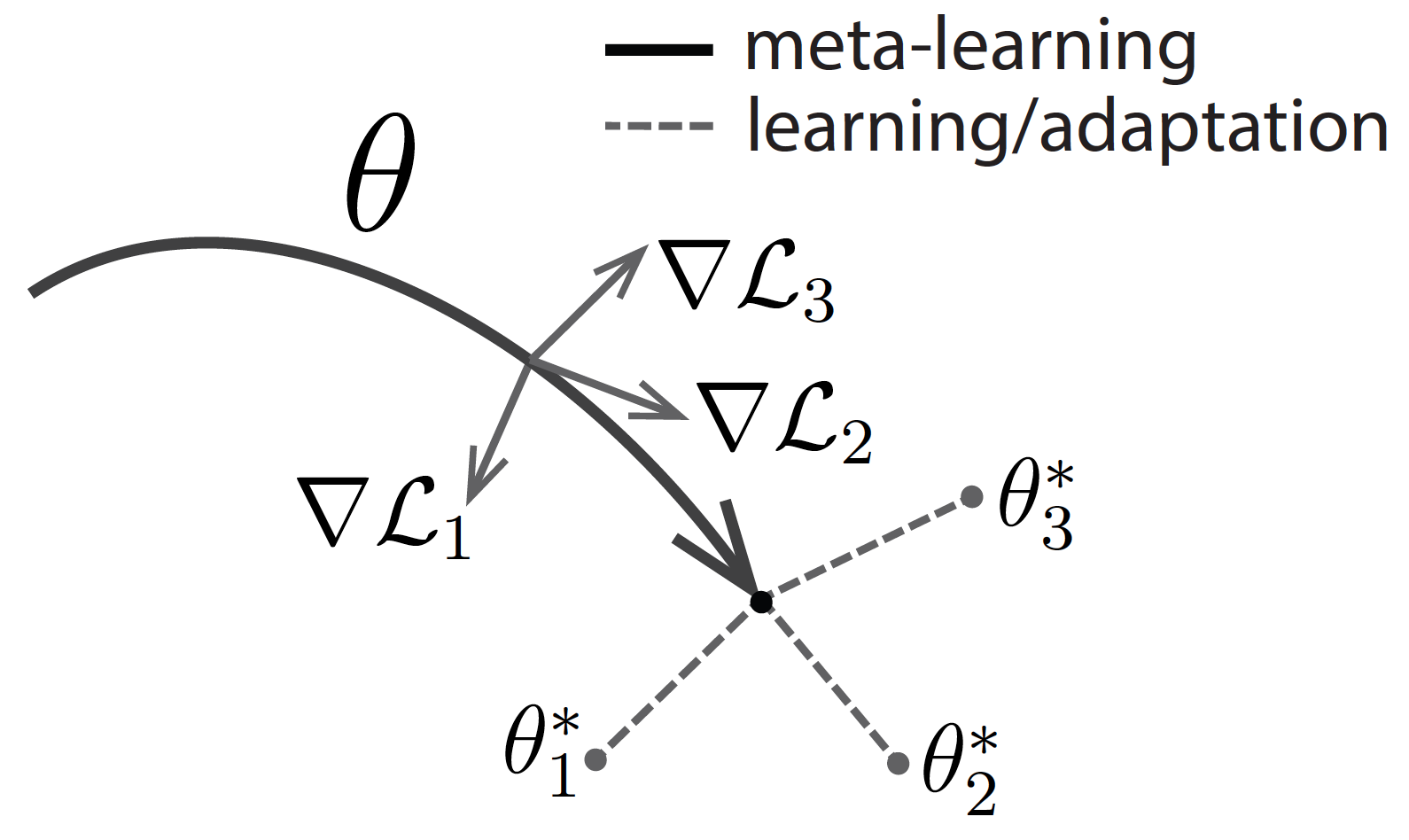
Diagram of the MAML approach.
This approach is quite simple, and has a number of advantages. It doesn’t make any assumptions on the form of the model. It is quite efficient – there are no additional parameters introduced for meta-learning and the learner’s strategy uses a known optimization process (gradient descent), rather than having to come up with one from scratch. Lastly, it can be easily applied to a number of domains, including classification, regression, and reinforcement learning.
Despite the simplicity of the approach, we were surprised to find that the method was able to substantially outperform a number of existing approaches on popular few-shot image classification benchmarks, Omniglot and MiniImageNet2, including existing approaches that were much more complex or domain specific. Beyond classification, we also tried to learn how to adapt a simulated robot’s behavior to different goals, akin to the motivation at the top of this blog post – versatility. To do so, we combined MAML with policy gradient methods for reinforcement learning. MAML discovered a policy which let a simulated robot adapt its locomotion direction and speed in a single gradient update. See videos below:

MAML on HalfCheetah.

MAML on Ant.
The generality of the method — it can be combined with any model smooth enough for gradient-based optimization — makes MAML applicable to a wide range of domains and learning objectives beyond those explored in the paper.
We hope that MAML’s simple approach for effectively teaching agents to adapt to variety of scenarios will bring us one step closer towards developing versatile agents that can learn a variety of skills in real world settings.
I would like to thank Sergey Levine and Pieter Abbeel for their valuable feedback.
This last part of this post was based on the following research paper:
- Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks.
C. Finn, P. Abbeel, S. Levine. In ICML, 2017. (pdf, code)
-
Though, researchers have developed domain-agnostic initialization schemes to encourage well-conditioned gradients and using data-dependent normalization. ↩
-
Introduced by Vinyals et al. ‘16 and Ravi & Larochelle ‘17, the MiniImageNet benchmark is the same as Omniglot but uses real RGB images from a subset of the ImageNet dataset. ↩
Reference:
1. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. C. Finn, P. Abbeel, S. Levine. In ICML, 2017. (pdf, code)
2. http://bair.berkeley.edu/blog/2017/07/18/learning-to-learn/
3. https://zhuanlan.zhihu.com/p/28639662
4. https://github.com/songrotek/Meta-Learning-Papers
5. https://zhuanlan.zhihu.com/p/32270990
6. https://zhuanlan.zhihu.com/p/27629294