Visual Semantic Reasoning for Image-Text Matching
2020-03-06 15:17:02
Paper: https://arxiv.org/pdf/1909.02701.pdf
Code: https://github.com/KunpengLi1994/VSRN
1. Background and Motivation:
本文提出利用 GCN 的方法来推理图像中的关系来提升 Image-Text matching 的性能。本文首先挖掘图像中的显著性区域,然后,显著性区域检测可以用 Bottom-Up attention 来实现,这和 人类的视觉系统是一致的。具体来说,这种 bottom-up attention 模型可以用 faster RCNN 来实现,然后构建这些显著性物体之间的联系,用 GCN 进行推理来生成具有 semantic relationship 的特征。
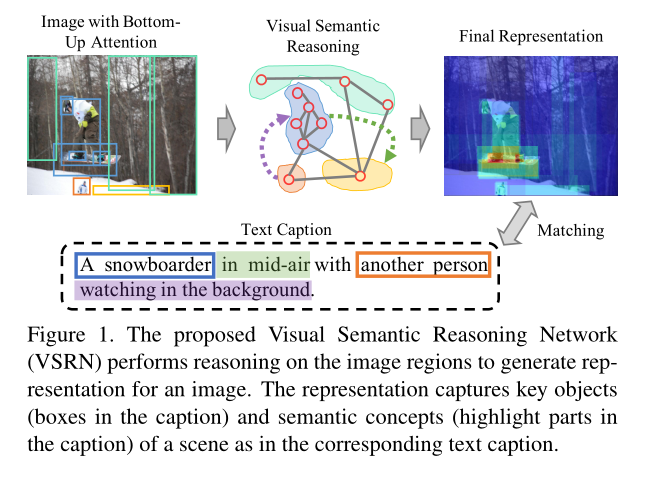
2. Learning Alignments with Visual Semantic Reasoning:
算法的大致流程如下所示:

2.1. Image Representation by Bottom-Up Attention:
本文与 “Stacked Cross Attention for Image-Text Matching” 保持一致,也采用基于 faster RCNN 模型的 bottom-up attention 来得到图像中的物体或者显著性的区域。该模型是在 Visual Genomes dataset 上预训练得到的。由于该模型是用于预测 instance classes 和 attribute classes,而不是 object classes,所以说,可以利用 rich semantic meaning 来帮助学习特征表示。对于每一个选中的区域 i,作者利用average pooling layer 来提取特征,得到 2048 维的特征。然后用一个 fc layer 来将 fi 转换成一个 D维的 embedding:
![]()
然后 V = {v1, ... , vk} 被创建来表示每一个图像,vi 代表图像中的 object 或者 salient region。
2.2. Region Relationship Reasoning:
重头戏来了,作者也构建了不同物体之间的联系,来进行全局信息的推理。具体来说,作者用 pairwise affinity 来构建他们之间的关系:
![]()
然后,构建了一个 graph $G_r = (V, E)$,其中 V 是检测到的 regions 的集合,边的集合 E 是根据 affinity matrix R 得到的。作者采用 GCN 在 fully-connected graph 上进行推理。每一个节点的响应是基于其近邻得到的,作者在原始 GCN 的基础上添加了残差连接,即:
![]()
其中,Wg 是 GCN 层的权重矩阵。Wr 是残差结构的权重矩阵。作者对 affinity matrix R 按照 row 进行归一化。输出的 V* 是 image region nodes 增强之后的表达。
2.3. Global Semantic Reasoning:
基于上述带有关系信息的 region features,作者进一步进行了全局语义推理来选择具有判别性的信息,从而剔除掉不重要的信息,来得到整幅图的最终表达。具体的,作者将 region features V* ={v1*, ... , vk*} 的特征依次输入到 GRUs 模型中。在推理的过程中,整个场景的描述将会逐渐的增长和更新。在每一个推理步骤 i,一个更新 gate zi 分析了当前输入的 region feature vi* 以及整幅图像的描述,来决定更新多少 memory cell。更新门的计算过程如下:![]()
其中,$delta_z$ 是 sigmoid 激活函数。$W_z, U_z, b_z$ 是权重和偏置。
新增的 content 将会帮助增加整个场景的描述:
![]()
$r_i$ 和 update gate 的计算机制类似:
![]()
然后,当前时刻,整个场景 mi 的描述计算如下:
![]()
由于每一个 vi* 包含了全局推理信息,mi 的更新实际上依赖于 graph 拓扑结构,同时考虑了当前 local region 和 全局语义关系。作者将最后时刻的 memory cell 当做是整幅图的表达。
2.4. Learning Alignments by Joint Matching and Generation:
为了连接视觉和语言领域,作者利用基于 GRU 的文本编码器将 text caption 映射到 D维的向量。然后,联合优化 matching 和 generation 来对其文本 C 和 图像 I。对于 matching 的部分,作者采用 hinge-based triplet loss:
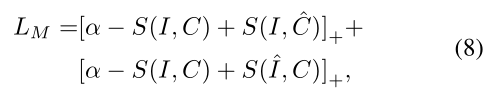
该 hinge loss 由两个部分组成,分别是 C和 I作为 queries。我们利用常规 inner product S(*)。对于 generation 的部分,学习到的视觉表达应该和 GT captions 保持一致。具体来说,作者采用了 sequence-to-sequence 模型来达到这个目标。所用到的损失函数为:

最终的 loss function 定义为这两个目标函数的联合优化:
![]()
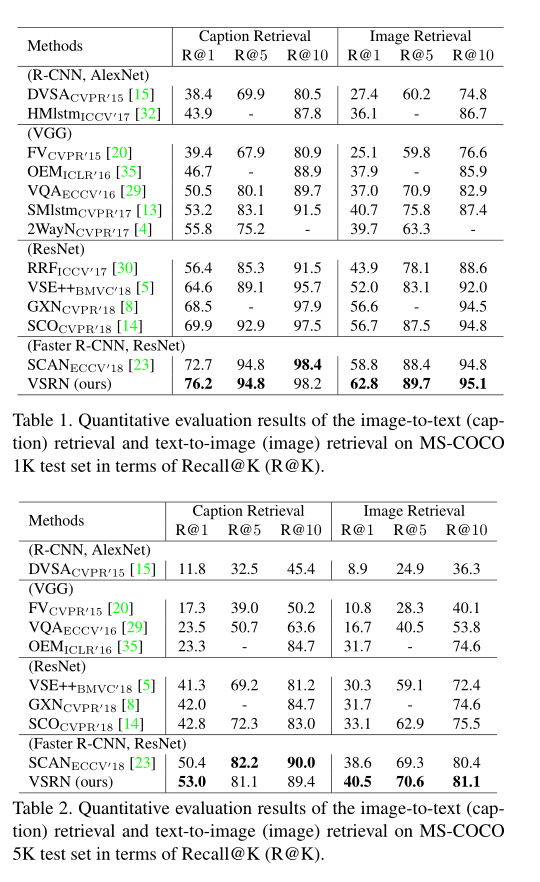
3. Experiment: