High Performance Visual Tracking with Siamese Region Proposal Network
2018-11-26 18:32:02
Paper:http://openaccess.thecvf.com/content_cvpr_2018/papers/Li_High_Performance_Visual_CVPR_2018_paper.pdf
PyTorch Code:https://github.com/songdejia/siamese-RPN-pytorch
Train Code: https://github.com/MathsXDC/DaSiamRPNWithOfflineTraining
TensorFlow Code:https://github.com/makalo/Siamese-RPN-tensorflow
Reference Code:https://github.com/zkisthebest/Siamese-RPN
Another Implementation based on PyTorch with deeper and wider backbone network (SiamDW, CVPR-2019): https://github.com/researchmm/SiamDW (all the train and test code !!!)
1. Background and Motivation :
现有的跟踪方法主要分为两种:
1). 相关滤波跟踪方法;也有将 deep feature 结合到 CF 方法中,但是速度不够快;
2). 完全基于深度网络的跟踪方法,由于没有用到 domain-specific information,效果并不是很突出。
本文将 RPN 引入到跟踪过程中,极大地改善了跟踪效果。主要包含两个分支:
1). Template branch;
2). Detection branch;
在测试阶段,作者将其看做是:local one-shot detection framework,第一帧中的 BBox 仅提供 exemplar。作者将 template branch 重新看做是参数来预测 detection kernels,类似于 meta-learner。meata-learner 和 detection branch 都仅仅用 RPN 的监督来进行端到端的训练。在 online tracking 过程中,Template branch 会被修剪以达到加速的目的。本文所提出的方法也是第一次将 online tracking 看做是 one-shot detection 任务。
本文所提出的 Siamese RPN 的流程图如下所示:
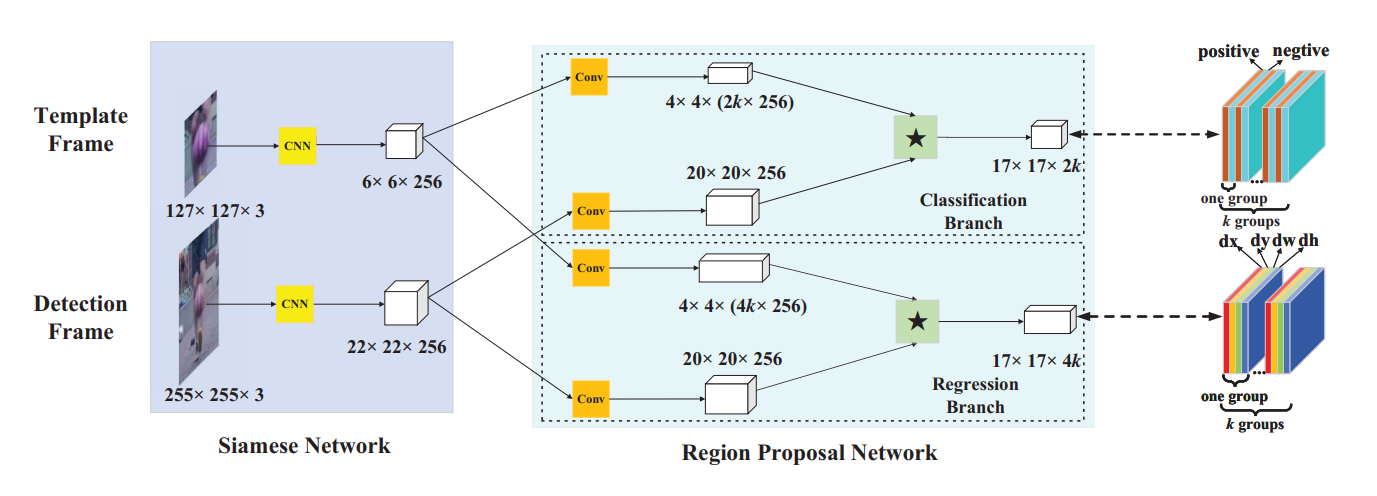
2. Siamese-RPN framework:
2.1 Siamese feature extraction subnetwork
在孪生网络中, 作者采用不带 padding 的全卷积网络。骨干网络是修改后的 AlexNet,Siamese tracker 的示意图如下:

2.2 Region Proposal Subnetwork
该 RPN 子网络包含两个部分:pair-wise correlation section 以及 supervision section。
Supervision section 包含两个分支:一个是用于前景和背景分类的分支,另一个分支用于 proposal 回归。
如果有 k 个 anchors,网络需要输出 2k channel 以进行分类,4k channels 以进行回归。所以,pair-wise correlation 首先增加 channel 个数为两个部分。另一个分支也分为两路,即:reg 和 cls。Template 分支输出的 feature 可以看做是 “kernel”,在 search region 的 feature 上进行卷积操作。在 classification 和 regression branch 上都要进行 correlation 操作:
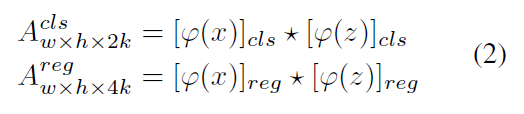
当进行训练时,作者采用 Faster RCNN 的损失函数。用交叉熵损失函数来训练 classification 分支,L1 loss 用于 regression 分支的训练。
Ax, Ay, Aw, Ah 代表 anchor boxes 的中心点和形状,Tx, Ty, Tw, Th 代表 GT boxes,所以,归一化的距离可以表达为:
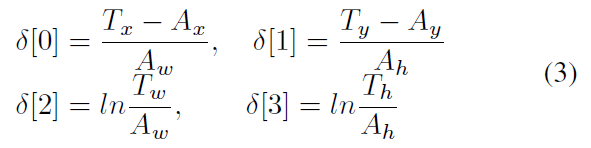
然后,其通过 L1 loss,具体表达形式为:
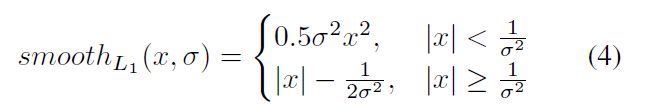
最终,作者优化的损失函数为:
![]()
其中,Lcls 是交叉熵损失,Lreg 是:
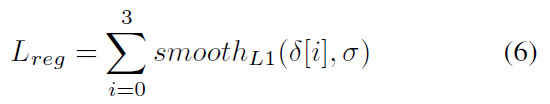
2.3 Training Phase
在训练阶段,ImageNet VID 和 Youtube-BB 被用于采集 sample pairs 来进行相似度匹配的训练。
anchors 的选择是基于 IoU 进行的,当 IoU 大于设定的阈值(文中设置为 0.6),并且是正样本的时候,被当做是 anchors。负样本则认为是那些 IoU 低于 0.3 的。
对于一个 training pair,作者设置最多 16 个正样本,总共 64 个样本。
3. Tracking as one-shot detection:
==