了解残差网络
- ResNet是何凯明在2015年提出的一种网络结构
- ResNet又名残差神经网络,指的是在传统卷积神经网络中加入残差学习(residual learning)的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度
- ResNet网络是参考了VGG19网络,在其基础上进行了修改,并通过短路机制加入了残差单元
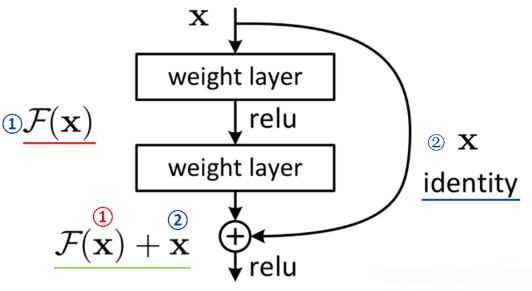
残差块
- 输入的x分成两个路线,一条路保持原始值,另一条路进行卷积
- 残差块中有两个3x3的卷积层
- 输出两个结果相加
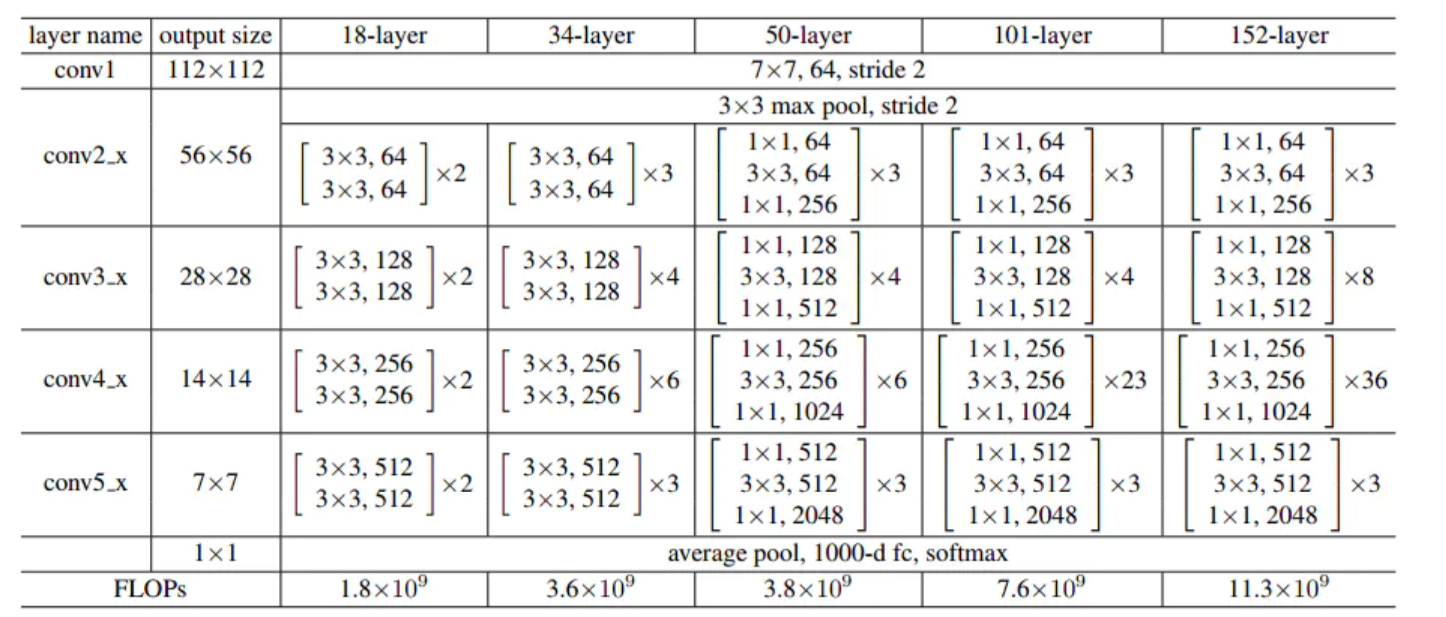
不同的残差网络
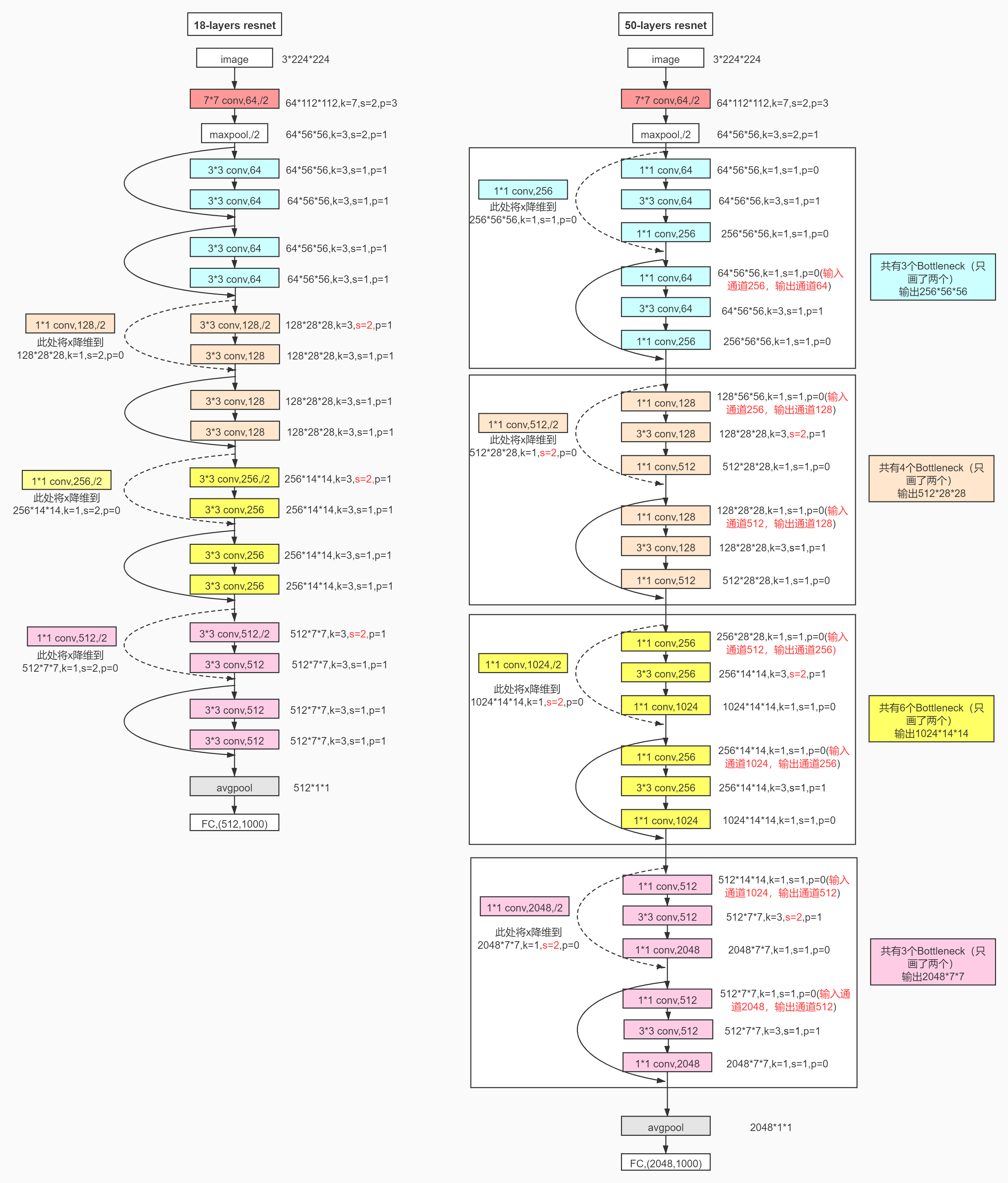
详细的网络过程
创建残差块
import torch
import time
from torch import nn,optim
import torch.nn.functional as F
import pytorch_deep as pyd
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 创建残差块 rest block
class Residual(nn.Module):
def __init__(self, in_channels,out_channels,use_1x1conv = False,stride = 1):
super(Residual,self).__init__()
self.conv1 = nn.Conv2d(in_channels,out_channels,kernel_size=3,padding = 1, stride = stride)
self.conv2 = nn.Conv2d(out_channels,out_channels,kernel_size=3,padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(in_channels,out_channels,kernel_size=3,padding = 1, stride = stride)
else:self.conv3 = None
self.bn1 = nn.BatchNorm2d(out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self,X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return F.relu(X+Y)
blk = Residual(3,3)
X = torch.rand((4,3,6,6))
print(blk(X).shape)
torch.Size([4, 3, 6, 6])
RestNet-18 模型
前两层网络
net = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(in_channels, out_channels, num_residuals,first_block=False):
if first_block:
assert in_channels == out_channels # 第⼀个模块的通道数同输⼊通道数⼀致
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(in_channels, out_channels,use_1x1conv=True, stride=2))
else:
blk.append(Residual(out_channels, out_channels))
return nn.Sequential(*blk)
net.add_module("resnet_block1", resnet_block(64, 64, 2,first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", pyd.GlobalAvgPool2d()) #GlobalAvgPool2d的输出: (Batch, 512, 1, 1)
net.add_module("fc", nn.Sequential(pyd.FlattenLayer(),
nn.Linear(512, 10)))
X = torch.rand((1, 1, 224, 224))
for name, layer in net.named_children():
X = layer(X)
print(name, ' output shape: ', X.shape)
0 output shape: torch.Size([1, 64, 112, 112])
1 output shape: torch.Size([1, 64, 112, 112])
2 output shape: torch.Size([1, 64, 112, 112])
3 output shape: torch.Size([1, 64, 56, 56])
resnet_block1 output shape: torch.Size([1, 64, 56, 56])
resnet_block2 output shape: torch.Size([1, 128, 28, 28])
resnet_block3 output shape: torch.Size([1, 256, 14, 14])
resnet_block4 output shape: torch.Size([1, 512, 7, 7])
global_avg_pool output shape: torch.Size([1, 512, 1, 1])
fc output shape: torch.Size([1, 10])
获取数据集并训练
batch_size = 256
# 如出现“out of memory”的报错信息,可减⼩batch_size或resize
train_iter, test_iter = pyd.load_data_fashion_mnist(batch_size,resize=96)
lr, num_epochs = 0.001, 5
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
pyd.train_ch5(net, train_iter, test_iter, batch_size, optimizer,device, num_epochs)
training on cuda
epoch 1, loss 0.4026, train acc 0.850, test acc 0.896,time 39.2 sec
epoch 2, loss 0.1229, train acc 0.908, test acc 0.890,time 39.0 sec
epoch 3, loss 0.0685, train acc 0.925, test acc 0.897,time 39.2 sec
epoch 4, loss 0.0449, train acc 0.933, test acc 0.921,time 39.2 sec
epoch 5, loss 0.0304, train acc 0.944, test acc 0.912,time 39.3 sec