这是学习网络编程后写的一个练手的小程序,可以帮助复习I/O模型,epoll使用,线程池,HTTP协议等内容。
程序代码是基于《Linux高性能服务器编程》一书编写的。
首先回顾程序中的核心内容和主要问题,最后给出相关代码。
0. 功能和I/O模型
实现简易的HTTP服务端,现仅支持GET方法,通过浏览器访问可以返回相应内容。
I/O模型采用Reactor(I/O复用 + 非阻塞I/O) + 线程池。 使用epoll事件循环用作事件通知,如果listenfd上可读,则调用accept,把新建的fd加入epoll中;
是已连接sockfd,将其加入到线程池中由工作线程竞争执行任务。
1. 线程池怎么实现?
程序采用c++编写,要自己封装一个简易的线程池类。大致思路是创建固定数目的线程(如跟核数相同),然后类内部维护一个生产者—消费者队列。
提供相应的添加任务(生产者)和执行任务接口(消费者)。按照操作系统书中典型的生产者—消费者模型维护增减队列任务(使用mutex和semaphore)。
mutex用于互斥,保证任意时刻只有一个线程读写队列,semaphore用于同步,保证执行顺序(队列为空时不要读,队列满了不要写)。
2. epoll用条件触发(LT)还是边缘触发(ET)?
考虑这样的情况,一个工作线程在读一个fd,但没有读完。如果采用LT,则下一次事件循环到来的时候,又会触发该fd可读,此时线程池很有可能将该fd分配给其他的线程处理数据。
这显然不是我们想要看到的,而ET则不会在下一次epoll_wait的时候返回,除非读完以后又有新数据才返回。所以这里应该使用ET。
当然ET用法在《Tinychatserver: 一个简易的命令行群聊程序》也有总结过。用法的模式是固定的,把fd设为nonblocking,如果返回某fd可读,循环read直到EAGAIN。
3. 继续上面的问题,如果某个线程在处理fd的同时,又有新的一批数据发来(不是老数据没读完,是来新数据了),即使使用了ET模式,因为新数据的到来,仍然会触发该fd可读,所以仍然存在将该fd分给其他线程处理的情况。
这里就用到了EPOLLONESHOT事件。对于注册了EPOLLONESHOT事件的文件描述符,操作系统最大触发其上注册的一个可读、可写或者异常事件,且只触发一次。
除非我们使用epoll_ctl函数重置该文件描述符上注册的EPOLLONESHOT事件。这样,当一个线程处理某个socket时,其他线程是不可能有机会操作该socket的,
即可解决该问题。但同时也要注意,如果注册了EPOLLONESHOT的socket一旦被某个线程处理完毕,则应该立即重置这个socket上的EPOLLONESHOT事件,
以确保下一次可读时,其EPOLLIN事件能够触发。
4. HTTP协议解析怎么做?数据读到一半怎么办?
首先理解这个问题。HTTP协议并未提供头部字段的长度,判断头部结束依据是遇到一个空行,该空行只包含一对回车换行符(<CR><LF>)。同时,如果一次读操作没有读入整个HTTP请求
的头部,我们必须等待用户继续写数据再次读入(比如读到 GET /index.html HTT就结束了,必须维护这个状态,下一次必须继续读‘P’)。
即我们需要判定当前解析的这一行是什么(请求行?请求头?消息体?),还需要判断解析一行是否结束?
解决上述问题,可以采取有限状态机。
参考【1】中设计方式,设计主从两个状态机(主状态机解决前半部分问题,从状态机解决后半部分问题)。
先分析从状态机,从状态机用于处理一行信息(即parse_line函数)。其中包括三个状态:LINE_OPEN, LINE_OK,LINE_BAD,转移过程如下所示:
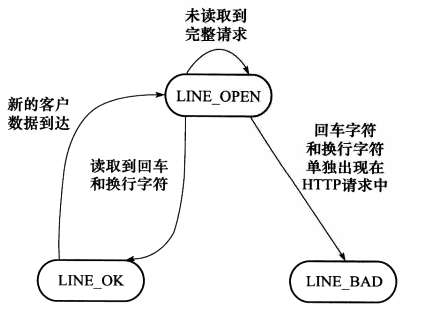
当从状态机parse_line读到完整的一行,就可以将改行内容递交给process_read函数中的主状态机处理。
主状态机也有三种状态表示正在分析请求行(CHECK_STATE_REQUESTINE),正在分析头部字段(CHECK_STATE_HEADER),和正在分析内容(CHECK_CONTENT)。
主状态机使用checkstate变量来记录当前的状态。
如果当前的状态是CHECK_STATE_REQUESTLINE,则表示parse_line函数解析出的行是请求行,于是主状态机调用parse_requestline来分析请求行;
如果当前的状态是CHECK_STATE_HEADER,则表示parse_line函数解析出来的是头部字段,于是主状态机调用parse_header来分析头部字段。
如果当前状态是CHECK_CONTENT,则表示parse_line函数解析出来的是消息体,我们调用parse_content来分析消息体(实际上实现时候并没有分析,只是判断是否完整读入)
checkstate变量的初始值是CHECK_STATE_REQUESTLINE,调用相应的函数(parse_requestline,parse_header)后更新checkstate实现状态转移。
与主状态机有关的核心函数如下:
http_conn::HTTP_CODE http_conn::process_read()//完整的HTTP解析 { LINE_STATUS line_status = LINE_OK; HTTP_CODE ret = NO_REQUEST; char* text = 0; while ( ( ( m_check_state == CHECK_STATE_CONTENT ) && ( line_status == LINE_OK ) ) || ( ( line_status = parse_line() ) == LINE_OK ) ){//满足条件:正在进行HTTP解析、读取一个完整行 text = get_line();//从读缓冲区(HTTP请求数据)获取一行数据 m_start_line = m_checked_idx;//行的起始位置等于正在每行解析的第一个字节 printf( "got 1 http line: %s", text ); switch ( m_check_state )//HTTP解析状态跳转 { case CHECK_STATE_REQUESTLINE://正在分析请求行 { ret = parse_request_line( text );//分析请求行 if ( ret == BAD_REQUEST ) { return BAD_REQUEST; } break; } case CHECK_STATE_HEADER://正在分析请求头部 { ret = parse_headers( text );//分析头部 if ( ret == BAD_REQUEST ) { return BAD_REQUEST; } else if ( ret == GET_REQUEST ) { return do_request();//当获得一个完整的连接请求则调用do_request分析处理资源页文件 } break; } case CHECK_STATE_CONTENT:// 解析消息体 { ret = parse_content( text ); if ( ret == GET_REQUEST ) { return do_request(); } line_status = LINE_OPEN; break; } default: { return INTERNAL_ERROR;//内部错误 } } } return NO_REQUEST; }
5. HTTP响应怎么做?怎么发送效率高一些?
首先介绍readv和writev函数。其功能可以简单概括为对数据进行整合传输及发送,即所谓分散读,集中写。
也就是说,writev函数可以把分散保存在多个缓冲中的数据一并发送,通过readv函数可以由多个缓冲分别接收。因此适当采用这两个函数可以减少I/O次数。
例如这里要做的HTTP响应。其包含一个状态行,多个头部字段,一个空行和文档的内容。前三者可能被web服务器放置在一块内存中,
而文档的内容则通常被读入到另外一块单独的内存中(通过read函数或mmap函数)。这里可以采用writev函数将他们一并发出。
相关接口如下:
ssize_t readv(int fd, const struct iovec *iov, int iovcnt); ssize_t writev(int fd, const struct iovec *iov, int iovcnt); 其中第二个参数为如下结构体的数组 struct iovec { void *iov_base; /* Starting address */ size_t iov_len; /* Number of bytes to transfer */ }; 第三个参数为第二个参数的传递的数组的长度。
这里还可以再学习一下mmap与munmap函数。但是这里关于mmap与read效率的比较,应该没有那么简单的答案。mmap可以减少系统调用和内存拷贝,但是其引发的pagefault也是开销。效率的比较取决于不同系统对于这两个效率实现的不同,所以这里就简单谈一谈用法。
#include <sys/mman.h> /**addr参数允许用户使用某个特定的地址作为这段内存的起始地址,设置为NULL则自动分配地址。 *length参数指定内存段的长度. *prot参数用来设置内*存段的访问权限,比如PROT_READ可读, PROT_WRITE可写。 *flags控制内存段内容被修改后程序的行为。如MAP_PRIVATE指内存段为调用进程所私有,对该内存段的修改不会反映到被映射的文件中。 */ void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); int munmap(void *addr, size_t length);
所以根据不同情况(200,404)填充HTTP的程序如下:


bool http_conn::process_write( HTTP_CODE ret )//填充HTTP应答 { switch ( ret ) { case INTERNAL_ERROR: { add_status_line( 500, error_500_title ); add_headers( strlen( error_500_form ) ); if ( ! add_content( error_500_form ) ) { return false; } break; } case BAD_REQUEST: { add_status_line( 400, error_400_title ); add_headers( strlen( error_400_form ) ); if ( ! add_content( error_400_form ) ) { return false; } break; } case NO_RESOURCE: { add_status_line( 404, error_404_title ); add_headers( strlen( error_404_form ) ); if ( ! add_content( error_404_form ) ) { return false; } break; } case FORBIDDEN_REQUEST: { add_status_line( 403, error_403_title ); add_headers( strlen( error_403_form ) ); if ( ! add_content( error_403_form ) ) { return false; } break; } case FILE_REQUEST://资源页文件可用 { add_status_line( 200, ok_200_title ); if ( m_file_stat.st_size != 0 ) { add_headers( m_file_stat.st_size );//m_file_stat资源页文件状态 m_iv[ 0 ].iov_base = m_write_buf;//写缓冲区 m_iv[ 0 ].iov_len = m_write_idx;//长度 m_iv[ 1 ].iov_base = m_file_address;//资源页数据内存映射后在m_file_address地址 m_iv[ 1 ].iov_len = m_file_stat.st_size;//文件长度就是该块内存长度 m_iv_count = 2; return true; } else { const char* ok_string = "<html><body></body></html>";//请求页位空白 add_headers( strlen( ok_string ) ); if ( ! add_content( ok_string ) ) { return false; } } } default: { return false; } } m_iv[ 0 ].iov_base = m_write_buf; m_iv[ 0 ].iov_len = m_write_idx; m_iv_count = 1; return true; }
bool http_conn::write()//将资源页文件发送给客户端 { int temp = 0; int bytes_have_send = 0; int bytes_to_send = m_write_idx; if ( bytes_to_send == 0 ) { modfd( m_epollfd, m_sockfd, EPOLLIN );//EPOLLONESHOT事件每次需要重置事件 init(); return true; } while( 1 )// { temp = writev( m_sockfd, m_iv, m_iv_count );//集中写,m_sockfd是http连接对应的描述符,m_iv是iovec结构体数组表示内存块地址,m_iv_count是数组的长度即多少个内存块将一次集中写到m_sockfd if ( temp <= -1 )//集中写失败 { if( errno == EAGAIN ) { modfd( m_epollfd, m_sockfd, EPOLLOUT );//重置EPOLLONESHOT事件,注册可写事件表示若m_sockfd没有写失败则关闭连接 return true; } unmap();//解除内存映射 return false; } bytes_to_send -= temp;//待发送数据 bytes_have_send += temp;//已发送数据 if ( bytes_to_send <= bytes_have_send ) { unmap();//该资源页已经发送完毕该解除映射 if( m_linger )//若要保持该http连接 { init();//初始化http连接 modfd( m_epollfd, m_sockfd, EPOLLIN ); return true; } else { modfd( m_epollfd, m_sockfd, EPOLLIN ); return false; } } } }
6.忽略SIGPIPE
这是一个看似很小,但是如果不注意会直接引发bug的地方。如果往一个读端关闭的管道或者socket中写数据,会引发SIGPIPE,程序收到SIGPIPE信号后默认的操作时终止进程。
这也就是说,如果客户端意外关闭,那么服务器可能也就跟着直接挂了,这显然不是我们想要的。所以网络程序中服务端一般会忽略SIGPIPE信号。
7. 程序代码
程序中有比较详细的注释,虽然主干在上面问题中分析过了,但是诸如如何解析一行数据之类的操作,还是很烦的...可以直接参考代码
1 #ifndef THREADPOOL_H 2 #define THREADPOOL_H 3 4 #include <list> 5 #include <cstdio> 6 #include <exception> 7 #include <pthread.h> 8 #include "locker.h" //简单封装了互斥量和信号量的接口 9 10 //线程池类模板参数T是任务类型,T中必须有接口process 11 template< typename T > 12 class threadpool 13 { 14 public: 15 threadpool( int thread_number = 8, int max_requests = 10000 );//线程数目和最大连接处理数 16 ~threadpool(); 17 bool append( T* request ); 18 19 private: 20 static void* worker( void* arg );//线程工作函数 21 void run(); //启动线程池 22 23 private: 24 int m_thread_number;//线程数量 25 int m_max_requests;//最大连接数目 26 pthread_t* m_threads;//线程id数组 27 std::list< T* > m_workqueue;//工作队列:各线程竞争该队列并处理相应的任务逻辑T 28 locker m_queuelocker;//工作队列互斥量 29 sem m_queuestat;//信号量:用于工作队列 30 bool m_stop;//终止标志 31 }; 32 33 template< typename T > 34 threadpool< T >::threadpool( int thread_number, int max_requests ) : 35 m_thread_number( thread_number ), m_max_requests( max_requests ), m_stop( false ), m_threads( NULL ) 36 { 37 if( ( thread_number <= 0 ) || ( max_requests <= 0 ) ) 38 { 39 throw std::exception(); 40 } 41 42 m_threads = new pthread_t[ m_thread_number ];//工作线程数组 43 if( ! m_threads ) 44 { 45 throw std::exception(); 46 } 47 48 for ( int i = 0; i < thread_number; ++i )//创建工作线程 49 { 50 printf( "create the %dth thread ", i ); 51 if( pthread_create( m_threads + i, NULL, worker, this ) != 0 ) 52 { 53 delete [] m_threads; 54 throw std::exception(); 55 } 56 if( pthread_detach( m_threads[i] ) ) //分离线程使得其它线程回收和杀死该线程 57 { 58 delete [] m_threads; 59 throw std::exception(); 60 } 61 } 62 } 63 64 template< typename T > 65 threadpool< T >::~threadpool() 66 { 67 delete [] m_threads; 68 m_stop = true; 69 } 70 71 template< typename T > 72 bool threadpool< T >::append( T* request )//向工作队列添加任务T 73 { 74 m_queuelocker.lock();//对工作队列操作前加锁 75 if ( m_workqueue.size() > m_max_requests )//任务队列满,不能加进去 76 { 77 m_queuelocker.unlock(); 78 return false; 79 } 80 m_workqueue.push_back( request ); 81 m_queuelocker.unlock(); 82 m_queuestat.post();//信号量的V操作,多了一个工作任务T使得信号量+1 83 return true; 84 } 85 86 template< typename T > 87 void* threadpool< T >::worker( void* arg )//工作线程函数 88 { 89 threadpool* pool = ( threadpool* )arg; //获取线程池对象,之前创建的时候传的this 90 pool->run(); //调用线程池run函数 91 return pool; 92 } 93 94 template< typename T > 95 void threadpool< T >::run() //工作线程真正工作逻辑:从任务队列领取任务T并执行任务T,消费者 96 { 97 while ( ! m_stop ) 98 { 99 m_queuestat.wait();//信号量P操作,申请信号量获取任务T 100 m_queuelocker.lock();//对工作队列操作前加锁 101 if ( m_workqueue.empty() ) 102 { 103 m_queuelocker.unlock();//任务队列空无法消费 104 continue; 105 } 106 T* request = m_workqueue.front();//获取任务T 107 m_workqueue.pop_front(); 108 m_queuelocker.unlock(); 109 if ( ! request ) 110 { 111 continue; 112 } 113 request->process();//执行任务T的相应逻辑,任务T中必须有process接口 114 } 115 } 116 117 #endif
#ifndef HTTPCONNECTION_H #define HTTPCONNECTION_H #include <unistd.h> #include <signal.h> #include <sys/types.h> #include <sys/epoll.h> #include <fcntl.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> #include <assert.h> #include <sys/stat.h> #include <string.h> #include <pthread.h> #include <stdio.h> #include <stdlib.h> #include <sys/mman.h> #include <stdarg.h> #include <errno.h> #include "locker.h" class http_conn { public: static const int FILENAME_LEN = 200;//文件名最大长度,文件是HTTP请求的资源页文件 static const int READ_BUFFER_SIZE = 2048;//读缓冲区,用于读取HTTP请求 static const int WRITE_BUFFER_SIZE = 1024;//写缓冲区,用于HTTP回答 enum METHOD { GET = 0, POST, HEAD, PUT, DELETE, TRACE, OPTIONS, CONNECT, PATCH };//HTTP请求方法,本程序只定义了GET逻辑 enum CHECK_STATE { CHECK_STATE_REQUESTLINE = 0, CHECK_STATE_HEADER, CHECK_STATE_CONTENT };//HTTP请求状态:正在解析请求行、正在解析头部、解析中 enum HTTP_CODE { NO_REQUEST, GET_REQUEST, BAD_REQUEST, NO_RESOURCE, FORBIDDEN_REQUEST, FILE_REQUEST, INTERNAL_ERROR, CLOSED_CONNECTION };//HTTP请求结果:未完整的请求(客户端仍需要提交请求)、完整的请求、错误请求...只用了前三个 enum LINE_STATUS { LINE_OK = 0, LINE_BAD, LINE_OPEN };//HTTP每行解析状态:改行解析完毕、错误的行、正在解析行 public: http_conn(){} ~http_conn(){} public: void init( int sockfd, const sockaddr_in& addr );//初始化新的HTTP连接 void close_conn( bool real_close = true ); void process();//处理客户请求,这是HTTP请求的入口函数,与在线程池中调用!!! bool read();//读取客户发送来的数据(HTTP请求) bool write();//将请求结果返回给客户端 private: void init();//初始化连接,用于内部调用 HTTP_CODE process_read();//解析HTTP请求,内部调用parse_系列函数 bool process_write( HTTP_CODE ret );//填充HTTP应答,通常是将客户请求的资源页发送给客户,内部调用add_系列函数 HTTP_CODE parse_request_line( char* text );//解析HTTP请求的请求行 HTTP_CODE parse_headers( char* text );//解析HTTP头部数据 HTTP_CODE parse_content( char* text );//获取解析结果 HTTP_CODE do_request();//处理HTTP连接:内部调用process_read(),process_write() char* get_line() { return m_read_buf + m_start_line; }//获取HTTP请求数据中的一行数据 LINE_STATUS parse_line();//解析行内部调用parse_request_line和parse_headers //下面的函数被process_write填充HTTP应答 void unmap();//解除内存映射,这里内存映射是指将客户请求的资源页文件映射通过mmap映射到内存 bool add_response( const char* format, ... ); bool add_content( const char* content ); bool add_status_line( int status, const char* title ); bool add_headers( int content_length ); bool add_content_length( int content_length ); bool add_linger(); bool add_blank_line(); public: static int m_epollfd;//所有socket上的事件都注册到一个epoll事件表中所以用static static int m_user_count;//用户数量 private: int m_sockfd;//HTTP连接对应的客户在服务端的描述符m_sockfd和地址m_address sockaddr_in m_address; char m_read_buf[ READ_BUFFER_SIZE ];//读缓冲区,读取HTTP请求 int m_read_idx;//已读入的客户数据最后一个字节的下一个位置,即未读数据的第一个位置 int m_checked_idx;//当前已经解析的字节(HTTP请求需要逐个解析) int m_start_line;//当前解析行的起始位置 char m_write_buf[ WRITE_BUFFER_SIZE ];//写缓冲区 int m_write_idx;//写缓冲区待发送的数据 CHECK_STATE m_check_state;//HTTP解析的状态:请求行解析、头部解析 METHOD m_method;//HTTP请求方法,只实现了GET char m_real_file[ FILENAME_LEN ];//HTTP请求的资源页对应的文件名称,和服务端的路径拼接就形成了资源页的路径 char* m_url;//请求的具体资源页名称,如:www.baidu.com/index.html char* m_version;//HTTP协议版本号,一般是:HTTP/1.1 char* m_host;//主机名,客户端要在HTTP请求中的目的主机名 int m_content_length;//HTTP消息体的长度,简单的GET请求这个为空 bool m_linger;//HTTP请求是否保持连接 char* m_file_address;//资源页文件内存映射后的地址 struct stat m_file_stat;//资源页文件的状态,stat文件结构体 struct iovec m_iv[2];//调用writev集中写函数需要m_iv_count表示被写内存块的数量,iovec结构体存放了一段内存的起始位置和长度, int m_iv_count;//m_iv_count是指iovec结构体数组的长度即多少个内存块 }; #endif
1 #include "http_conn.h" 2 3 const char* ok_200_title = "OK"; 4 const char* error_400_title = "Bad Request"; 5 const char* error_400_form = "Your request has bad syntax or is inherently impossible to satisfy. "; 6 const char* error_403_title = "Forbidden"; 7 const char* error_403_form = "You do not have permission to get file from this server. "; 8 const char* error_404_title = "Not Found"; 9 const char* error_404_form = "The requested file was not found on this server. "; 10 const char* error_500_title = "Internal Error"; 11 const char* error_500_form = "There was an unusual problem serving the requested file. "; 12 const char* doc_root = "/var/www/html";//服务端资源页的路径,将其和HTTP请求中解析的m_url拼接形成资源页的位置 13 14 int setnonblocking( int fd )//将fd设置为非阻塞 15 { 16 int old_option = fcntl( fd, F_GETFL ); 17 int new_option = old_option | O_NONBLOCK; 18 fcntl( fd, F_SETFL, new_option ); 19 return old_option; 20 } 21 22 void addfd( int epollfd, int fd, bool one_shot )//将fd添加到事件表epollfd 23 { 24 epoll_event event; 25 event.data.fd = fd; 26 event.events = EPOLLIN | EPOLLET | EPOLLRDHUP; 27 if( one_shot ) 28 { 29 event.events |= EPOLLONESHOT; 30 } 31 epoll_ctl( epollfd, EPOLL_CTL_ADD, fd, &event ); 32 setnonblocking( fd ); 33 } 34 35 void removefd( int epollfd, int fd )//将fd从事件表epollfd中移除 36 { 37 epoll_ctl( epollfd, EPOLL_CTL_DEL, fd, 0 ); 38 close( fd ); 39 } 40 41 void modfd( int epollfd, int fd, int ev )//EPOLLONESHOT需要重置事件后事件才能进行下次侦听 42 { 43 epoll_event event; 44 event.data.fd = fd; 45 event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP; 46 epoll_ctl( epollfd, EPOLL_CTL_MOD, fd, &event ); 47 } 48 49 int http_conn::m_user_count = 0;//连接数 50 int http_conn::m_epollfd = -1;//事件表,注意是static故所有http_con类对象共享一个事件表 51 52 void http_conn::close_conn( bool real_close )//关闭连接,从事件表中移除描述符 53 if( real_close && ( m_sockfd != -1 ) ) 54 { 55 //modfd( m_epollfd, m_sockfd, EPOLLIN ); 56 removefd( m_epollfd, m_sockfd ); 57 m_sockfd = -1; 58 m_user_count--; 59 } 60 } 61 62 void http_conn::init( int sockfd, const sockaddr_in& addr )//初始化连接 63 { 64 m_sockfd = sockfd;//sockfd是http连接对应的描述符用于接收http请求和http回答 65 m_address = addr;//客户端地址 66 int error = 0; 67 socklen_t len = sizeof( error ); 68 getsockopt( m_sockfd, SOL_SOCKET, SO_ERROR, &error, &len ); 69 int reuse = 1; 70 setsockopt( m_sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof( reuse ) );//获取描述符状态,可以在调试时用 71 addfd( m_epollfd, sockfd, true ); 72 m_user_count++;//多了一个http用户 73 74 init();//调用重载函数 75 } 76 77 void http_conn::init()//重载init函数进行些连接前的初始化操作 78 { 79 m_check_state = CHECK_STATE_REQUESTLINE; 80 m_linger = false; 81 82 m_method = GET; 83 m_url = 0; 84 m_version = 0; 85 m_content_length = 0; 86 m_host = 0; 87 m_start_line = 0; 88 m_checked_idx = 0; 89 m_read_idx = 0; 90 m_write_idx = 0; 91 memset( m_read_buf, '�', READ_BUFFER_SIZE ); 92 memset( m_write_buf, '�', WRITE_BUFFER_SIZE ); 93 memset( m_real_file, '�', FILENAME_LEN ); 94 } 95 96 /*从状态机,用于解析出一行内容*/ 97 http_conn::LINE_STATUS http_conn::parse_line() 98 { 99 char temp; 100 //checked_index指向buffer(应用程序读缓冲区)中当前正在分析的字节,read_index指向buffer中客户数据尾部的下一个字节; 101 //buffer中的第0 ~ checked_index字节都已分析完毕, 第checked_index ~ (read_index - 1)字节由下面的循环挨个分析 102 for ( ; m_checked_idx < m_read_idx; ++m_checked_idx ) 103 { 104 //获得当前要分析的字节; 105 temp = m_read_buf[ m_checked_idx ]; 106 //如果是“ ”,即回车符号,说明可能读取到一个完整的行 107 if ( temp == ' ' ) 108 { 109 //如果 恰巧是目前buffer中最后一个已经被读入的客户数据,那么这次分析没有读取到完整的行, 110 //返回LINE_OPEN表示还需要继续读取客户数据来进一步分析 111 if ( ( m_checked_idx + 1 ) == m_read_idx ) 112 { 113 return LINE_OPEN; 114 } 115 //如果下一个字符是 ,说明读到一个完整的行 116 else if ( m_read_buf[ m_checked_idx + 1 ] == ' ' ) 117 { 118 m_read_buf[ m_checked_idx++ ] = '�'; 119 m_read_buf[ m_checked_idx++ ] = '�'; 120 return LINE_OK; 121 } 122 //否则,说明存在语法问题 123 return LINE_BAD; 124 } 125 //如果当前字符是 ,说明也可能读到一个完整的行 126 //not necessary 127 else if( temp == ' ' ) 128 { 129 if( ( m_checked_idx > 1 ) && ( m_read_buf[ m_checked_idx - 1 ] == ' ' ) ) 130 { 131 m_read_buf[ m_checked_idx-1 ] = '�'; 132 m_read_buf[ m_checked_idx++ ] = '�'; 133 return LINE_OK; 134 } 135 return LINE_BAD; 136 } 137 } 138 //如果所有内容分析完毕都没有遇到 字符,则返回LINE_OPEN,表示还需要继续读取客户数据才能进一步分析 139 return LINE_OPEN; 140 } 141 142 //循环读取客户数据,直到无数据可读或者对方关闭连接 143 bool http_conn::read() 144 { 145 if( m_read_idx >= READ_BUFFER_SIZE ) 146 { 147 return false; 148 } 149 150 int bytes_read = 0; 151 while( true ) 152 { 153 bytes_read = recv( m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0 ); 154 if ( bytes_read == -1 ) 155 { 156 if( errno == EAGAIN || errno == EWOULDBLOCK ) 157 { 158 break; 159 } 160 return false; 161 } 162 else if ( bytes_read == 0 ) 163 { 164 return false; 165 } 166 167 m_read_idx += bytes_read; 168 } 169 return true; 170 } 171 172 173 http_conn::HTTP_CODE http_conn::parse_request_line( char* text ) 174 { 175 //strpbrk()函数检索两个字符串中首个相同字符的位置,其原型为: 176 // char *strpbrk( char *s1, char *s2) 177 m_url = strpbrk( text, " " ); 178 179 //请求行中如果没有 ,则该HTTP请求有问题 180 if ( ! m_url ) 181 { 182 return BAD_REQUEST; 183 } 184 185 *m_url++ = '�'; 186 187 char* method = text; 188 //定义函数:int strcasecmp (const char *s1, const char *s2); 189 //函数说明:strcasecmp()用来比较参数s1 和s2 字符串,比较时会自动忽略大小写的差异。 190 //返回值:若参数s1 和s2 字符串相同则返回0。s1 长度大于s2 长度则返回大于0 的值,s1 长度若小于s2 长度则返回小于0 的值。 191 if ( strcasecmp( method, "GET" ) == 0 ) 192 { 193 m_method = GET; 194 } 195 else 196 { 197 return BAD_REQUEST; 198 } 199 //strspn() 函数用来计算字符串 str 中连续有几个字符都属于字符串 accept,其原型为: 200 //size_t strspn(const char *str, const char * accept); 201 m_url += strspn( m_url, " " ); 202 m_version = strpbrk( m_url, " " ); 203 if ( ! m_version ) 204 { 205 return BAD_REQUEST; 206 } 207 *m_version++ = '�'; 208 m_version += strspn( m_version, " " ); 209 if ( strcasecmp( m_version, "HTTP/1.1" ) != 0 ) 210 { 211 return BAD_REQUEST; 212 } 213 214 if ( strncasecmp( m_url, "http://", 7 ) == 0 ) 215 { 216 m_url += 7; 217 //strchr() 用来查找某字符在字符串中首次出现的位置,其原型为: 218 //char * strchr (const char *str, int c) 219 m_url = strchr( m_url, '/' ); 220 } 221 222 if ( ! m_url || m_url[ 0 ] != '/' ) 223 { 224 return BAD_REQUEST; 225 } 226 //HTTP请求行处理完毕,状态转移到头部字段的分析 227 m_check_state = CHECK_STATE_HEADER; 228 return NO_REQUEST; 229 } 230 231 /*解析http请求的一个头部信息*/ 232 http_conn::HTTP_CODE http_conn::parse_headers( char* text ) 233 { //空行,头部字段解析完毕 234 if( text[ 0 ] == '�' ) 235 { 236 if ( m_method == HEAD ) 237 { 238 return GET_REQUEST; 239 } 240 //如果HTTP请求有消息体,则还需要读取m_content_length字节的消息体,从状态机转移到CHECK_STATE_CONTENT状态 241 if ( m_content_length != 0 ) 242 { 243 m_check_state = CHECK_STATE_CONTENT; 244 return NO_REQUEST; 245 } 246 //否则,说明得到了一个完整的HTTP请求 247 return GET_REQUEST; 248 } 249 //处理connection头部字段 250 else if ( strncasecmp( text, "Connection:", 11 ) == 0 ) 251 { 252 text += 11; 253 text += strspn( text, " " ); 254 if ( strcasecmp( text, "keep-alive" ) == 0 ) 255 { 256 m_linger = true; 257 } 258 } 259 //处理Content_length头部字段 260 else if ( strncasecmp( text, "Content-Length:", 15 ) == 0 ) 261 { 262 text += 15; 263 text += strspn( text, " " ); 264 m_content_length = atol( text ); 265 } 266 //处理host头部字段 267 else if ( strncasecmp( text, "Host:", 5 ) == 0 ) 268 { 269 text += 5; 270 text += strspn( text, " " ); 271 m_host = text; 272 } 273 else 274 { 275 printf( "oop! unknow header %s ", text ); 276 } 277 278 return NO_REQUEST; 279 280 } 281 //消息体不解析,判断一下是否完整读入 282 http_conn::HTTP_CODE http_conn::parse_content( char* text ) 283 { 284 if ( m_read_idx >= ( m_content_length + m_checked_idx ) ) 285 { 286 text[ m_content_length ] = '�'; 287 return GET_REQUEST; 288 } 289 290 return NO_REQUEST; 291 } 292 293 http_conn::HTTP_CODE http_conn::process_read() 294 { 295 LINE_STATUS line_status = LINE_OK; 296 HTTP_CODE ret = NO_REQUEST; 297 char* text = 0; 298 299 while ( ( ( m_check_state == CHECK_STATE_CONTENT ) && ( line_status == LINE_OK ) ) 300 || ( ( line_status = parse_line() ) == LINE_OK ) ) 301 { 302 text = get_line(); 303 m_start_line = m_checked_idx; 304 printf( "got 1 http line: %s ", text ); 305 306 switch ( m_check_state ) 307 { 308 case CHECK_STATE_REQUESTLINE: 309 { 310 ret = parse_request_line( text ); 311 if ( ret == BAD_REQUEST ) 312 { 313 return BAD_REQUEST; 314 } 315 break; 316 } 317 case CHECK_STATE_HEADER: 318 { 319 ret = parse_headers( text ); 320 if ( ret == BAD_REQUEST ) 321 { 322 return BAD_REQUEST; 323 } 324 else if ( ret == GET_REQUEST ) 325 { 326 return do_request(); 327 } 328 break; 329 } 330 case CHECK_STATE_CONTENT: 331 { 332 ret = parse_content( text ); 333 if ( ret == GET_REQUEST ) 334 { 335 return do_request(); 336 } 337 line_status = LINE_OPEN; 338 break; 339 } 340 default: 341 { 342 return INTERNAL_ERROR; 343 } 344 } 345 } 346 347 return NO_REQUEST; 348 } 349 350 http_conn::HTTP_CODE http_conn::do_request()//用于获取资源页文件的状态 351 { 352 strcpy( m_real_file, doc_root ); 353 int len = strlen( doc_root ); 354 strncpy( m_real_file + len, m_url, FILENAME_LEN - len - 1 ); 355 if ( stat( m_real_file, &m_file_stat ) < 0 ) 356 { 357 return NO_RESOURCE;//若资源页不存在则HTTP解析结果为404 358 } 359 360 if ( ! ( m_file_stat.st_mode & S_IROTH ) ) 361 { 362 return FORBIDDEN_REQUEST;//资源没有权限获取 363 } 364 365 if ( S_ISDIR( m_file_stat.st_mode ) ) 366 { 367 return BAD_REQUEST;//请求有错 368 } 369 370 int fd = open( m_real_file, O_RDONLY ); 371 m_file_address = ( char* )mmap( 0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0 );//将资源页文件映射到内存 372 close( fd ); 373 return FILE_REQUEST;//资源页请求成功 374 } 375 376 void http_conn::unmap()//解除资源页文件映射的内存 377 { 378 if( m_file_address ) 379 { 380 munmap( m_file_address, m_file_stat.st_size );//解除映射 381 m_file_address = 0; 382 } 383 } 384 385 bool http_conn::write()//将资源页文件发送给客户端 386 { 387 int temp = 0; 388 int bytes_have_send = 0; 389 int bytes_to_send = m_write_idx; 390 if ( bytes_to_send == 0 ) 391 { 392 modfd( m_epollfd, m_sockfd, EPOLLIN );//EPOLLONESHOT事件每次需要重置事件 393 init(); 394 return true; 395 } 396 397 while( 1 )// 398 { 399 temp = writev( m_sockfd, m_iv, m_iv_count );//集中写,m_sockfd是http连接对应的描述符,m_iv是iovec结构体数组表示内存块地址,m_iv_count是数组的长度即多少个内存块将一次集中写到m_sockfd 400 if ( temp <= -1 )//集中写失败 401 { 402 if( errno == EAGAIN ) 403 { 404 modfd( m_epollfd, m_sockfd, EPOLLOUT );//重置EPOLLONESHOT事件,注册可写事件表示若m_sockfd没有写失败则关闭连接 405 return true; 406 } 407 unmap();//解除内存映射 408 return false; 409 } 410 411 bytes_to_send -= temp;//待发送数据 412 bytes_have_send += temp;//已发送数据 413 if ( bytes_to_send <= bytes_have_send ) 414 { 415 unmap();//该资源页已经发送完毕该解除映射 416 if( m_linger )//若要保持该http连接 417 { 418 init();//初始化http连接 419 modfd( m_epollfd, m_sockfd, EPOLLIN ); 420 return true; 421 } 422 else 423 { 424 modfd( m_epollfd, m_sockfd, EPOLLIN ); 425 return false; 426 } 427 } 428 } 429 } 430 431 bool http_conn::add_response( const char* format, ... )//HTTP应答主要是将应答数据添加到写缓冲区m_write_buf 432 { 433 if( m_write_idx >= WRITE_BUFFER_SIZE ) 434 { 435 return false; 436 } 437 va_list arg_list; 438 va_start( arg_list, format ); 439 int len = vsnprintf( m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list );//将fromat内容输出到m_write_buf 440 if( len >= ( WRITE_BUFFER_SIZE - 1 - m_write_idx ) ) 441 { 442 return false; 443 } 444 m_write_idx += len; 445 va_end( arg_list ); 446 return true; 447 } 448 449 bool http_conn::add_status_line( int status, const char* title ) 450 { 451 return add_response( "%s %d %s ", "HTTP/1.1", status, title ); 452 } 453 454 bool http_conn::add_headers( int content_len ) 455 { 456 add_content_length( content_len ); 457 add_linger(); 458 add_blank_line(); 459 } 460 461 bool http_conn::add_content_length( int content_len ) 462 { 463 return add_response( "Content-Length: %d ", content_len ); 464 } 465 466 bool http_conn::add_linger() 467 { 468 return add_response( "Connection: %s ", ( m_linger == true ) ? "keep-alive" : "close" ); 469 } 470 471 bool http_conn::add_blank_line() 472 { 473 return add_response( "%s", " " ); 474 } 475 476 bool http_conn::add_content( const char* content ) 477 { 478 return add_response( "%s", content ); 479 } 480 481 bool http_conn::process_write( HTTP_CODE ret ) 482 { 483 switch ( ret ) 484 { 485 case INTERNAL_ERROR: 486 { 487 add_status_line( 500, error_500_title ); 488 add_headers( strlen( error_500_form ) ); 489 if ( ! add_content( error_500_form ) ) 490 { 491 return false; 492 } 493 break; 494 } 495 case BAD_REQUEST: 496 { 497 add_status_line( 400, error_400_title ); 498 add_headers( strlen( error_400_form ) ); 499 if ( ! add_content( error_400_form ) ) 500 { 501 return false; 502 } 503 break; 504 } 505 case NO_RESOURCE: 506 { 507 add_status_line( 404, error_404_title ); 508 add_headers( strlen( error_404_form ) ); 509 if ( ! add_content( error_404_form ) ) 510 { 511 return false; 512 } 513 break; 514 } 515 case FORBIDDEN_REQUEST: 516 { 517 add_status_line( 403, error_403_title ); 518 add_headers( strlen( error_403_form ) ); 519 if ( ! add_content( error_403_form ) ) 520 { 521 return false; 522 } 523 break; 524 } 525 case FILE_REQUEST: 526 { 527 add_status_line( 200, ok_200_title ); 528 if ( m_file_stat.st_size != 0 ) 529 { 530 add_headers( m_file_stat.st_size ); 531 m_iv[ 0 ].iov_base = m_write_buf; 532 m_iv[ 0 ].iov_len = m_write_idx; 533 m_iv[ 1 ].iov_base = m_file_address; 534 m_iv[ 1 ].iov_len = m_file_stat.st_size; 535 m_iv_count = 2; 536 return true; 537 } 538 else 539 { 540 const char* ok_string = "<html><body></body></html>"; 541 add_headers( strlen( ok_string ) ); 542 if ( ! add_content( ok_string ) ) 543 { 544 return false; 545 } 546 } 547 } 548 default: 549 { 550 return false; 551 } 552 } 553 554 m_iv[ 0 ].iov_base = m_write_buf; 555 m_iv[ 0 ].iov_len = m_write_idx; 556 m_iv_count = 1; 557 return true; 558 } 559 560 void http_conn::process() 561 { 562 HTTP_CODE read_ret = process_read(); 563 if ( read_ret == NO_REQUEST ) 564 { 565 modfd( m_epollfd, m_sockfd, EPOLLIN ); 566 return; 567 } 568 569 bool write_ret = process_write( read_ret ); 570 if ( ! write_ret ) 571 { 572 close_conn(); 573 } 574 575 modfd( m_epollfd, m_sockfd, EPOLLOUT ); 576 }
1 #ifndef LOCKER_H 2 #define LOCKER_H 3 4 #include <exception> 5 #include <pthread.h> 6 #include <semaphore.h> 7 8 class sem 9 { 10 public: 11 sem() 12 { 13 if( sem_init( &m_sem, 0, 0 ) != 0 ) 14 { 15 throw std::exception(); 16 } 17 } 18 ~sem() 19 { 20 sem_destroy( &m_sem ); 21 } 22 bool wait() 23 { 24 return sem_wait( &m_sem ) == 0; 25 } 26 bool post() 27 { 28 return sem_post( &m_sem ) == 0; 29 } 30 31 private: 32 sem_t m_sem; 33 }; 34 35 class locker 36 { 37 public: 38 locker() 39 { 40 if( pthread_mutex_init( &m_mutex, NULL ) != 0 ) 41 { 42 throw std::exception(); 43 } 44 } 45 ~locker() 46 { 47 pthread_mutex_destroy( &m_mutex ); 48 } 49 bool lock() 50 { 51 return pthread_mutex_lock( &m_mutex ) == 0; 52 } 53 bool unlock() 54 { 55 return pthread_mutex_unlock( &m_mutex ) == 0; 56 } 57 58 private: 59 pthread_mutex_t m_mutex; 60 }; 61 62 class cond 63 { 64 public: 65 cond() 66 { 67 if( pthread_mutex_init( &m_mutex, NULL ) != 0 ) 68 { 69 throw std::exception(); 70 } 71 if ( pthread_cond_init( &m_cond, NULL ) != 0 ) 72 { 73 pthread_mutex_destroy( &m_mutex ); 74 throw std::exception(); 75 } 76 } 77 ~cond() 78 { 79 pthread_mutex_destroy( &m_mutex ); 80 pthread_cond_destroy( &m_cond ); 81 } 82 bool wait() 83 { 84 int ret = 0; 85 pthread_mutex_lock( &m_mutex ); 86 ret = pthread_cond_wait( &m_cond, &m_mutex ); 87 pthread_mutex_unlock( &m_mutex ); 88 return ret == 0; 89 } 90 bool signal() 91 { 92 return pthread_cond_signal( &m_cond ) == 0; 93 } 94 95 private: 96 pthread_mutex_t m_mutex; 97 pthread_cond_t m_cond; 98 }; 99 100 #endif
1 #include <sys/socket.h> 2 #include <netinet/in.h> 3 #include <arpa/inet.h> 4 #include <stdio.h> 5 #include <unistd.h> 6 #include <errno.h> 7 #include <string.h> 8 #include <fcntl.h> 9 #include <stdlib.h> 10 #include <cassert> 11 #include <sys/epoll.h> 12 13 #include "locker.h" 14 #include "threadpool.h" 15 #include "http_conn.h" 16 17 #define MAX_FD 65536 18 #define MAX_EVENT_NUMBER 10000 19 20 extern int addfd( int epollfd, int fd, bool one_shot ); 21 extern int removefd( int epollfd, int fd ); 22 23 void addsig( int sig, void( handler )(int), bool restart = true ) 24 { 25 struct sigaction sa; 26 memset( &sa, '�', sizeof( sa ) ); 27 sa.sa_handler = handler; 28 if( restart ) 29 { 30 sa.sa_flags |= SA_RESTART; 31 } 32 sigfillset( &sa.sa_mask ); 33 assert( sigaction( sig, &sa, NULL ) != -1 ); 34 } 35 36 void show_error( int connfd, const char* info ) 37 { 38 printf( "%s", info ); 39 send( connfd, info, strlen( info ), 0 ); 40 close( connfd ); 41 } 42 43 44 int main( int argc, char* argv[] ) 45 { 46 if( argc <= 2 ) 47 { 48 printf( "usage: %s ip_address port_number ", basename( argv[0] ) ); 49 return 1; 50 } 51 const char* ip = argv[1]; 52 int port = atoi( argv[2] ); 53 54 addsig( SIGPIPE, SIG_IGN ); 55 56 //创建线程池 57 threadpool< http_conn >* pool = NULL; 58 try 59 { 60 pool = new threadpool< http_conn >; 61 } 62 catch( ... ) 63 { 64 return 1; 65 } 66 67 //预先为每个客户连接分配一个http_conn对象 68 http_conn* users = new http_conn[ MAX_FD ]; 69 assert( users ); 70 int user_count = 0; 71 72 int listenfd = socket( PF_INET, SOCK_STREAM, 0 ); 73 assert( listenfd >= 0 ); 74 struct linger tmp = { 1, 0 }; 75 setsockopt( listenfd, SOL_SOCKET, SO_LINGER, &tmp, sizeof( tmp ) ); 76 77 int ret = 0; 78 struct sockaddr_in address; 79 bzero( &address, sizeof( address ) ); 80 address.sin_family = AF_INET; 81 inet_pton( AF_INET, ip, &address.sin_addr ); 82 address.sin_port = htons( port ); 83 84 ret = bind( listenfd, ( struct sockaddr* )&address, sizeof( address ) ); 85 assert( ret >= 0 ); 86 87 ret = listen( listenfd, 5 ); 88 assert( ret >= 0 ); 89 90 epoll_event events[ MAX_EVENT_NUMBER ]; 91 int epollfd = epoll_create( 5 ); 92 assert( epollfd != -1 ); 93 addfd( epollfd, listenfd, false ); 94 http_conn::m_epollfd = epollfd; 95 96 while( true ) 97 { 98 int number = epoll_wait( epollfd, events, MAX_EVENT_NUMBER, -1 ); 99 if ( ( number < 0 ) && ( errno != EINTR ) ) 100 { 101 printf( "epoll failure " ); 102 break; 103 } 104 105 for ( int i = 0; i < number; i++ ) 106 { 107 int sockfd = events[i].data.fd; 108 if( sockfd == listenfd ) 109 { 110 struct sockaddr_in client_address; 111 socklen_t client_addrlength = sizeof( client_address ); 112 int connfd = accept( listenfd, ( struct sockaddr* )&client_address, &client_addrlength ); 113 if ( connfd < 0 ) 114 { 115 printf( "errno is: %d ", errno ); 116 continue; 117 } 118 if( http_conn::m_user_count >= MAX_FD ) 119 { 120 show_error( connfd, "Internal server busy" ); 121 continue; 122 } 123 //初始化客户连接 124 users[connfd].init( connfd, client_address ); 125 } 126 else if( events[i].events & ( EPOLLRDHUP | EPOLLHUP | EPOLLERR ) ) 127 { 128 users[sockfd].close_conn(); 129 } 130 else if( events[i].events & EPOLLIN ) 131 { 132 //根据读的结果,觉得将任务加入线程池,还是关闭连接 133 if( users[sockfd].read() ) 134 { 135 pool->append( users + sockfd ); 136 } 137 else 138 { 139 users[sockfd].close_conn(); 140 } 141 } 142 else if( events[i].events & EPOLLOUT ) 143 { 144 //根据写的结果,觉得是否关闭连接 145 if( !users[sockfd].write() ) 146 { 147 users[sockfd].close_conn(); 148 } 149 } 150 else 151 {} 152 } 153 } 154 155 close( epollfd ); 156 close( listenfd ); 157 delete [] users; 158 delete pool; 159 return 0; 160 }
8. 参考资料
[1]. 游双. Linux高性能服务器编程[M]. 机械工业出版社, 2013.
[2]. 如何写一个Web服务器 http://lifeofzjs.com/blog/2015/05/16/how-to-write-a-server/
[3]. 尹圣雨. TCP/IP网络编程[M]. 人民邮电出版社, 2014.
[4]. W.RICHARDSTEVENS, STEPHENA.RAGO. UNIX环境高级编程[M]. 人民邮电出版社, 2014.