Learning to Track Any Object
2019-10-28 12:14:49
Paper: https://arxiv.org/abs/1910.11844
1. Background and Motivation:

在本文开始部分,作者就提到 object prior 对于跟踪有非常重要的意义。特定类别物体的跟踪是知道物体类别的,如行人跟踪,车辆跟踪等。但是,一般的跟踪,比如用户手动设置物体的跟踪,就是 generic 的,并且很难知道这种先验信息,即:model-free tracking。然而,generic objects 仍然共享一组 objectness traits。那么,我们如何将这种隐式的约束转换为一种有用的先验信息呢?
在这个工作中,作者稍微改动了 category-specific appearance models,使其变成了 category-agnostic tracking。本质上来说,我们表明 model-free tracking 在有了模型之后,变得非常简单!想达到这种目标,需要处理如下两个关键的问题,如图 1 所示:
1). 如何将 category specific prior 改为 generic objectness prior?
2). 如何进一步的将这种 generic prior 改为 particular instance of interst?
为了处理问题 1,作者构建了一个联合模型进行特定类别的物体检测和与类别无关的跟踪(build a joint model for category-specific object detection and category-agnostic tracking)。该方法是基于 Mask R-CNN 物体检测框架。对于跟踪,其将额外的 object template 作为输入,计算其 feature embedding。然后该模板被用于计算 the object of intersting 和 new frame。该相似性图又被用于重新加权空间特征,以检测感兴趣的物体。更重要的是,联合的在图像和视频数据集上进行训练,允许我们从多样化的图像数据,捕获 generic object appearance model。然后学习将其用于与类别无关的跟踪。
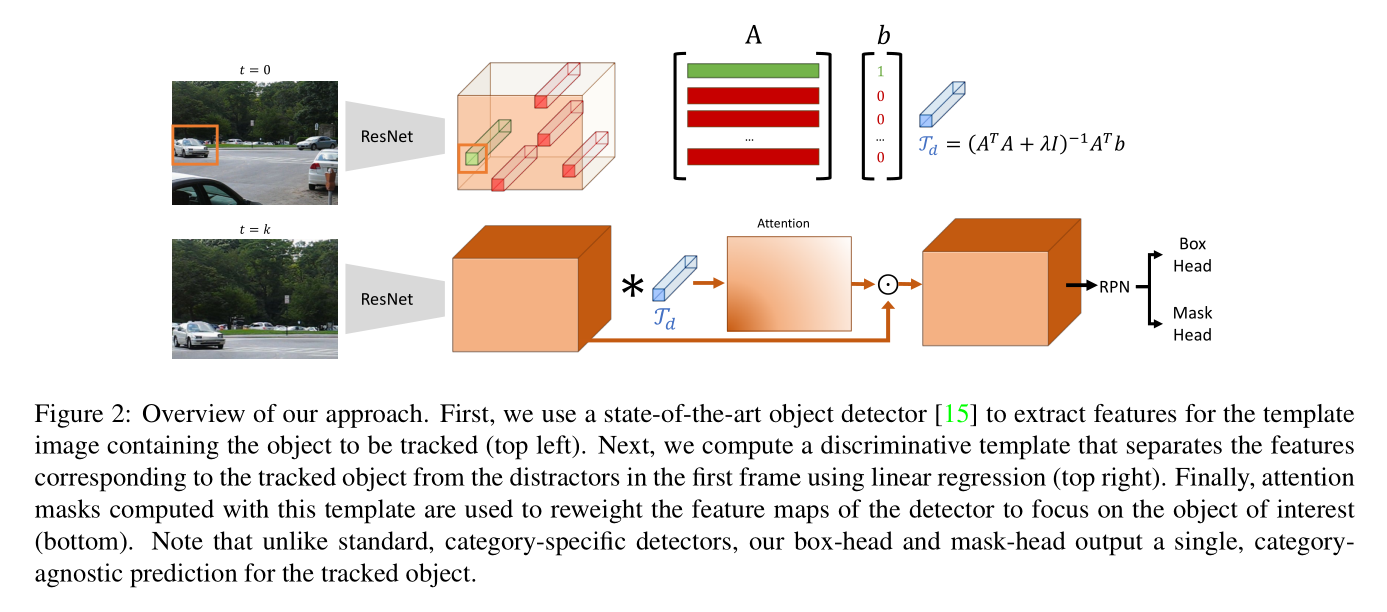
为了处理问题 2,本文计算一个线性分类器(the object of interest and other objects in the first frame)。
本文的创新可以总结为如下三点:
1). we incorporate an objectness prior in a generic tracker with a joint model for object detection, tracking, instance and video object segmentation;
2). we propose a lightweight strategy for computing discriminative object templates in an end-to-end fashion for efficiently handling distractors;
3). our method demonstrates state-of-the-art results on three benchmark datasets for object tracking and video object segmentation.
2. The Proposed Tracker :
2.1 Preliminaries:
本小节主要是讲解了如何将 Mask R-CNN 物体检测器,改装为 tracker 的过程;
2.2 Tracking as generalized object detection:
2.3 Joint Detection and Tracking:
2.4 Discriminative Templates:
该小节主要是想学一种 robust feature,并且举了一个例子。如下图所示,作者发现原本的 feature map,在有些视频上区分性不足,左下角是常规的响应图,可以发现很差劲,可能导致跟踪失败;而作者提出方法得到的 feature map,则要好很多,如右下角的 feature map。

回顾 FPN 中每一个位置的 feature vector 编码了在那个位置上的物体(a feature vector at each location encodes an object centered at that region at the corresponding scale)。所以,采样出一个足够大的特征池,可以提供给我们训练集,来学习一个线性分类器。此外,这种判别器可以有效地通过最小二乘方法得到闭合解(a closed form via least squares)。特别的,给定一个 template T,以及一组 negative N,我们定义 data matrix A,及其 label vector y,如下所示:
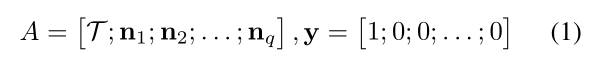
然后,我们想要找到一个 vector Td,称为 discriminative template,可以最小化:

然后我们可以得到闭合解:
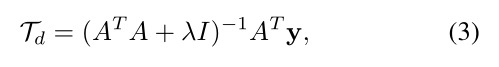
其中,I 是单位矩阵,$lambda$ 是正则化超参数。我们然后利用 Td 来计算相似性图:![]()
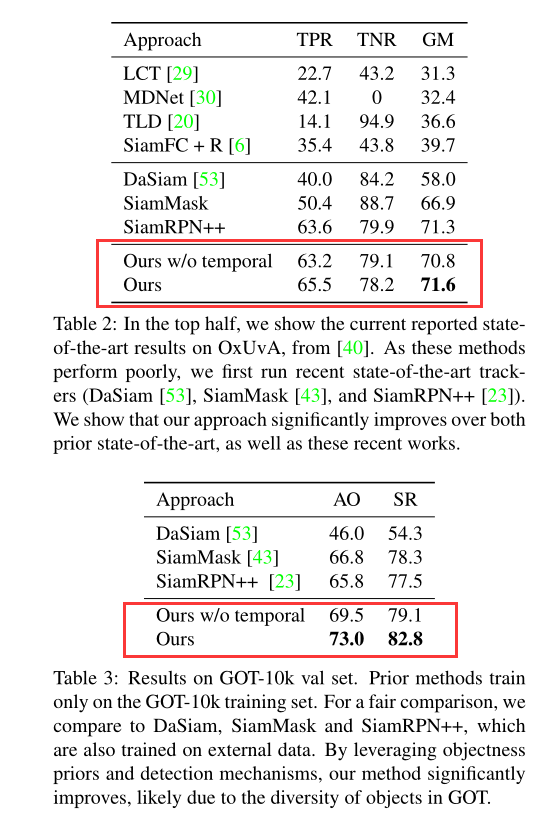
3. Experiments:


==