Visual Prompt Tuning
2022-07-16 19:13:50
1. Background and Motivation:
现有深度学习方法的模型参数越来越大,且一般采用的是 pre-training 和 fune-tuning 的套路。在下游任务上进行微调时,模型的参数一般是 fully-tuned 这种套路,因此模型的参数很大,例如作者提到 resnet-50 模型参数量为 25M,而 ViT-Huge 的参数量为 632M。因此,如何有效且高效的进行下游任务微调就成了本文的研究目的。
为了降低需要微调的模型参数量,研究者一般采用 部分参数微调的方法,如仅仅微调 classifier head, bias term 等。但是这种微调策略的不足是:一般最终精度低于 fully-tuned 版本。作者受到 NLP 中 prompt learning 的启发,尝试提出新的方法进行微调。作者不对 backbone 的参数进行调整,而是直接修改 Transformer 的输入,这种方式仅仅引入了小规模的 task-specific learnable parameters 到 input space。这些额外的参数被简单地追加在每一个 transformer layer 的输入序列中,在微调的过程中,直接与 linear head 一起学习。
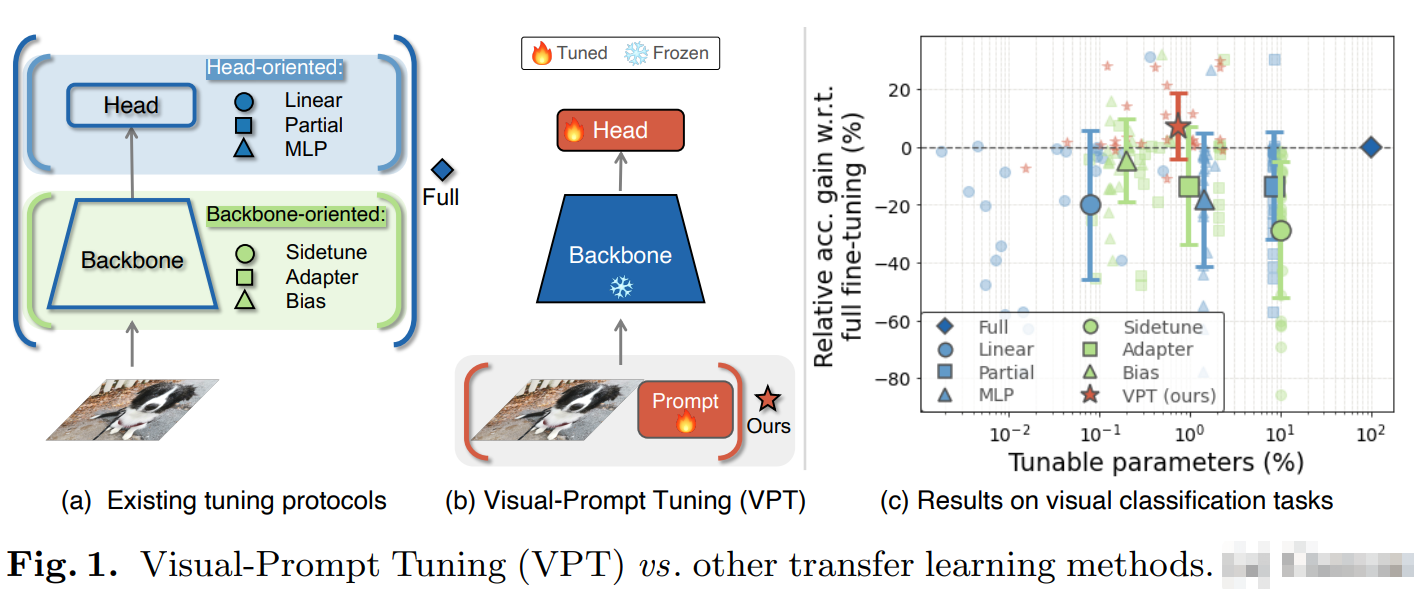
2. Approach:
如下图 2 所示,作者在原始 Transformer 结构的基础上,仅对输入的层次上进行改动。提出了两个版本:
1). Visual-prompt tuning: Deep;
2). Visual-prompt tuning: Shallow.
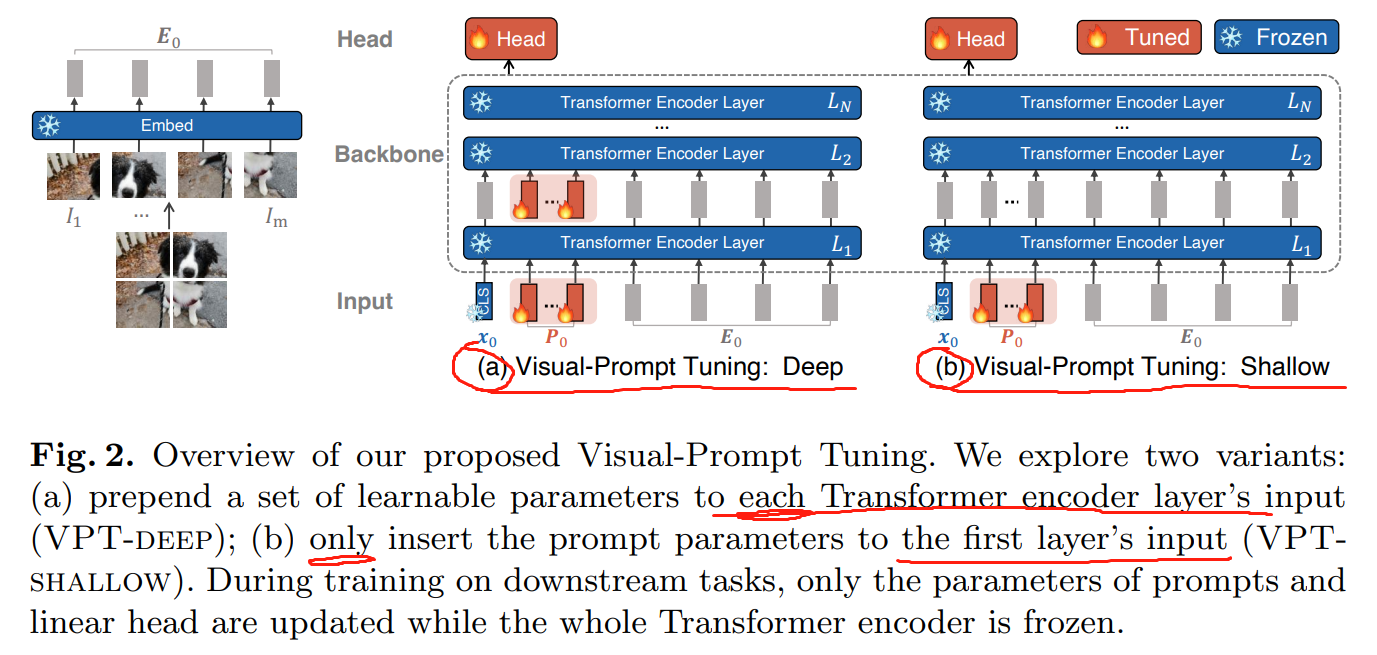
给定一个预训练的 Transformer 模型,作者引入了一组 p 连续的 embeddings,其维度为 d, 即 prompts。在微调的过程中,仅仅与任务相关的 prompts 是需要进行调整的,而加载的 Transformer network 是固定不变的。根据所涉及到的 Transformer layers 层数的不同,作者将其方法分类为 deep 和 shallow 两种。
- VPT-Shallow: Prompts 仅仅被加入到第一层 L1。每一个 prompt 符号是一个可学习的 d-维向量。p 个 prompts 的组合,记为 P,因此,shallow-prompted ViT 被记为

其中, P 是可学习的,x0 是固定的,L1, Li 等网络层参数也是固定的,Head 是动态调整的。值得注意的是,XN 是与 prompts 的位置无关的,因为这些 prompts 是在位置编码之后被插入的,即: [x0, P, E0] 与 [x0, E0, P] 是等价的。
- VPT-Deep:该版本就是在每一层的 Transformer 输入时,都加入 prompts。对于第 i+1 层来说,可以表达为:
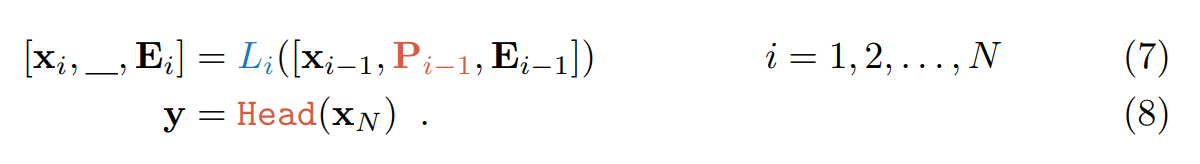
问题来了,这里 Li 层的输出中的 _ 表示什么呢?
Storing Visual Prompts:

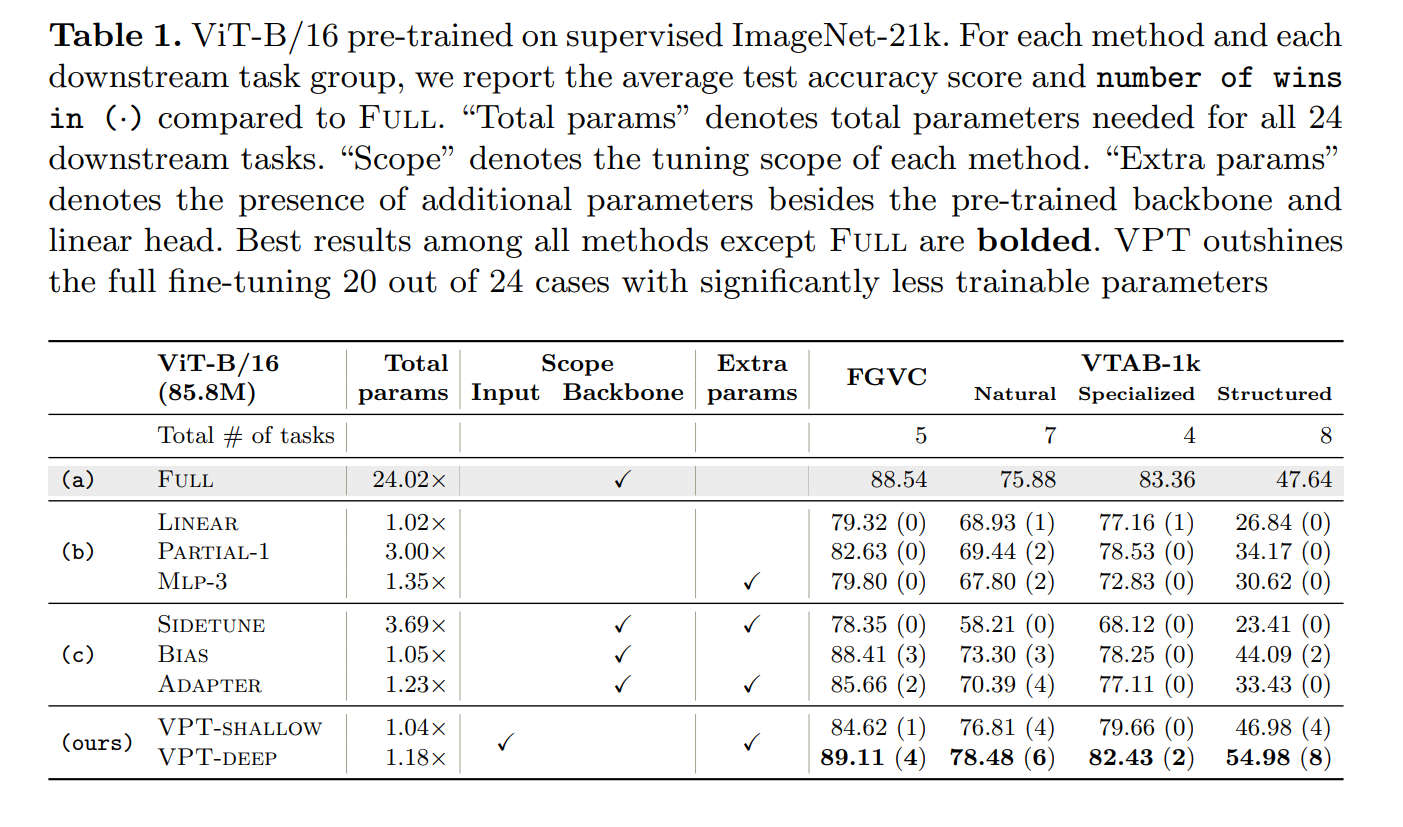
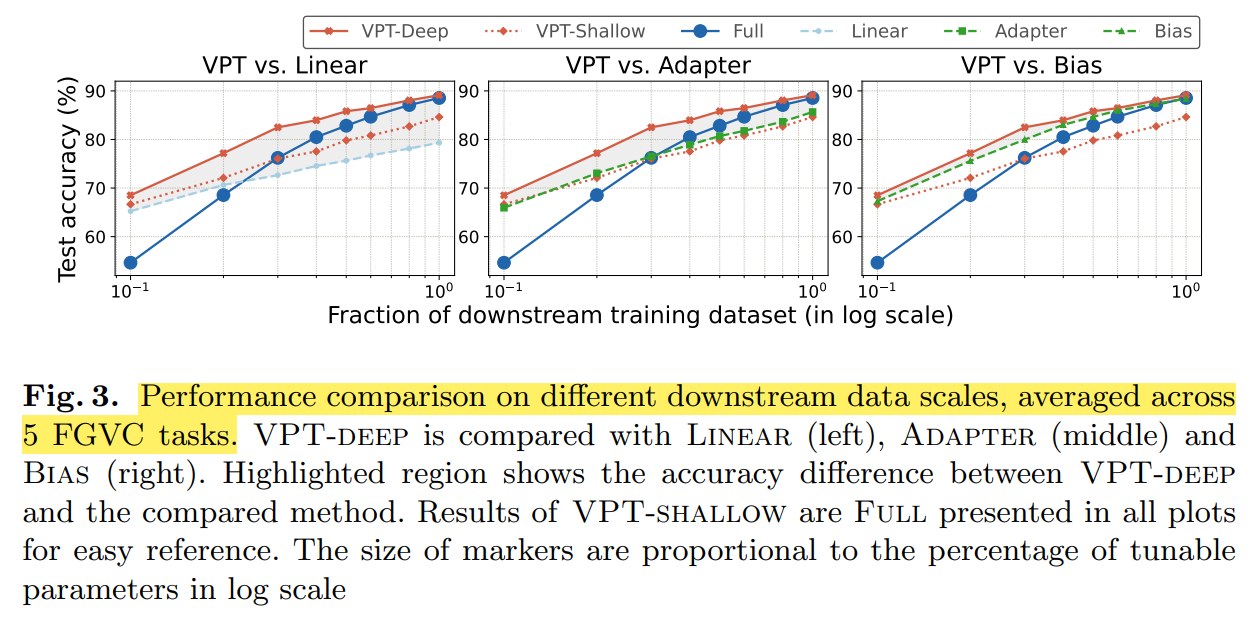
3. Experiments:
==