MatchNet: Unifying Feature and Metric Learning for Patch-Based Matching
CVPR 2015
本来都写到一半了,突然笔记本死机了,泪崩!好吧,重新写!本文提出了一种联合的学习patch表示的一个深度网络 和 鲁棒的特征比较的网络结构。与传统的像SIFT特征点利用欧氏距离进行距离计算的方式不同,本文是利用全连接层,通过学习到的距离度量来表示两个描述符的相似性。
本文的贡献点如下:
1. 提出了一个新的利用深度网络架构基于patch的匹配来明显的改善了效果;
2. 利用更少的描述符,得到了比state-of-the-art更好的结果;
3. 实验研究了该系统的各个成分的有效作用,表明,MatchNet改善了手工设计 和 学习到的描述符加上对比函数;
4. 最后,作者 release 了训练的 MatchNet模型。
首先来看本文的网络架构:

主要有如下几个成分:
A. Feature Network.
主要用于提取输入patch的特征,主要根据AlexNet改变而来,有些许变化。主要的卷积和pool层的两段分别有 preprocess layer 和 bottlebeck layer,各自起到归一化数据和降维,防止过拟合的作用。
B: Metric Network.
主要用于feature Comparison,3层fc 加上 softmax。
C: 在训练阶段,特征网络用作“双塔”,共享参数。双塔的输出串联在一起作为度量网络的输入。The entire network is trained on labeled patch-pairs generated from the sampler to minimize the cross-entropy loss. 在预测的时候,这两个子网络A 和 B 方便的用在 two-stage pipeline. 如下图所示:
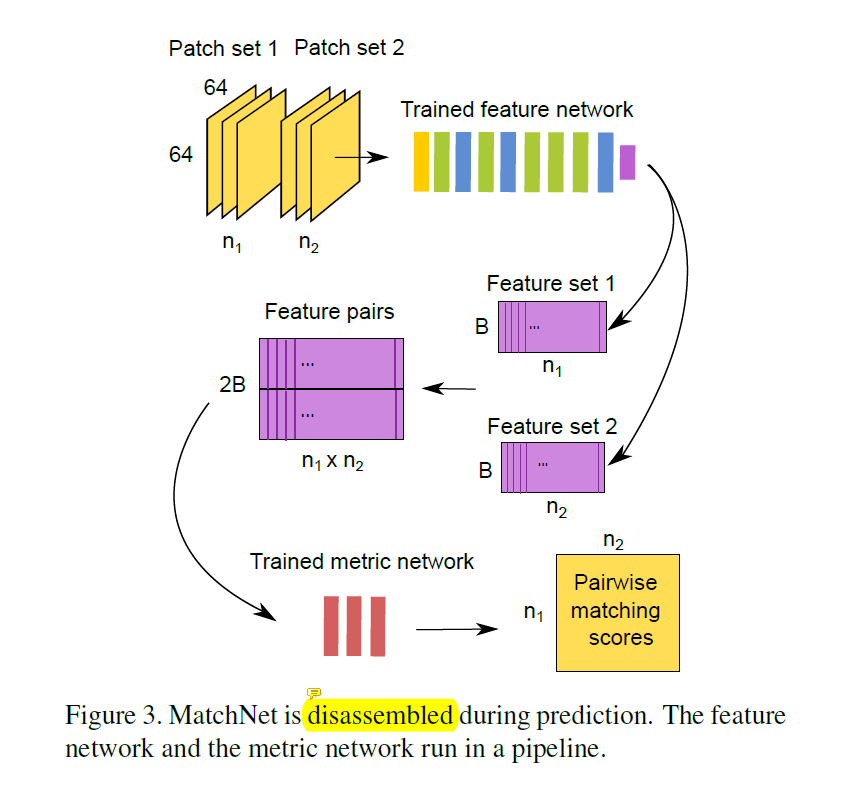
MatchNet 的具体参数如下表所示,注意Bottleneck 和 FC 中参数的选择。

接下来看看“网络的训练和测试”,即:
特征和度量网络联合的训练,利用随机梯度下降的方法,可以最小化下面的交叉熵损失函数:
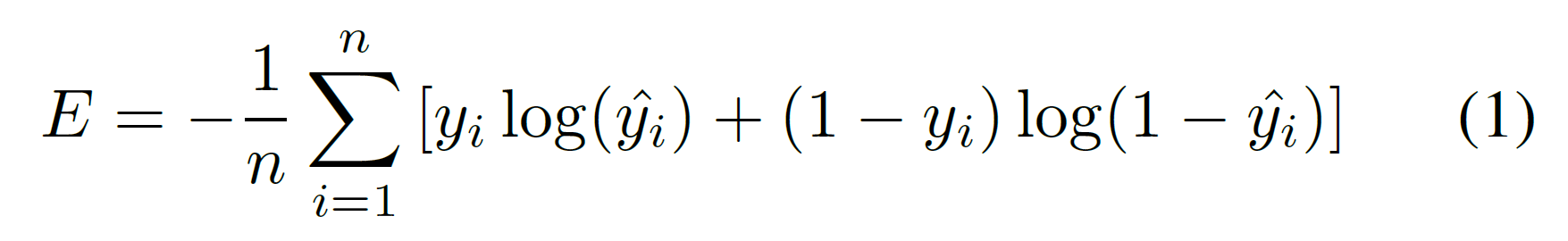
其中,yi 是输入pair xi 的0/1标签。1代表匹配。带箭头的 yi 和 1-yi 分别表示 softmax activations,是在FC3 上的两个点v0(xi) 和 v1(xi)计算得来的。计算公式如下:

上面公式中,带箭头的 yi 用来表示公式1中预测标签为1的概率。
由于数据正负样本的不平衡性,会导致实验精度的降低,本文采用采样的训练方法,在一个batchsize中,选择一半正样本,一半负样本进行训练。分别将patch输入给特征塔 和 度量网络,单独的进行训练,分为两个阶段进行。首先,对所有的patch进行特征编码,然后,我们将feature进行成对处理,输入给度量矩阵然后得到其scores。
算法总结:

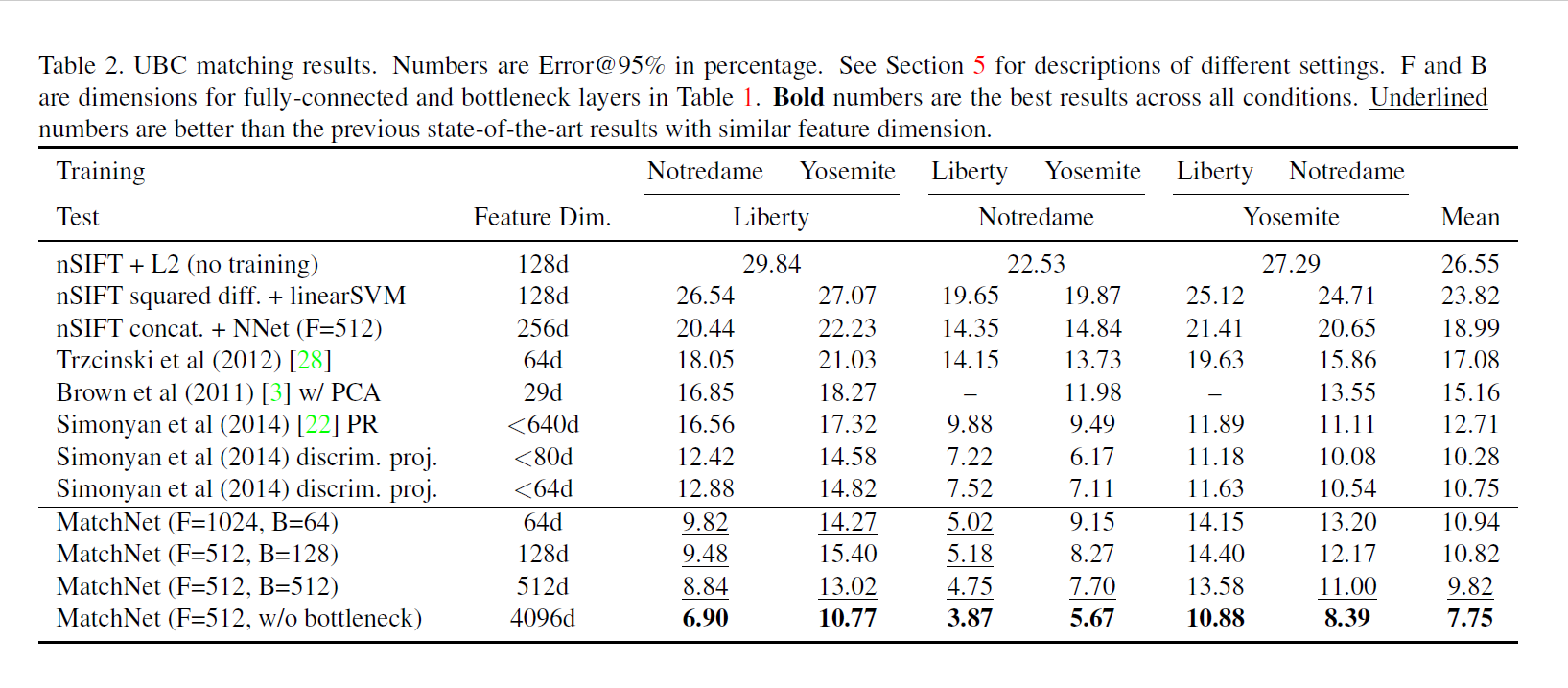
实验结果贴图:
我的感受:
看完这篇文章,总体来说,有点懵逼!奇怪的是,作者竟然讲的津津有味!还记得开篇,作者说这文章的主要贡献点是提出了一种训练网络提取feature 和 度量feature之间的相似性。Well,提取feature主要体现在“双峰”上,哦,我错了,是“双塔”。这个无可厚非,到了全连接层,就是要得到的feature了。那么,度量feature之间的相似性,体现在哪里呢?哦,对,体现在最后最后的 全连接层上。那么,与传统方法的不同在于,本文的度量方式,并非简单的欧氏距离,而是学出来的。
怎么体现学出来的呢???
先从两张图像中提patch,将两种patch分别采样,输给两个提取特征的网络,然后将pool4 的输出降维(通过Bottleneck layer),将“双塔”的输出串联起来,输入到 fc 层,两层fc之后,输入给softmax,此时输出 0 或者 1,分别代表匹配或者不匹配,然后将此结果输出到 交叉熵计算loss,通过这样的方式,完成整个网络的训练,只是此处,提取特征的网络层 和 度量网络 是单独训练的,“双塔”的参数也是共享的。
讲到这里,也许就是这个文章的主要内容了。Ok,该怎么借鉴,就看自己的了。
附一张美照,哈哈,明天实验室整体出动去happy,玩真人 CS 和 烧烤,突然感觉好开心啊。。哈哈。。。
