Attention is All you need
2020-03-22 00:29:11
Paper: https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
Doc: https://huggingface.co/transformers/
TensorFlow Code:https://github.com/tensorflow/tensor2tensor
PyTorch Code: https://github.com/jadore801120/attention-is-all-you-need-pytorch
TensorFlow 2.0 and PyTorch: https://github.com/huggingface/transformers
Harvard’s NLP group PyTorch Code: http://nlp.seas.harvard.edu/2018/04/03/attention.html
推荐博文:
1). 详解Transformer (Attention Is All You Need)
2). BERT大火却不懂Transformer?读这一篇就够了
3). 10分钟带你深入理解Transformer原理及实现
4). 原来Transformer就是一种图神经网络,这个概念你清楚吗?
5). The Illustrated Transformer
1. Background and Motivation:
最近 RNN 模型,特别是 LSTM 和 GRU 已经在序列建模上取得了顶尖的效果。RNN 模型通常在位置 t 的时候,吃掉当前时刻的输入和之前隐层状态。这就导致在训练样本中很难进行并行化处理,但是这种问题在更长的视频长度上变的非常关键,因为有内存,显存等的限制。最近的工作表明可以通过 factorization tricks 和 conditional computation 大幅度的改善计算效率,也改善了模型的性能。但是,RNN 模型的根本的约束仍然存在。
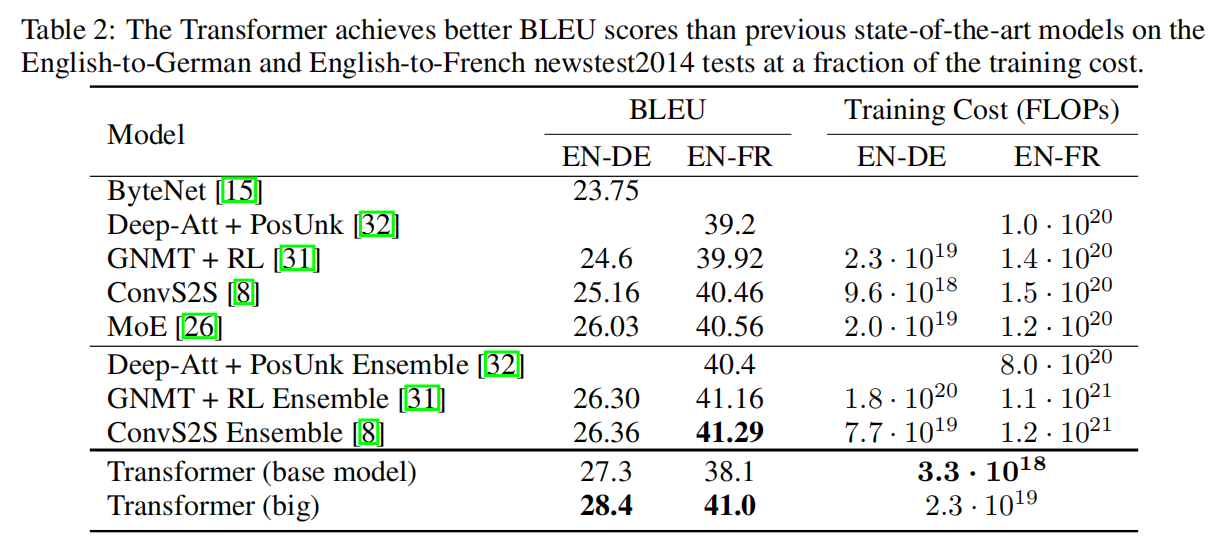
本文提出一种 Transformer 的模型,该模型可以避开 recurrence,仅仅依靠 attention model 来获得输入和输出之间的全局依赖。Transformer 可以允许更加明显的并行化处理,在相关翻译任务上也取得了 SOTA 的效果。
2. Model Architecture:
大部分有竞争力的神经序列翻译模型都包含 encoder-decoder 框架。此处,encoder 将输入的句子 (x1, ... , xn) 转换为连续的表达 z = (z1, ... , zn)。给定 z,decoder 然后产生了一个输出序列 (y1, ... , ym)。在每一个时刻,该模型都是 auto-regressive,在产生下一个时候,都会用到之前的符号。
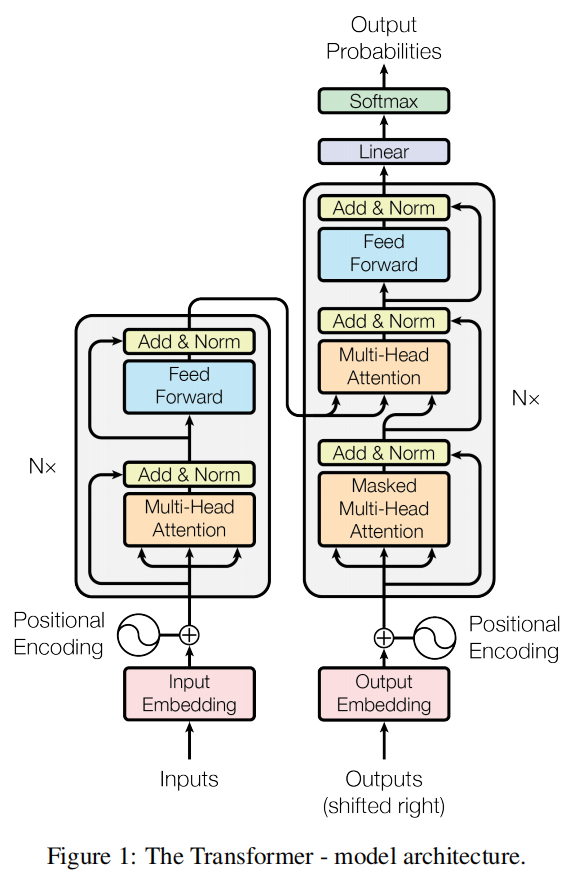
Transformer 模型服从这个总的框架,利用了 Stacked self-attention 和 point-wise,fc layer 来分别当做 encoder 和 decoder,如图 1 所示。
2.1. Encoder and Decoder Stacks:
Encoder: encoder 部分包含 6 个相同的层。每一层有 2 个子层。第一层是 multi-head self-attention mechanism, 第二个是 simple,position-wise fc 前向网络。在每两个子层之间,作者采用了残差链接,和 layer normalization。为了使用残差链接,所有的 sub-layers,以及 embedding layers,所产生的维度都是 512维。
Decoder:本文所用的 decoder 部分也是由 6 个相同的 layers 构成的。除了每一个 encoder layer 的两个 sub-layer 之外,decoder 添加了第三个 sub-layer,可以在 encoder 的输出上进行多头注意 (multi-head attention) 。和 encoder 类似,也采用了残差链接。作者还改动了 self-attention sub-layer to prevent positions from attending to subsequent positions(什么意思??)。This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
====>> 中间有个 “Masked Multi-Head Attention” 是什么意思???
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 k 个特征向量时,我们只能看到第 k-1 及其之前的解码结果,论文中把这种情况下的 multi-head attention 叫做 masked multi-head attention。
2.2. Attention:
一个 attention 函数可以描述为:mapping a query and a set of key-value pairs to an output, where the query, keys, values, and the output are all vectors.
输出被计算为:values 的加权求和,其中,赋予每一个值的权重是通过 query 和 对应 key 的相容函数 (compatibility function) 。
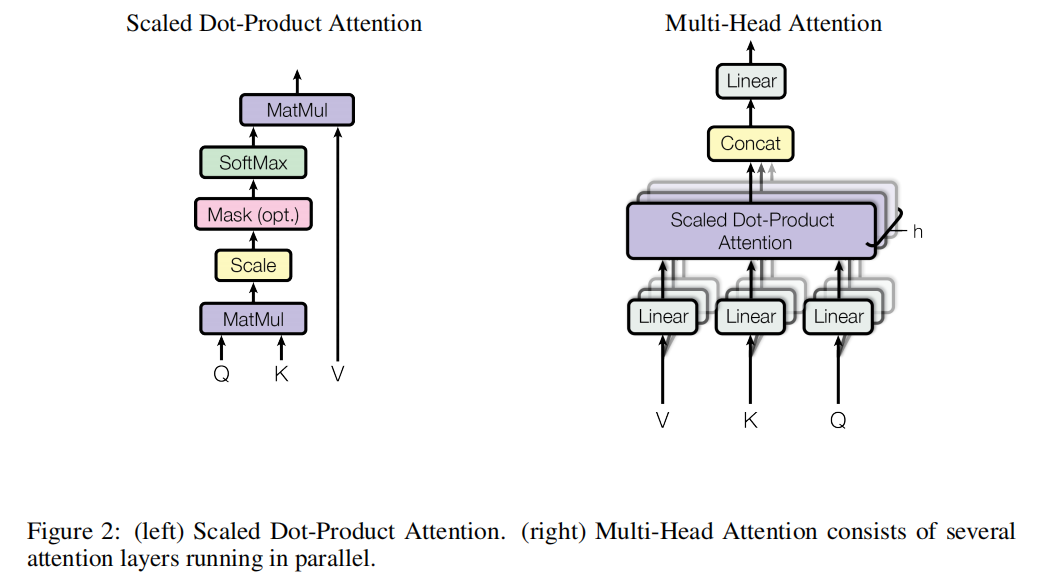
2.2.1. Scaled Dot-Product Attention:
作者称本文的 attention 为:“Scaled Dot-Product Attention”。输入包含:queries, keys, and values,维度分别是 dk, dv。 先将 query 和 all keys 进行点乘,然后除以 根号下 dk,再用一个 softmax 函数,来得到基于 values 的 weights。实际上,本文是直接在一组 queries 上同时进行计算 attention 函数,然后组成一个矩阵 Q。keys 和 values 都被打包为矩阵 K 和 V。输出的矩阵就可以用如下的方式得到:
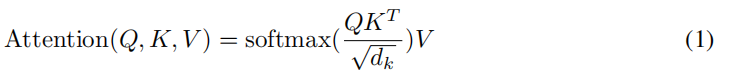
最常用的两种 attention function 是:additive attention 和 dot-product (multiplicative) attention。Dot-product attention 和我们的算法是一致的,除了尺度因子 ![]() 。Additive attention 用带有单层 hidden layer 的 feed-forward network来计算 compatibility function。这两种在理论复杂性上来说,dot-product attention 是更快,更省空间的方法,因为其可以用 highly optimized matrix multiplication code 来实现。
。Additive attention 用带有单层 hidden layer 的 feed-forward network来计算 compatibility function。这两种在理论复杂性上来说,dot-product attention 是更快,更省空间的方法,因为其可以用 highly optimized matrix multiplication code 来实现。
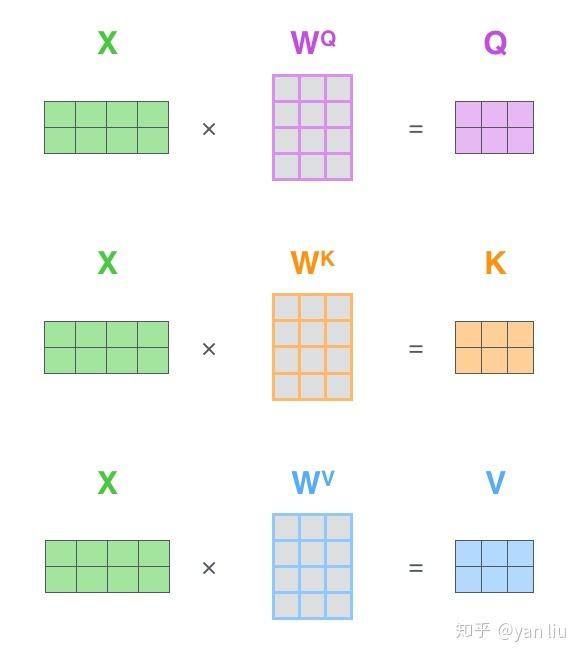
看到这里,产生的一个疑问是:哪里来的什么 query,key, values ???
其实就是用输入 x 和三个不同权重的矩阵相乘,分别得到三个不同的向量 q, k, v,即:
有了这三个值,就可以按照公式 1计算得到 输出的 z 了:
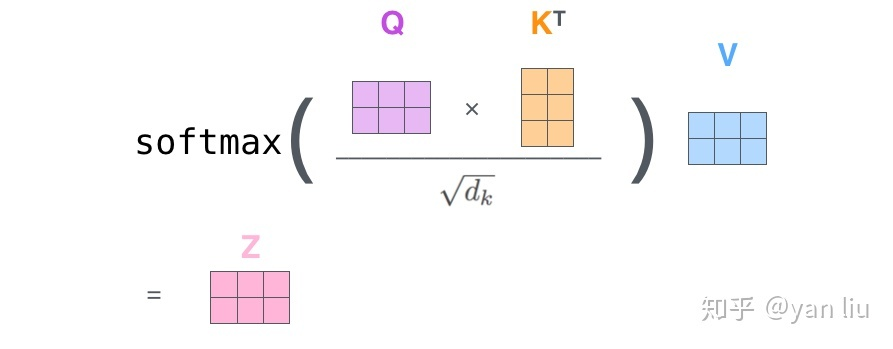
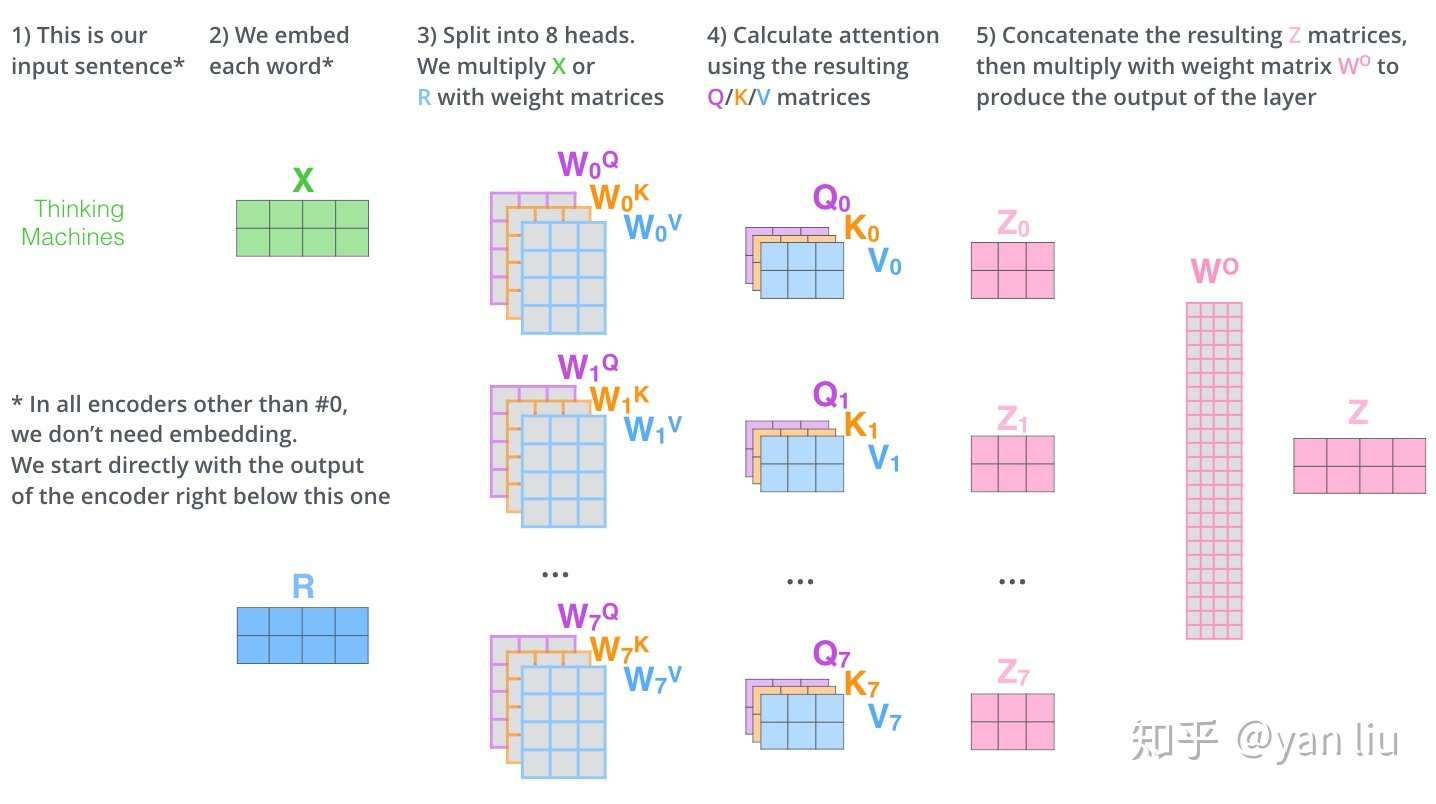
2.2.2. Multi-Head Attention:


====>>>> 没看懂???没关系,我们来看中文版:

上面的过程可以用如下的可视化图来表示:
2.3. Position-wise Feed-Forward Networks:
除了 attention sub-layers,encoder 和 decoder 中的每一层都包含一个 fc 前向网络,是用于分别和独立进行位置编码的。这包含了两个线性转换:
![]()
线性转换在不同的位置上是相同的,他们不同的 layer 用不同的参数。
2.4. Embeddings and Softmax:
和其他序列转换模型类似,作者也用学习到的 embedding 来转换 input tokens 和 输出 tokens 为向量。同时也利用常规学习的线性变换和 softmax function 来将 decoder 输出转换为 下一个符号的概率。在本文的模型中,作者将两个 embedding layers 和 pre-softmax linear transformation 共享权重。在 embedding layer,用![]() 对这些权重进行加权。
对这些权重进行加权。
2.5. Positional Encoding:
由于本文的模型没有任何的 RNN 和 CNN 操作,为了利用序列中的次序信息,作者必须将序列中的相对位置或者绝对位置进行编码,以得到更好的效果。为了达到这个目标,作者在输入 embedding 的位置添加了 “positional encodings” 。位置编码 和 embedding 一样拥有相同的维度,这样才可以将其和 embedding 进行相加操作。位置编码有很多种选择,本文中,作者选择 sine and cosine functions of different frequencies:
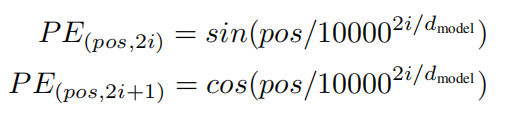
其中,pos 是位置,i 是维度。位置编码每一个维度对应了正弦曲线 (sinusoid)。
作者这么设计的原因是考虑到在NLP任务重,除了单词的绝对位置,单词的相对位置也非常重要。根据公式 以及
,这表明位置
的位置向量可以表示为位置
的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
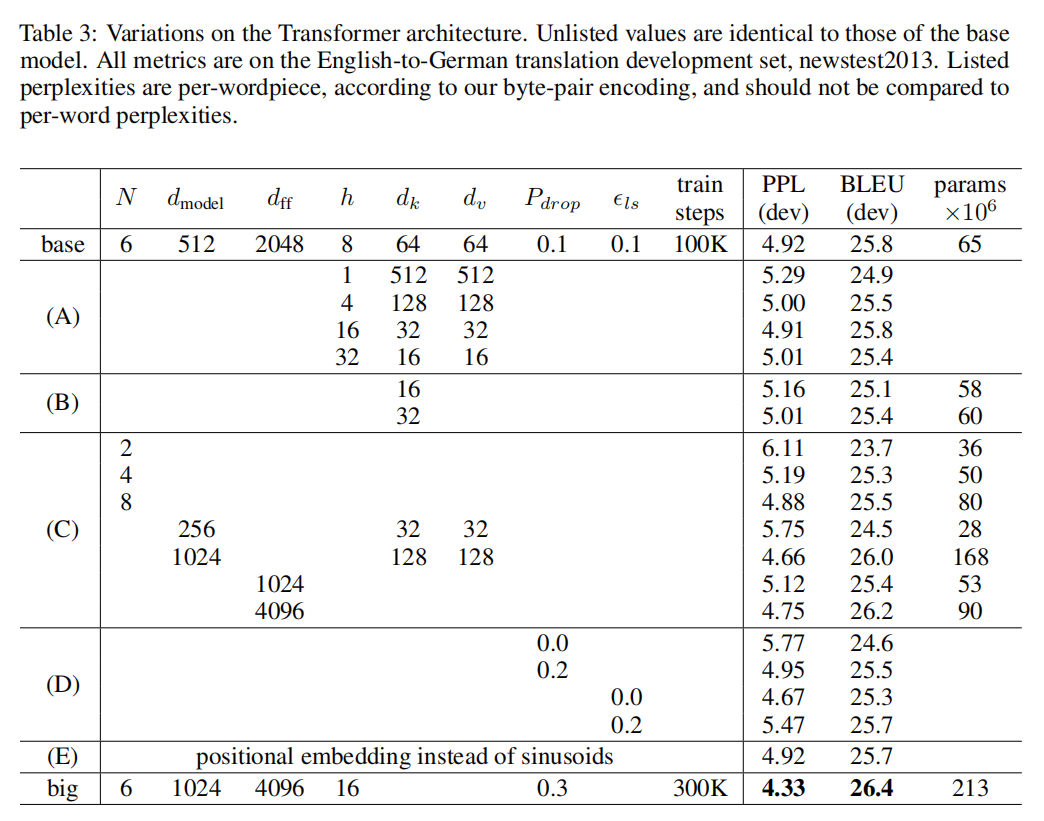
3. Experiments: