LXMERT: Learning Cross-Modality Encoder Representations from Transformers
2020-12-24 14:24:05
Paper: EMNLP 2019
Code: github
1. Background and Motivation:
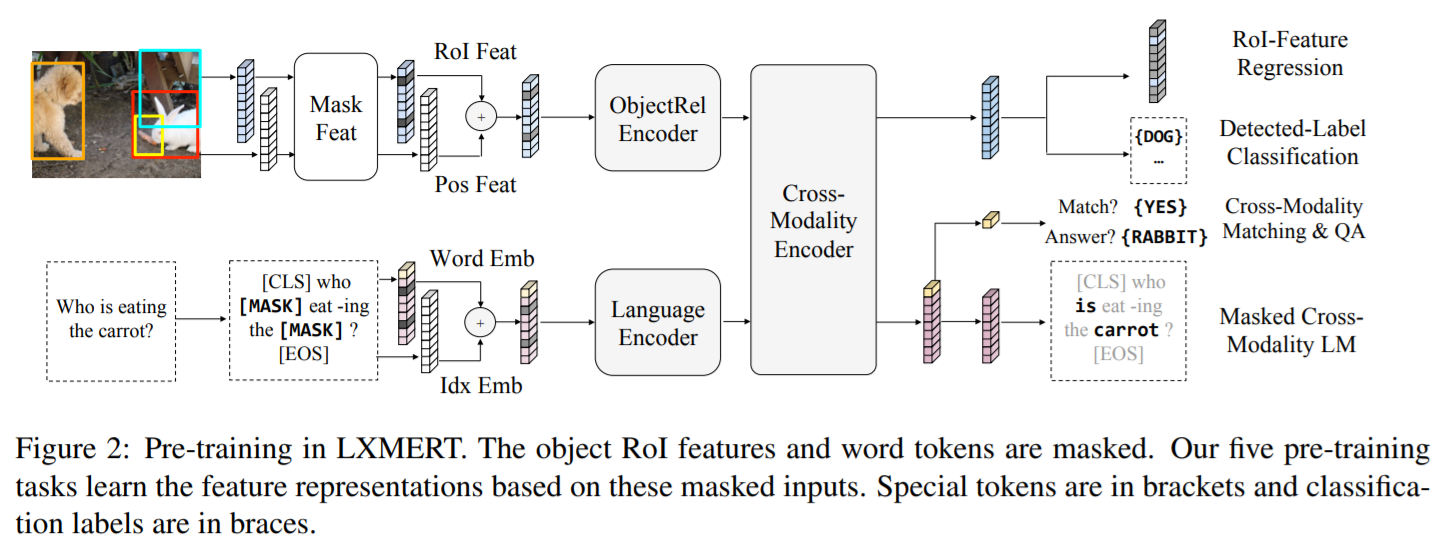
本文提出一种 image-language pre-trained model,特征编码层面有三个 encoder,即:
- an object relationship encoder,
- a language encoder,
- a cross-modality encoder.
在5个任务上进行了预训练:
- masked cross-modality language modeling,
- masked object prediction via RoI feature regression,
- masked object prediction via detected-label classification,
- cross-modality matching,
- image question answering.
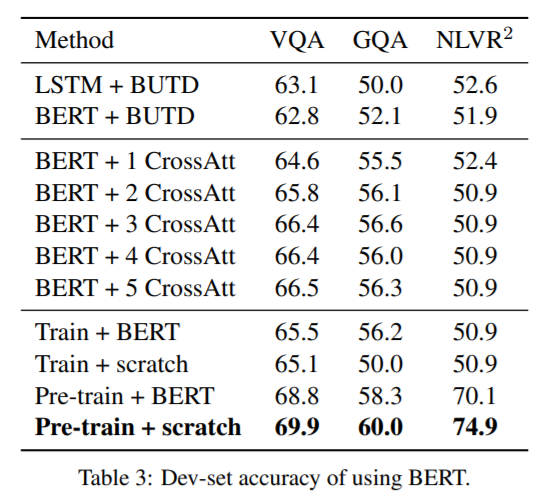
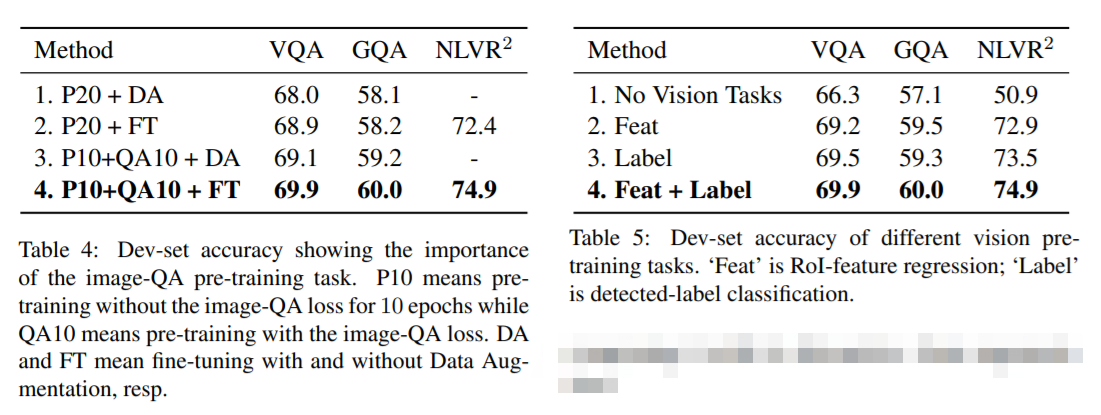
实验结果提升巨大。有多巨大?先来看模型架构吧。
2. Approach:
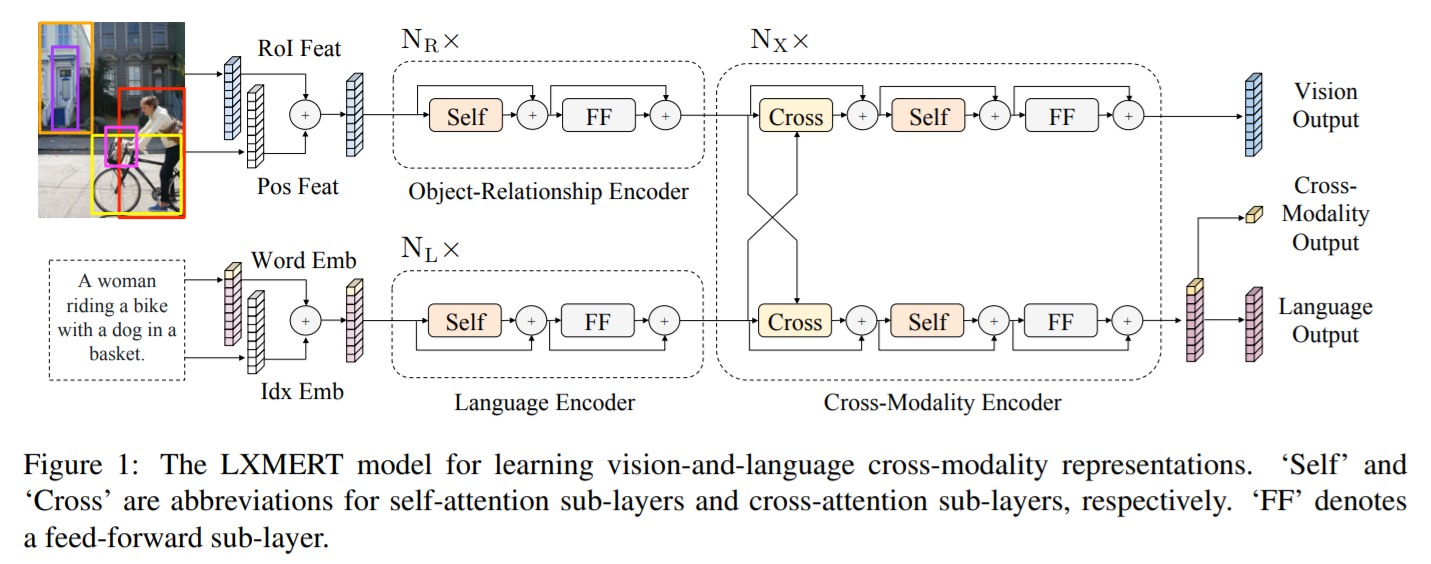
2.1. Input Embeddings:
模型的输入是 image 和 sentence,然后经过 input embedding layer 转换为 两组特征:word-level sentence embeddings, and object-level image embeddings.
Word-Level Sentence Embeddings:
对输入的 language,将其进行单词划分,转为固定长度的单词列表。然后对其中的 word 及其 index 进行映射,然后这两个映射向量相加,得到 index-aware word embeddings:

Object-Level Image Embeddings:
本文不直接利用 CNN 的输出特征,而是将检测出来的物体作为图像的映射。如图 1 所示,本文将 RoI regions 抠出来,和其索引一起进行映射,然后相加:
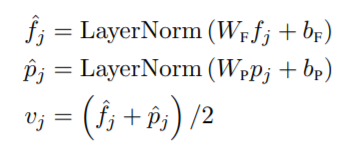
有了上述 image feature 和 language feature,接下来就是对其进行联合特征学习。
2.2. Encoders:
如前文所述,本文设计了三种 encoder 模块,都是基于两种 attention layer:self-attention layer 和 cross-attention layer。作者这里回顾了一下 attention layer 和 self-attention layer,引出 transformer 模型。然后介绍了single-Modality encoders 以及 Cross-Modality Encoder。
Attention Layers:假设给定两个向量,一个是 query vector x,另外一个是 context vector {yj},那么常规的 attention 层,就是计算这两者之间的相似度:
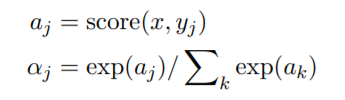
输出就是加权之后的特征。
Self-Attention Layers:当 x 是来自 y 本身的时候,就称之为 self-attention layer。
Multi-head Attention:self-attention layer 堆叠多个,就是多头注意力机制了。
Transformer:多头注意力机制 加上 位置编码,就是 transformer 模型的核心。
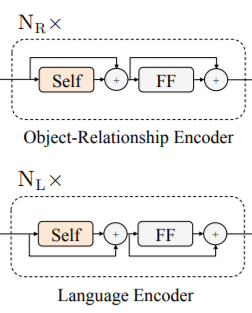
Single-Modality Encoder:
在进行模态交互之前,作者首先对单个模态进行 self-attention 处理。也就是图 1 中的如下这个模块:
Cross-Modality Encoder:
每一个 cross-modality layer 都包含
- 两个 self-attention sub-layers,
- 一个 bi-directional cross-attention sub-layers,
- 两个 feed-forword sub-layers。
作者对这种 cross-modality layers 进行了堆叠。在第 k 层,首先用一个 bi-directional cross-attention sub-layer,其中包含两个单向的 cross-attention sub-layers:
- one from language to vision ;
- one from vision to language.
其 query 和 context vectors 都是来自上一层,即 k-1 层:
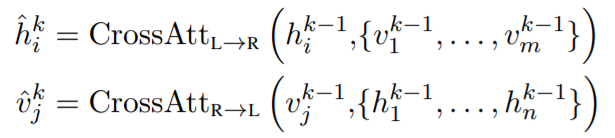
为了构建中间的连接,作者用一个 self-attention sub-layers 来继续处理该输出:

最后,经过 feed-forward layer 就可以得到第 k 层的输出。
2.3 Output Representations:
本文模型的输出是三个部分:vision output,language output,以及 cross-modality output。
3. Pre-Training Strategies:
3.1. Pre-training Tasks:
- Language Task: Masked Cross-Modality LM
- Vision Task: Masked Object Prediction
- RoI-Feature Regression
- Detected-Label Classification
- Cross-Modality Tasks
- Cross-Modality Matching
- Image Question Answering (QA)
对于 pre-trained,作者用 4 张 Titan XP 训练了 10天。然后对不同的任务,再进行微调。下面的表格是关于训练数据的相关信息。
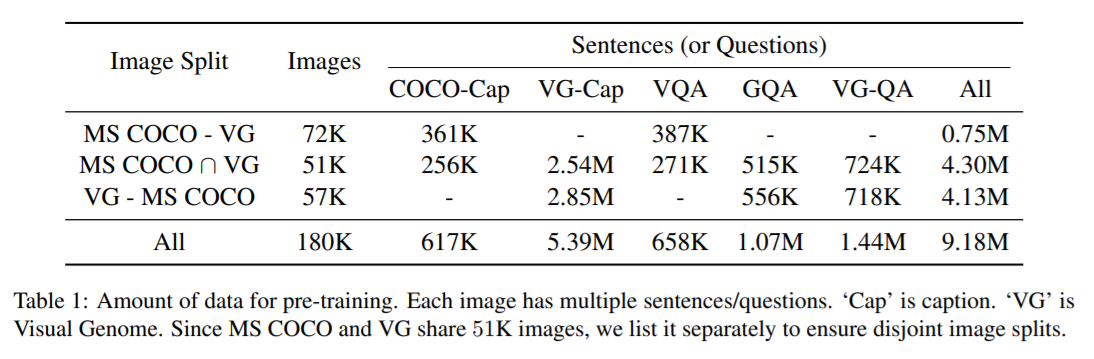
4. 实验效果: