VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text
2021-07-22 08:54:20
Paper: https://arxiv.org/pdf/2104.11178.pdf
1. Background and Motivation:
本文尝试用一个共享的 backbone 来学习三个模态的特征表达,并且是用 transformer 的框架,自监督的方式去学习。作者认为监督学习的自监督有如下两个问题:
1). 无法充分利用海量无标签数据;
2). CV 的众多任务中,获得有标签数据,是非常困难的。
因此,本文尝试从无监督学习的角度,提出了 VATT 模型。
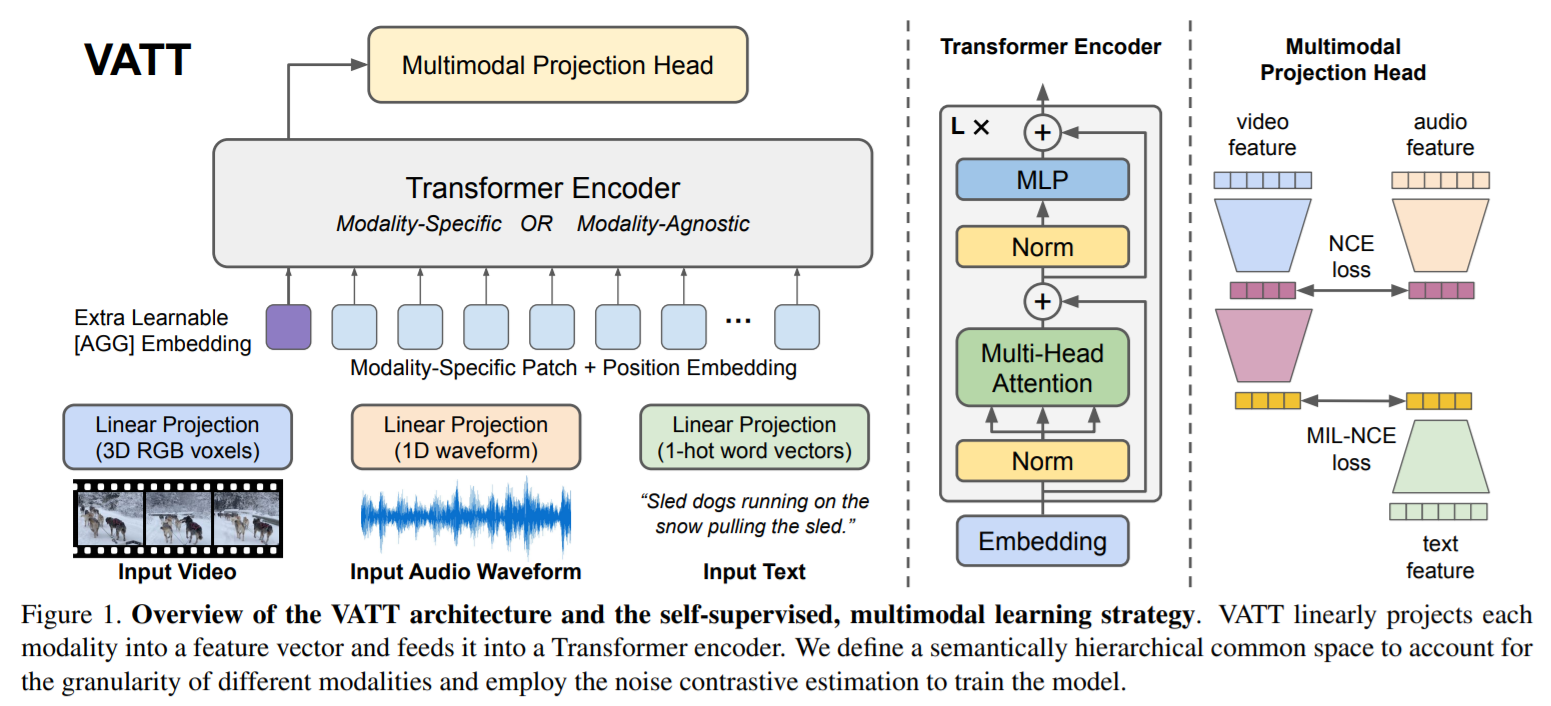
如上图所示,更残暴的是,作者直接让三个模态共享同一个骨干网络。实验证明,与模态无关的骨干网络可以取得与不同模态的骨干网络,相似的结果。另外,本文提到的另外一个创新之处在于,DeepToken,随机的将输入的 tokens 进行丢弃,降低了Transformer 的训练复杂度。但是有些许的精度损失,这个类似常见的对抗学习机制。
2. Model:
Video:本文的输入是 video,因此,作者划分一个视频为 T*H*W 个 patch,每一个 patch 包含多个立方体。然后用 FC 对这些 立方体进行映射,得到 d-D 的像素表示。此外,作者设计了一组可学习的位置编码:

Audio:原始的音频是 1D 的输入,作者将其划分为多个部分。类似的,作者也对这些划分的独立的输入,进行特征和位置映射。
Text:对文本中的单词进行映射,得到 word embedding。
3. Multi-modal Contrastive Learning:
- Noise-ContrastiveEstimation (NCE):
对于 video-audio pairs,构建 pos 和 neg 的样本对,通过最小化负样本之间的相似性和最大化正样本对之间的相似度进行特征对齐;
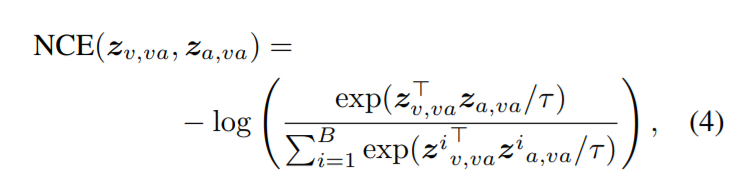
- Multiple-Instance-Learning-NCE (MIL-NCE):
对于 video-text pairs,利用 MIL-NCE 进行学习,即:比对一个视频的输入和多个时序上与视频输入邻近的文本输入;

因此,总体的对比学习损失函数为两个损失函数的平衡:

4. Pre-train dataset:
internet videos: 1.2M unique videos, each providing multiple clips with audio and narration scripts resulting in 136M video-audio-text triplets in total.
AudioSet:consists of 10-second clips sampled from two million videos from YouTube.
Download Page:https://research.google.com/audioset/download.html
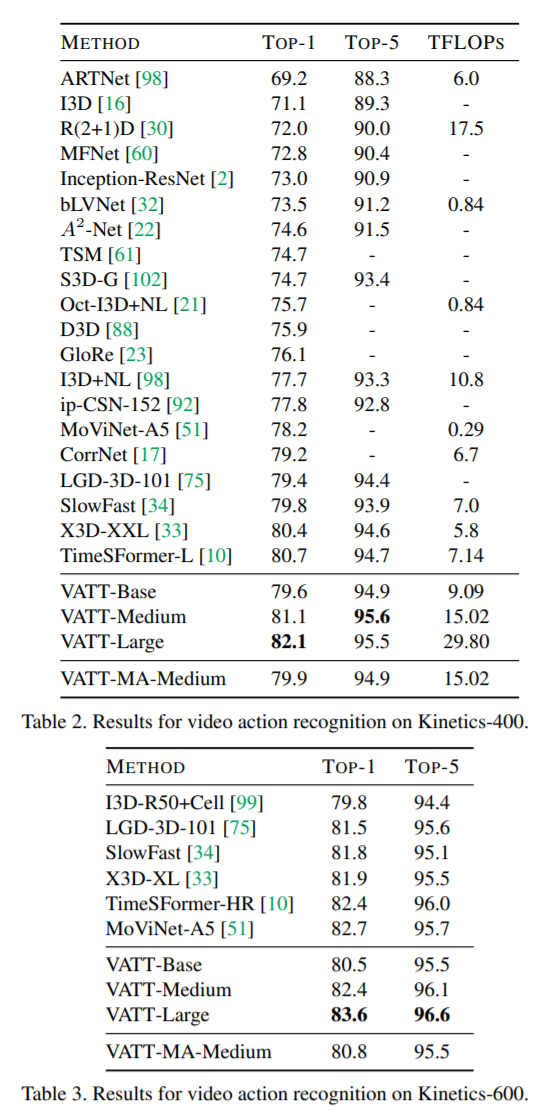
下游任务:Video action recognition,Audio event classification,Zero-shot video retrieval,Image classification。
5. Experiments: