
Playbooks 是Ansible 管理配置、部署应用和编排的语言,可以使用Playbooks 来描述你想在远程主机执行的策略或者执行的一组步骤过程等。
如果说Ansible 模块是工作中的工具的话,那么playbooks 就是方案。
Playbooks 采用YAML 语法结构。
9.1 Playbooks 组成
- Target section:定义将要执行playbook 的远程主机组
- Variable section:定义playbook 运行时需要使用的变量
- Task section:定义将要在远程主机上执行的任务列表
- Handler section:定义task 执行完成以后需要调用的任务
9.1.1主机和用户
在playbook 中的每一个play 都可以选择在哪些机器和以什么用户身份完成,hosts 一行可以是一个主机组或者主机也可以是多个,中间以冒号分隔,可以参考前面讲的通配模式;
remote_user表示执行的用户账号,表示以什么用户来登录远程机器并执行任务。
---
-hosts: webservers
remote_user: root
9.1.2每一个任务都可以定义一个用户
---
- hosts: webservers
remote_user: root
tasks:
- name: test connection
ping:
remote_user: yourname
9.1.3在play 中支持sudo
---
- hosts: webservers
remote_user: yourname
sudo: yes
9.1.4在一个任务中支持sudo
---
- hosts: webservers
remote_user: yourname
tasks:
- service: name=nginx state=started
sudo: yes
9.1.5 登陆后sudo 到其他用户执行
---
- hosts: webservers
remote_user: yourname
sudo: yes
sudo_user: postgres
9.2 任务列表
每个任务建议定义一个可读性较强的名字即name,在执行playbook 时会输出,tasks 的声明格式,建议使用”module:options”的格式。
下面以service 模块为例来定义一个任务,service: key=value 参数,请参看模块的详细介绍
tasks:
- name: make sure apache is running
service: name=httpd state=running
command 和shell 模块关注命令或者脚本执行后返回值,如果命令成功执行返回值不是0 的情况下,可以使用以下方法
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand || /bin/true
或者
tasks:
- name: run this command and ignore the result
shell: /usr/bin/somecommand
ignore_errors: True
注:ignore_errors这里的值只要小写后为true或者yes就可以,所以即使是TRue这种也是正确的。
如果在任务中参数过长可以回车使用空格缩进:
---
- hosts: server
tasks:
- name: Copy ansible inventory file to client
copy: src=/etc/ansible/hosts dest=/tmp/hosts
owner=root group=root mode=0644
9.3 变量的使用
1) 如何创建一个有效的变量名
变量名应该由字母、数组和下划线组成,以字母开头
2) 在inventory 中定义变量
3) 在playbook 中定义变量
4) 在角色和文件中包含变量
5) 如何使用变量:Jinja2
Jinja2 是一个被广泛使用的全功能的Python 模板引擎,它有完整的unicode 支持
注释:Ansible 允许在模板中使用循环和条件判断,但是在playbook 只使用纯粹的YAML 语法
6) Jinja2 过滤器
变量可以通过过滤器修改。过滤器与变量用管道符号( | )分割,并且也可以用圆括号传递可选参数。多个过滤器可以链式调用,前一个过滤器的输出会被作为后一个过滤器的输入。
如{{ list | join(', ') }},会把一个列表用逗号连接起来。
下面列举一些在Ansible 使用较多的Filters:
- 格式化数据:
{{ ansible_devices | join('| ') }}
- 过滤器和条件一起使用:
9.4 register
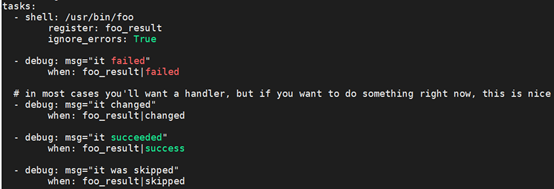
register 关键字的作用是将命令执行的结果保存为变量,结果会因为模块不同而不同,在运行ansible-playbook 时增加-v 参数可以看到results 可能的值;注册变量就如同通过setup 模块获取facts 一样。
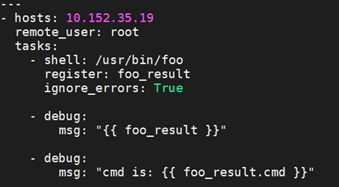
执行结果:

9.5 过滤器
场景1:将获取到的变量的值的所有字母都变成大写。如:
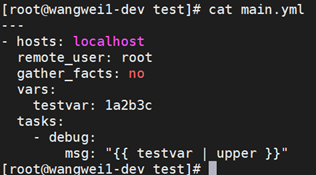
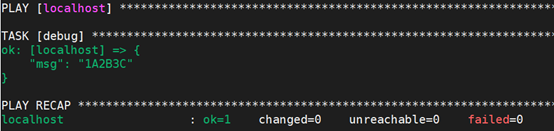
如上例所示,testvar变量的值中包含3个小写字母,在使用debug模块输出这个变量的时候,我们使用了一个管道符,将testvar变量传给了一个名为“upper”的东西,“upper”就是一个过滤器,执行playbook的时候将变量中的小写字母变成了大写。
过滤器是一种能够帮助我们处理数据的工具。其实,ansible中的过滤器功能来自于jinja2模板引擎,我们可以借助jinja2的过滤器功能在ansible中对数据进行各种处理。
当我们想要通过过滤器处理数据的时候,只需要将数据通过管道符传递给对应的过滤器即可。过滤器有很多,有些是jinja2内置的,有些是ansible特有的。除此之外,jinja2还支持自定义过滤器。
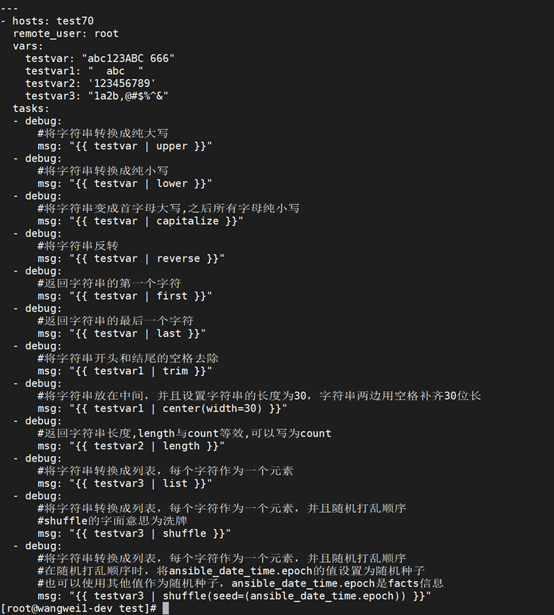
跟字符串操作相关的过滤器,示例:
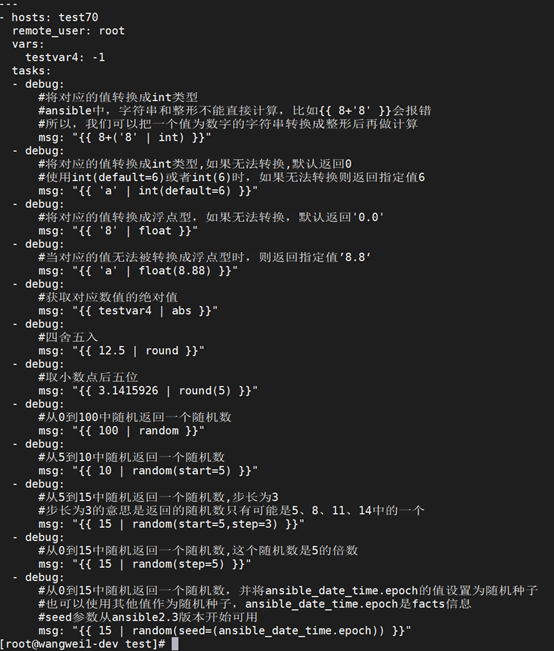
跟数字操作相关的过滤器,示例:
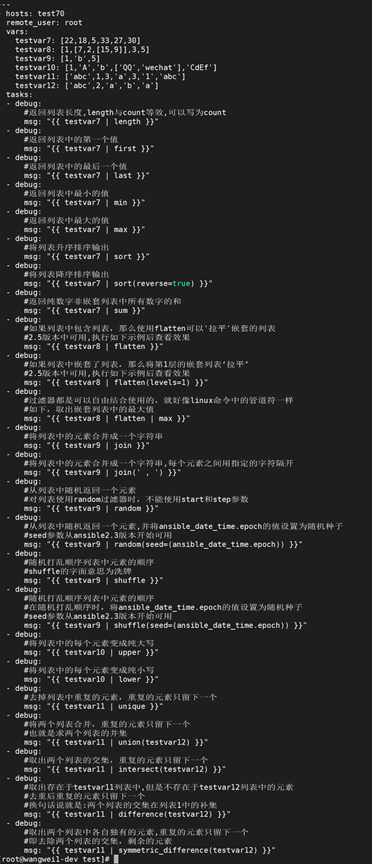
跟列表操作相关的过滤器,示例:
变量未定义相关操作的过滤器,示例:
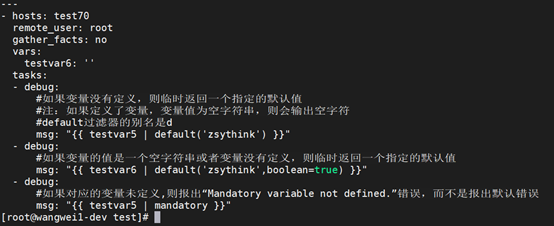
上述的default过滤器,不仅能在变量未定义的时候返回指定的值,还能够让模块的参数变得“可有可无”。
关于“可有可无”,通过以下示例来说明其含义。
场景2,创建几个文件,只有个别文件需要指定权限,可以定义如下:
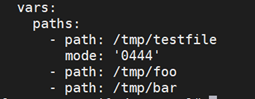
这里只有第一个文件需要指定权限,其余的都是使用系统默认的权限进行创建。在实际工作中,可能需要创建几十个这样的文件,有些需要指定权限,有些不需要,因此一般都会使用条件判断和循环语句来完成,如下:
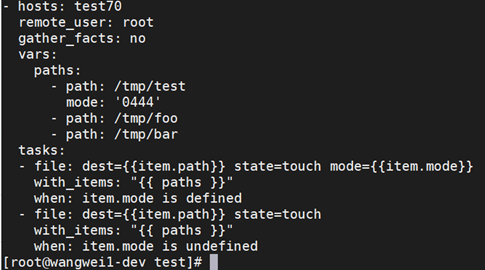
这样的playbook确实可以很好的解决问题,但是一共循环了两遍,因为需要对文件的是否有mode属性进行判断,并根据判断结果调整参数设定。
更好的方法有:
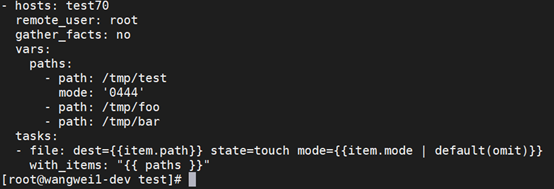
这里并没有对文件是否有mode权限进行判断,而是直接调用了file模块的mode参数,将mode的值设置为了{{item.mode | default(omit)}}。这样表示的含义就是如果item有mode属性,就把file模块的mode参数设置为item的mode属性值,如果item没有mode属性,file模块就省略mode参数。‘omit’的字面意思就是省略,也就是“可有可无”。
9.6 pre_tasks and post_tasks
- pre_tasks: 设置playbook运行之前的tasks,一般用于准备条件或者变量自定义。
- post_tasks: 设置playbook运行之后的tasks
Playbook中各种task的执行顺序:
pre_task > role > tasks > post_task
如果考虑到handler,则执行顺序为:
pre_task > pre_handler > role task > task > role handler > task handler > post task > post handler
如果你想立即执行所有的 handler 命令,在1.2及以后的版本,你可以这样做:
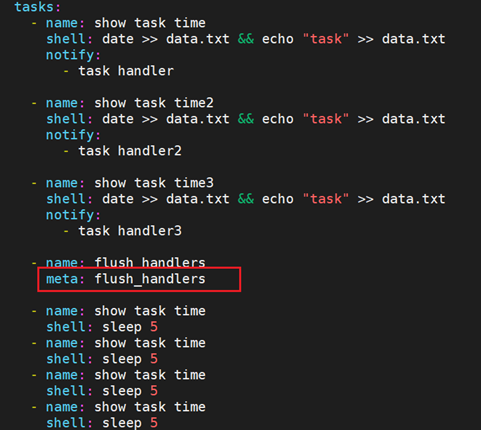
9.7 notify 与 handler
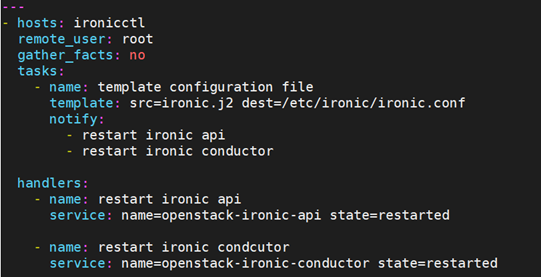
notify指定handler的执行机制:“notify”这个action可用于在每个play的最后被触发,在notify中列出的操作称为handler,仅在所有的变化发生完成后一次性地执行指定操作。在notify中列出的操作称为handle,也即notify中调用handler中定义的操作。
handler:用于当关注的资源发生变化时采取一定的操作。handler是task列表,这些task与前述的task并没有本质上的不同。
另外,handlers 会按照声明(notify)的顺序执行。
例如:修改ironic配置文件后需要重启相应的ironic服务。
9.8 tags
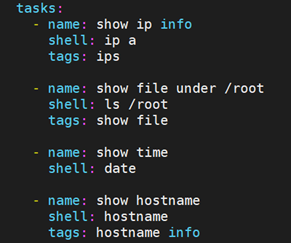
tags:对任务进行“打标签”操作。当任务存在标签后,我们就可以在执行playbook的时候,借助标签,指定执行哪些任务,或者不执行哪些任务。
例如:
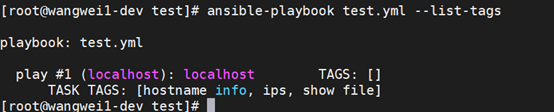
9.8.1 查看所有tag
ansible-playbook <playbook_yaml> --list-tags
9.8.2 指定tag执行任务:
可以指定某个tag:
ansible-playbook test.yml -t/--tags "tag1"
可以指定多个tag(以逗号分隔,可以加空格):
ansible-playbook test.yml -t "tag1, tag2”
9.8.3 指定tag跳过任务
可以使用--skip-tags来跳过某些tag:
可以指定某个tag:
ansible-playbook test.yml --skip-tags "tag1"
可以指定多个tag(以逗号分隔,可以加空格):
ansible-playbook test.yml --skip-tags "tag1, tag2”
9.9 条件判断:when
when相当于shell脚本里的if 判断,when语句就是用来实现这个功能的,它是一个jinja2的语法,但是不需要双大括号,用法很简单。
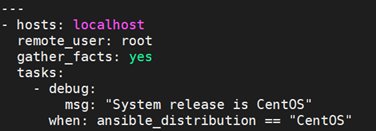
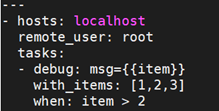
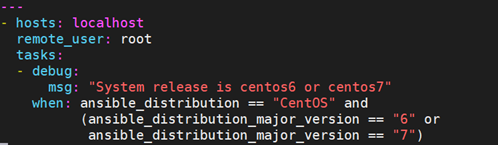
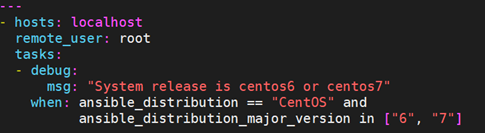
运算比较符有:==、!=、>、<、>=、<=、and、or、not、()、in等
9.9.1 判断目录或文件是否存在:exists
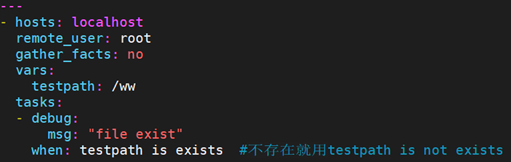
#exists关键字,注意检查的是ansible主机。is not exists表示不存在,也可以用not testpath is exists
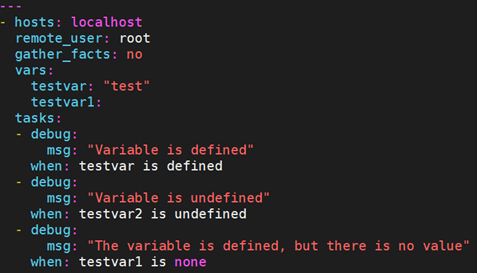
9.9.2 判断变量
- defined:判断变量是否已经定义,已经定义则为真
- undefined:判断变量是否已经定义,未定义则返回真
- none:判断变量是否已经定义,如果变量值已经定义,但是变量值为空,则返回真
9.9.3 判断执行结果
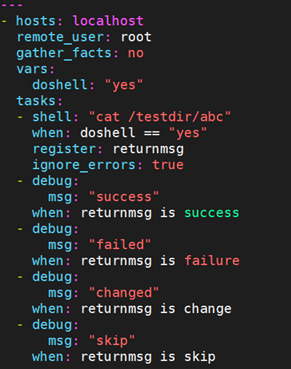
- success或succeeded: 通过任务的返回信息判断任务的执行状态,任务执行成功则返回真
- failure或failed: 通过任务的返回信息判断任务的执行状态,任务执行失败则返回真
- change或changed: 通过任务的返回信息判断任务的执行状态,任务执行状态为changed则返回真
- skip或skipped: 通过任务的返回信息判断任务的执行状态,当任务没有满足条件,而被跳过执行时,则返回真
9.9.4 判断路径
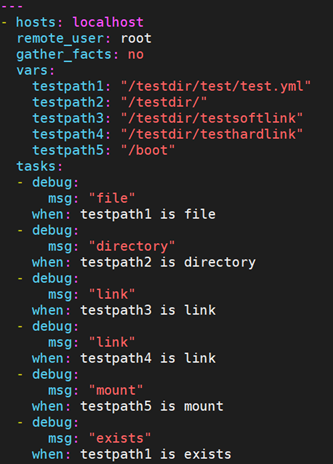
- file: 判断路径是否是一个文件,如果路径是一个文件则为真。
- directory: 判断路径是否是一个目录,如果路径是一个目录则为真
- link: 判断路径是否是一个软连接,如果路径是一个软连接则为真
- mount: 判断路径是否是一个挂载点,如果路径是一个挂载点则为真
- exists: 判断路径是否存在,如果路径存在则为真
注意:某些版本之前可能需要加上“is_”前缀
9.9.5 判断整除
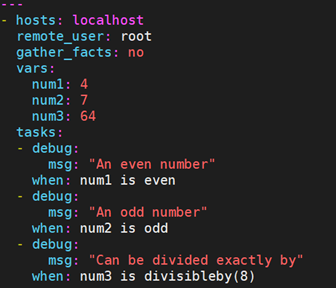
- even: 判断数值是否是偶数,偶数则为真
- odd: 判断数值是否是奇数,奇数则为真
- divisibleby(num): 判断是否可以整除指定的数值,如果除以指定的值以后余数为0,则返回真
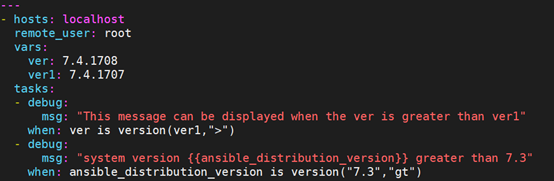
9.5.6 版本号比较
version: 可以用于对比两个版本号的大小,或者与指定的版本号进行对比,语法version('版本号','比较操作符')。2.5版本此test从version_compare 更名为version。
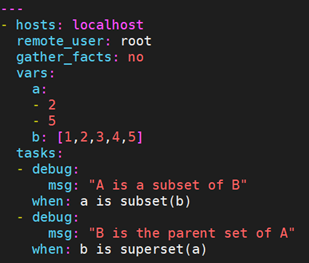
9.5.7 列表比较
- subset: 判断一个list是不是另一个list的子集,是则为真
- siperset: 判断一个list是不是另一个list的父集,是则为真
注:2.5版本之前是issubset和issuperset
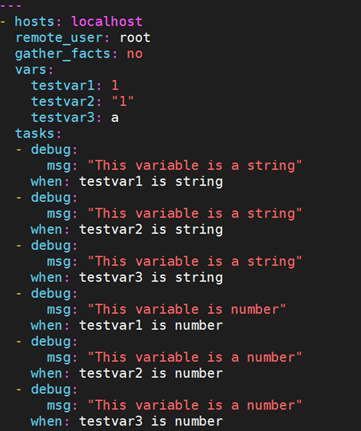
9.5.8 字符串与数字判断
- string: 判断对象是否是一个字符串,是则为真
- number: 判断对象是否是一个数字,是则为真
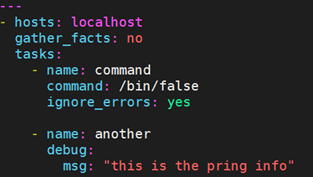
9.5.9 failed_when
先看个例子:
有些时候,我们需要通过返回的字符串来判断是否failed。例如:

也就是说,我们只有在返回结果中出现字符串‘FAILED’,我们才认为我们的task 失败了(因为command 命令即使执行成功,返回值才是我们要判断失败与否的关键)。
9.5.10 changed_when
与failed_when类似。示例:
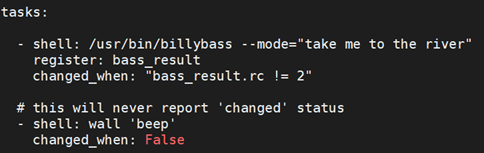
在使用command /shell 模块的时候ansible playbook 会按照自己的判断来决定是否changed了。
有时候我们仅仅是ls 了一下, ansible-playbook 也会认为是changed了,可能这并不是我们想要的,这个时候我们就要用例子中方法来修改task的状态了:
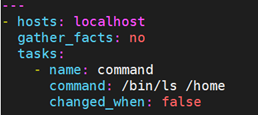
9.10 循环
9.10.1 标准循环
为了保持简洁,重复的任务可以用以下简写的方式:
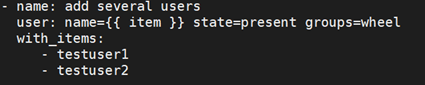
如果你在变量文件中或者 ‘vars’ 区域定义了一组YAML列表,你也可以这样做:
with_items: "{{somelist}}"
以上写法与下面是完全等同的:

使用 ‘with_items’ 用于迭代的条目类型不仅仅支持简单的字符串列表。如果你有一个哈希列表,那么你可以用以下方式来引用子项:

注:如果同时使用 when 和 with items (或其它循环声明), when声明会为每个条目单独执行。
9.10.2嵌套循环
循环也可以嵌套:
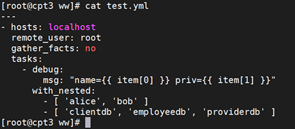
执行一下:
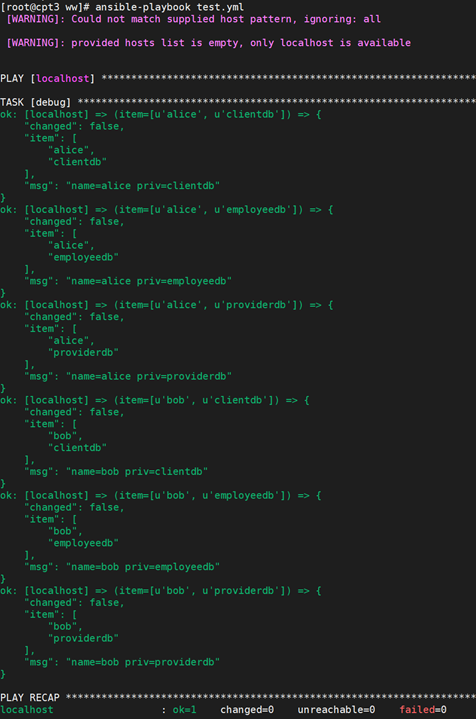
和以上介绍的with items一样,你也可以使用预定义变量:
9.10.3 对哈希表使用循环
哈希表:用于存储Key-Value键值对的集合。
使用with_dict 来循环哈希表中的元素:

9.10.4 对文件列表使用循环
with_fileglob 可以以非递归的方式来模式匹配单个目录中的文件
注:当在role中对 with_fileglob 使用相对路径时, Ansible会把路径映射到`roles/<rolename>/files`目录。
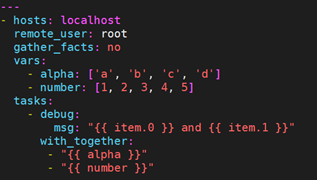
9.10.5 对并行数据集使用循环(不常见)
假设你通过某种方式加载了以下变量数据:
--- alpha: [ 'a', 'b', 'c', 'd' ] numbers: [ 1, 2, 3, 4 ]
如果你想得到’(a, 1)’和’(b, 2)’之类的集合.可以使用with_together:
不足的数据则为空:
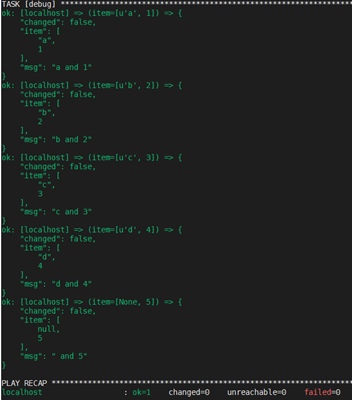
注:这种使用方式不常见。
9.10.6 对子元素使用循环
假设你想对一组用户做一些动作,比如创建这些用户,并且允许它们使用一组SSH key来登录。
如何实现? 先假设你有按以下方式定义的数据,可以通过”vars_files”或”group_vars/all”文件加载:
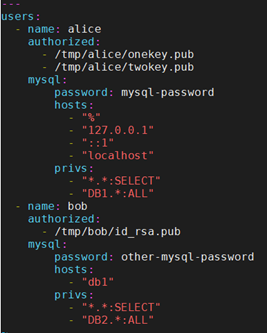
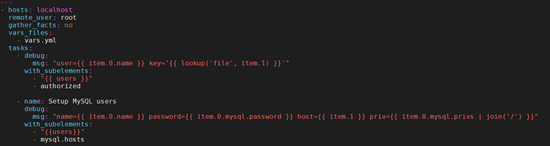
那么可以这样实现:

根据mysql hosts以及预先给定的privs subkey列表,我们也可以在嵌套的subkey中迭代列表:
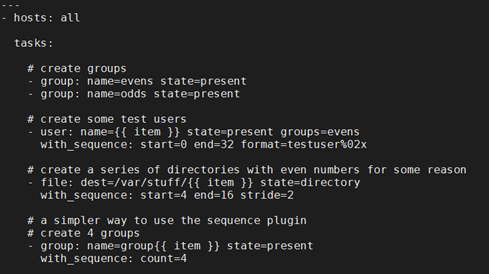
9.10.7 对整数序列使用循环
with_sequence 可以以升序数字顺序生成一组序列。你可以指定起始值、终止值,以及一个可选的步长值。
指定参数时也可以使用key=value这种键值对的方式。如果采用这种方式,format是一个可打印的字符串。
字值可以被指定为10进制,16进制(0x3f8)或者八进制(0600)。负数则不受支持。请看以下示例:
9.10.8 随机选择
random_choice功能可以用来随机获取一些值。它并不是负载均衡器(已经有相关的模块了)。它有时可以用作一个简化版的负载均衡器,比如作为条件判断:
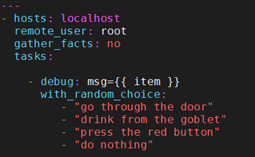
提供的字符串中的其中一个会被随机选中。
9.10.9 Do-Until循环
有时你想重试一个任务直到达到某个条件。比如:

上面的例子递归运行shell模块,直到模块结果中的stdout输出中包含”all systems go”字符串,或者该任务按照10秒的延迟重试超过5次。retries和delay的默认值分别是3和5。
该任务返回最后一个任务返回的结果。单次重试的结果可以使用-vv选项来查看。被注册的变量会有一个新的属性attempts,值为该任务重试的次数。
9.10.10 查找第一个匹配的文件(不常见)
这其实不是一个循环,但和循环很相似,如果你想引用一个文件,而该文件是从一组文件中根据给定条件匹配出来的。这组文件中部分文件名由变量拼接而成。
针对该场景你可以这样做:

该功能还有一个更完整的版本,可以配置搜索路径.请看以下示例:
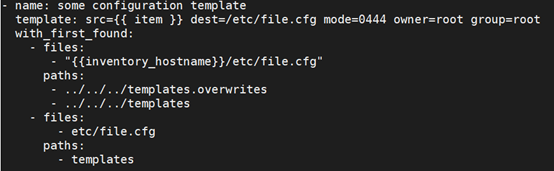
9.10.11 迭代程序的执行结果(不常见)
有时你想执行一个程序,而且按行循环该程序的输出。Ansible提供了一个优雅的方式来实现这一点。但请记住,该功能始终在本地机器上执行,而不是远程机器。
例如,find一堆文件出来,copy走。
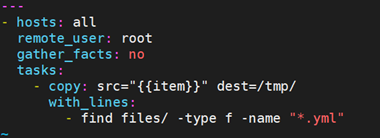
如果你想远程执行命令,那么以上方法则不行。但你可以这样写:
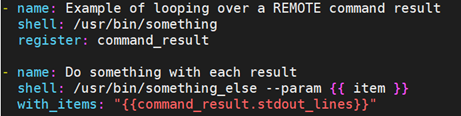
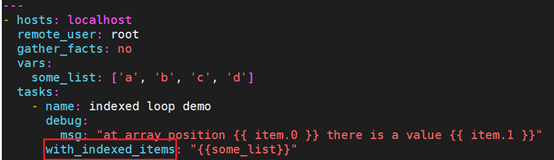
9.10.12 使用索引循环列表(不常见)
如果你想循环一个列表,同时得到一个数字索引来标明你当前处于列表什么位置,那么你可以这样做:
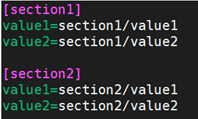
9.10.13 循环配置文件(不常见)
ini插件可以使用正则表达式来获取一组键值对。因此,我们可以遍历该集合。以下是我们使用的ini文件:
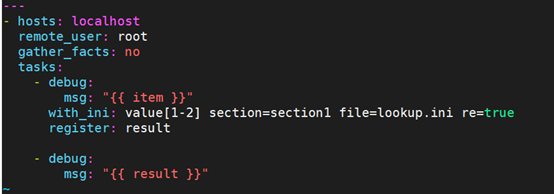
以下是使用 with_ini 的例子:
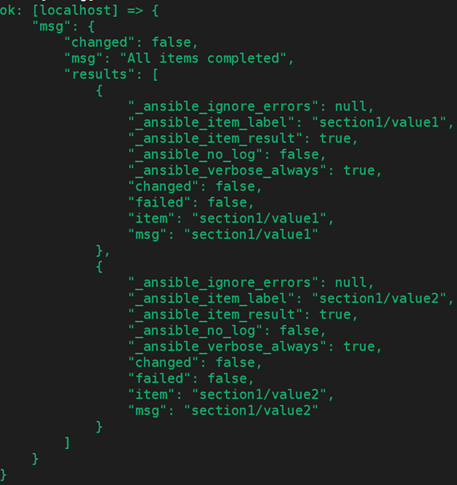
以下是返回的值:
9.10.14 扁平化列表(不常见)
在罕见的情况下,你可能有几组列表,列表中会嵌套列表。而你只是想迭代所有列表中的每个元素,比如有一个非常疯狂的假定的数据结构:
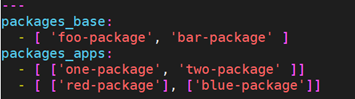
你可以看到列表中的包到处都是。那么如果想安装两个列表中的所有包呢?
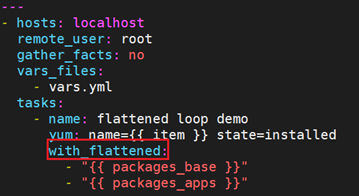
9.10.15 循环中使用注册器
当对处于循环中的某个数据结构使用 register 来注册变量时,结果包含一个 results 属性,这是从模块中得到的所有响应的一个列表。
以下是在 with_items 中使用 register 的示例:
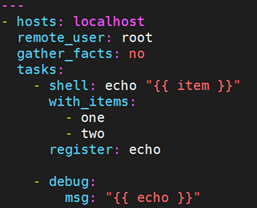
返回的数据结构如下,与非循环结构中使用 register 的返回结果是不同的,非循环结构的返回结果类似下面:
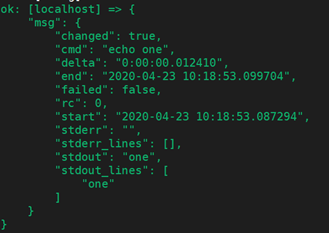
而循环结构的返回结果如:
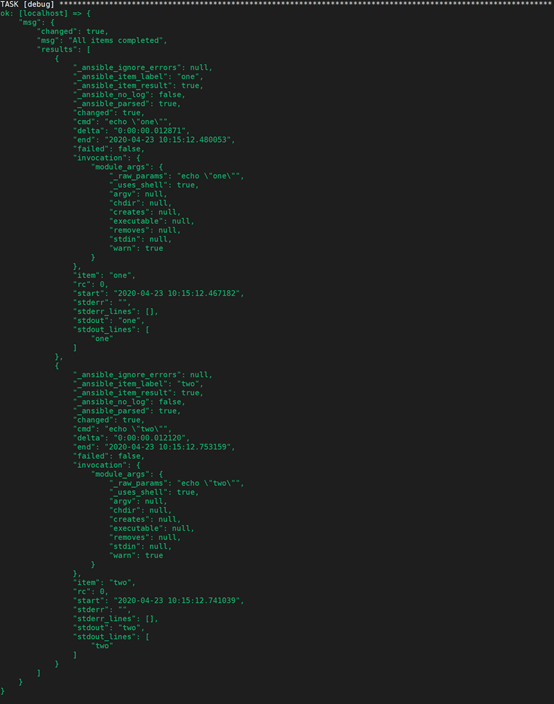
随后的任务可以用以下方式来循环注册变量,用来检查结果值:

9.11 包含
在编程的时候,我们一般都会将重复性的代码提取出来,作为一个逻辑单元,这个逻辑单元通常被称为“函数”或者“方法”。如果需要修改这段逻辑,只需要修改函数本身即可。而且这样还使得程序的可读性更强。
Ansible中也有类似的功能,这种功能被称为包含,通过包含,我们可以在一个playbook中包含另一个文件,以便实现我们想要的效果。
Ansible有两种包含的操作模式:动态和静态。Ansible 2.4引入了include和import的概念。
- 如果您使用import*包含Task(import_playbook,import_tasks等),它将是静态的。
- 如果您使用include*包含Task(include_tasks,include_role等),它将是动态的。
使用include包含Task(用于task文件和Playbook级包括)仍然可用,但现在被认为已被弃用,建议使用 include_tasks和 import_tasks。
9.11.1 include_tasks和import_tasks之间的差异
区别一:
- include_tasks:是动态的,在运行时展开。即在执行play之前才会加载自己变量。when只应用一次, 被include的文件名可以使用变量。
- import_tasks:是静态的,在加载时展开。即在playbooks解析阶段将父task变量和子task变量全部读取并加载。因为是加载时展开的,文件名的变量不能是动态设定的。 when在被import的文件里的每个task,都会重新检查一次。
例:
b.yml
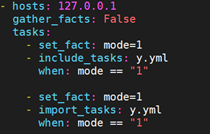
y.yml:
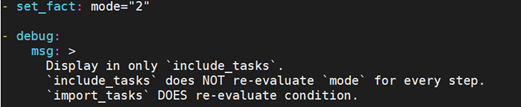
运行:
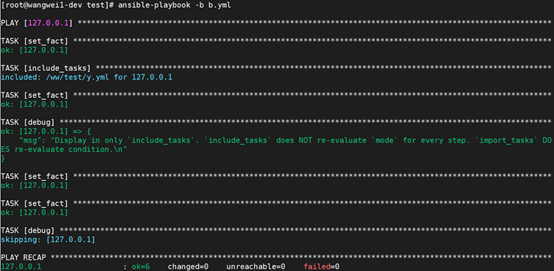
因为 mode被改变之后, include_tasks不会重新evaluate mode, import_tasks会根据变化后的mode值重新evaluate每个task的条件。
区别二:
- include_tasks方法调用的文件名称可以加变量
- import_tasks方法调用的文件名称不可以有变量
对于include_tasks,导入文件时可以指定变量:
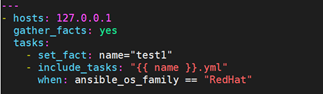
当使用import_tasks方法时,执行报错。ansible也给出了错误原因,当使用static include时,是不能使用变量的:

9.11.2 include_tasks和import_tasks的优缺点
使用include*语句的主要优点是循环。当循环与include*一起使用时,包含的任务或角色将为循环中的每个项目执行一次。
与import*语句相比,使用include*有一些限制:
- 仅存在于动态包含内的标签不会显示在-list-tags输出中。
- 仅存在于动态包含内的任务不会显示在-list-tasks输出中。
- 您不能使用notify来触发来自动态包含内部的处理程序名称。
- 您不能使用--start-at-task开始执行动态包含内的任务。
与include*相比,使用import*也可能有一些限制:
- 如上所述,循环不能用于导入。
- 当使用目标文件或角色名称的变量时,不能使用来自库存源(主机/组变量等)的变量。
总而言之,没有使用with的包含,就使用import,使用了with,那就用include。
9.11.3 import_playbook
如果想引入整个playbook,则需要使用include_playbook模块来代替include。在ansible2.8版本之后,include功能就被删除掉了。
要求:
- 包含一个带有要执行的play列表的文件。
- 带有play列表的文件必须被包含在顶层
- 不能在play中执行该操作。
例如:
main.yml
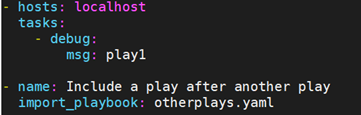
otherplays.yaml

otherplays.yaml中导入stuff.yaml,由于不是在顶层导入,而是在play中导入,所以执行会失败。
9.11.4 include_vars
include_vars模块可以包含JSON或YAML文件中的定义变量,覆盖已定义的主机变量和playbook变量。如:

9.11.5 include_role 与 import_role
后续再讲。
9.12 Roles
上述已经讲过tasks和handlers,那么如何组织playbook才是最好的方式呢?
roles!
roles是基于一个已知的文件结构,去自动加载某些vars_file,tasks以及handlers。基于roles对内容进行分组,使得我们可以容易地与其他用户分享roles。
一个项目的结构如下:
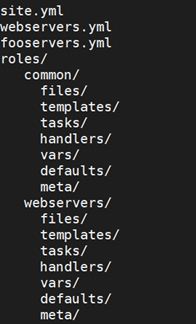
一个 playbook 如下:
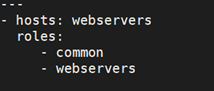
这个 playbook 为一个角色x指定了如下的行为:
- 如果 roles/x/tasks/main.yml 存在, 其中列出的 tasks 将被添加到 play 中
- 如果 roles/x/handlers/main.yml 存在, 其中列出的 handlers 将被添加到 play 中
- 如果 roles/x/vars/main.yml 存在, 其中列出的 variables 将被添加到 play 中
- 如果 roles/x/meta/main.yml 存在, 其中列出的 “角色依赖” 将被添加到 roles 列表中 (1.3 and later)
- 所有 copy tasks 可以引用 roles/x/files/ 中的文件,不需要指明文件的路径。
- 所有 script tasks 可以引用 roles/x/files/ 中的脚本,不需要指明文件的路径。
- 所有 template tasks 可以引用 roles/x/templates/ 中的文件,不需要指明文件的路径。
- 所有 include tasks 可以引用 roles/x/tasks/ 中的文件,不需要指明文件的路径。
如果 roles 目录下有文件不存在,这些文件将被忽略。比如 roles 目录下面缺少了 vars/ 目录,这也没关系。
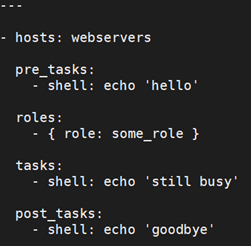
如果你在 playbook 中同时使用 roles 和 tasks,vars_files 或者 handlers,roles 将优先执行。如果想在roles前执行一些task,可以这样:
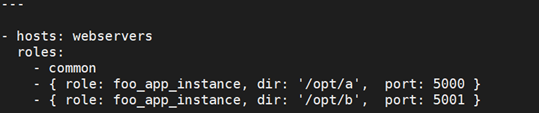
而且,如果你愿意,也可以使用参数化的 roles,这种方式通过添加变量来实现,比如:
当一些事情不需要频繁去做时,你也可以为 roles 设置触发条件,像这样:

它的工作方式是:将条件子句应用到 role 中的每一个 task 上。
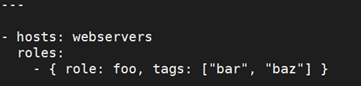
最后,你可能希望给 roles 分配指定的 tags。比如:
9.12.1 roles各目录含义
- tasks目录:角色需要执行的主任务文件放置在此目录中,默认的主任务文件为main.yml,当调用角色时,默认会执行main.yml文件中的任务。也可以将其他需要执行的任务通过include的方式包含在tasks/main.yml文件中。
- handlers目录:当角色需要调用handlers时,默认会在此目录中的main.yml文件中查找对应的handler
- defaults目录:角色会使用到的变量可以写入到此目录中的main.yml文件中,通常defaults/main.yml文件中的变量都用于设置默认值,以便在你没有设置对应变量值时,变量有默认的值可以使用,定义在defaults/main.yml文件中的变量的优先级是最低的。
- vars目录:角色会使用到的变量可以写入到此目录中的main.yml文件中。与defaults/main.yml的区别在于,defaults/main.yml文件中的变量的优先级是最低的,而vars/main.yml文件中的变量的优先级非常高,如果只是想提供一个默认的配置,可以定义在defaults/main.yml,如果想要确保别人在调用角色时,使用的值就是你指定的值,则可以将变量定义在vars/main.yml中,因为定义在vars/main.yml文件中的变量的优先级非常高,所以其值难以覆盖。
- meta目录:如果想要赋予这个角色一些元数据,则可以将元数据写入到meta/main.yml文件中,这些元数据用于描述角色的相关属性,比如作者信息、角色的主要作用等。也可以在meta/main.yml文件中定义这个角色依赖于哪些角色,或者改变角色的默认调用设定。
- templates目录:角色相关的模板可以放置在此目录中。当使用角色相关的模板时,如果没有指定路径,会默认从此目录中查找对应名称模板文件。
- files目录:角色可能会用到的一些其他文件可以放置在此目录中。
注:上述目录并不全是必须的,如果你的角色中没有用到对应这些目录的模块,那么对应的目录就不需要包含。一般情况下,至少要有一个tasks目录。
9.12.2 角色默认变量
角色默认变量允许你为 included roles 或者 dependent roles 设置默认变量。要创建默认变量,只需在 roles 目录下添加 defaults/main.yml 文件。这些变量在所有可用变量中拥有最低优先级,可能被其他地方定义的变量(包括 inventory 中的变量)所覆盖。
9.12.3 role查找
我们可以把单个role的目录写在与入口playbook同级的目录下,也可以放在同级的roles目录下,还可以通过/etc/ansible/ansible.cfg中的roles_path(默认为家目录的.ansible/roles目录)指定。
role查找优先级:同级roles目录 > /etc/ansible/ansible.cfg中的roles_path(默认为家目录的.ansible/roles目录) > 同级目录下
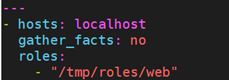
即使role目录不处于上述目录中的任何一个,也可以使用绝对路径的方式,调用相应的角色:
这种写法其实不算正规,标准语法应该这样:
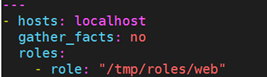
在roles关键字中使用role关键字指定角色对应的绝对路径,可以直接调用角色。即使不使用绝对路径,也可以使用同样的语法指定角色名。如:
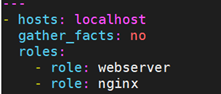
9.12.4 role变量传递
我们可以在调用role的时候传递对应的变量。如:
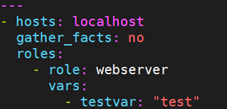
默认变量也可以定义在defaults/main.yml中,不过优先级是最低的。role使用的变量的优先级为:vars/main.yml > 调用role时传递的vars > defaults/main.yml。
还可以写成:
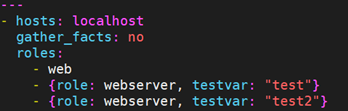
另外,角色中的变量是全局可访问的。例如:
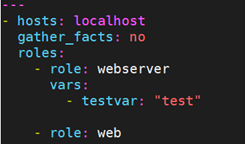
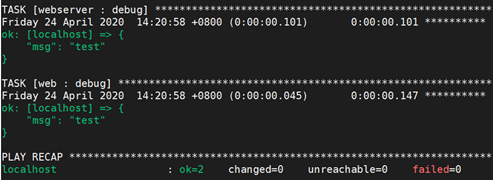
在调用webserver这个角色时传递的变量testvar的值,是可以传递给web这个角色的。在两个角色里面对这个变量进行debug,都可以得到这个值:
也可以为role设置触发条件,如:

最后,还可以给role分配指定的tags。如:
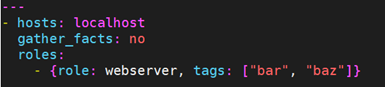
9.12.5 重复调用
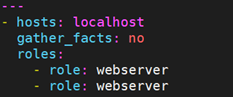
默认情况下,我们无法多次调用同一个角色。也就是说,如下的playbook只会调用一次webserver角色:
执行该playbook,可以发现,webserver中的debug模块只输出了一次:
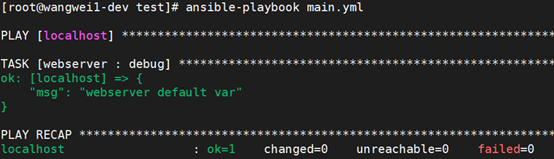
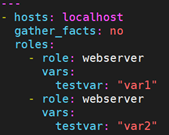
如果想要多次调用同一个角色,有两种方法。如下:
- 方法一:设置角色的allow_duplicates属性,让其支持重复调用
- 方法二:调用角色时,传入的参数值不同
方法一需要为角色设置allow_duplicates属性,该属性需要设置在meta/main.yml中,如:

方法二,当调用角色时需要传入参数,如果传入参数的值不同,也可以连续调用多次。如:
9.12.6 role handler
如果想在角色中使用一些handlers以便进行触发,则可以直接将对应的handlers任务写入到handlers/main.yml文件中,示例:

9.12.7 角色依赖
角色依赖 使你可以自动地将其他 roles 拉取到现在使用的 role 中。角色依赖保存在 roles 目录下的 meta/main.yml 文件中。这个文件应包含一列 roles 和 为之指定的参数。
示例:

“角色依赖” 可以通过绝对路径指定,如同顶级角色的设置:

“角色依赖” 也可以通过源码控制仓库或者 tar 文件指定,使用逗号分隔:路径、一个可选的版本(tag, commit, branch 等等)、一个可选友好角色名(尝试从源码仓库名或者归档文件名中派生出角色名):

“角色依赖” 总是在 role (包含”角色依赖”的role)之前执行,并且是递归地执行。默认情况下,作为 “角色依赖” 被添加的 role 只能被添加一次,如果另一个 role 将一个相同的角色列为 “角色依赖” 的对象,它不会被重复执行。但这种默认的行为可被修改,通过添加 allow_duplicates: yes 到 meta/main.yml 文件中。
比如,一个 role 名为 ‘car’,它可以添加名为 ‘wheel’ 的 role 到它的 “角色依赖” 中:
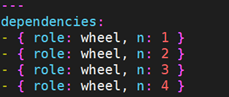
wheel 角色的 meta/main.yml 文件包含如下内容:
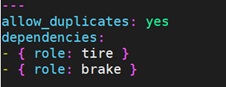
最终的执行顺序是这样的:
tire(n=1)
brake(n=1)
wheel(n=1)
tire(n=2)
brake(n=2)
wheel(n=2)
...
car
9.12.8 在 Roles 中嵌入模块
如果您编写一个定制模块,则可能希望将其作为角色的一部分进行分发。
在角色的tasks和handlers结构旁边,添加一个名为‘library’的目录,然后将定制模块直接包含在其中。
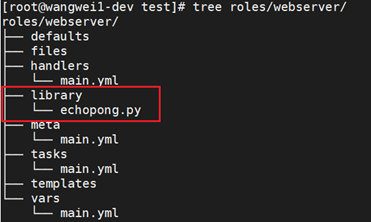
在一个role中定义的模块,可供其他role使用:
9.12.9 include_role与import_role
在后来版本(ansible>=2.4)中,ansible引入了 import_role(静态)和include_role(动态)方法。
---
# playbooks/test.yaml
- hosts: node1
tasks:
- include_role:
name: role_A
vars:
name: maurice
age: 100
- import_role:
name: role_B
比较于 roles 语句,import_role 和 include_role 的优点如下:
- 可以在task之间穿插导入某些role,这点是「roles」没有的特性。
- 更加灵活,可以使用「when」语句等判断是否导入。
关于include_role(动态)和import_role(静态)的区别,可以参考之前的include_tasks和import_tasks。
也正是因为 include_task 是动态导入,当我们给 include_role 导入的role打tag时,实际并不会执行该role的task。
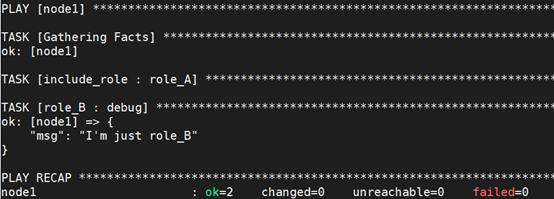
举个例子,当我们使用include导入role_A,使用import导入role_B时:
---
# playbooks/test.yaml
- hosts: node1
tasks:
- include_role:
name: role_A
tags: maurice
- import_role:
name: role_B
tags: maurice
role_A内容如下:
---
# tasks file for role_A
- debug:
msg: "age"
- debug:
msg: "maurice"
执行结果显示,role_A虽然被引用,但里面的task并没有执行:
(End)