一、经典领域模型架构图

领域驱动设计在经典三层架构的基础上做了进一步改良,在用户界面层与业务逻辑层之间引入了新的一层,即应用层(Application Layer)。
同时,一些层次的命名也发生了变化。将业务逻辑层更名为领域层自然是题中应有之义,而将数据访问层更名为基础设施层(Infrastructure Layer),
则突破了之前数据库管理系统的限制,扩大了这个负责封装技术复杂度的基础层次的内涵。
二、核心要素
实体(Entity)、值对象(Value Object)、服务(Service)、聚合(Aggregate)、模块(Package)、工厂(Factory)、资源库(Repository)
===========================================================================
作者:人民邮电出版社
链接:https://www.zhihu.com/question/25089273/answer/969378280
来源:知乎
1. 什么是领域模型
在理解领域模型之前,我们先思考一下软件开发的本质是什么。从本质上来说,软件开发过程就是问题空间到解决方案空间的一个映射转化,如图1所示。
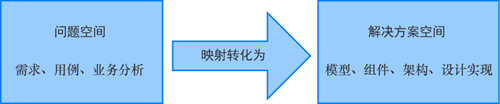
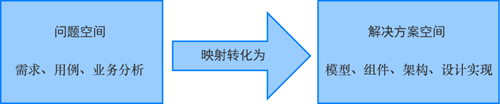
在问题空间中,我们主要是找出某个业务面临的挑战及其相关需求场景用例分析;而在解决方案空间中,则通过具体的技术工具手段来进行设计实现。
就软件系统来说,“问题空间”就是系统要解决的“领域问题”。因此,也可以简单理解为一个领域就对应一个问题空间,是一个特定范围边界内的业务需求的总和。
“领域模型”就是“解决方案空间”,是针对特定领域里的关键事物及其关系的可视化表现,是为了准确定义需要解决问题而构造的抽象模型,是业务功能场景在软件系统里的映射转化,其目标是为软件系统构建统一的认知。
例如,请假系统解决的是人力工时的问题,属于人力资源领域,对口的是HR部门;费用报销系统解决的是员工和公司之间的财务问题,属于财务领域,对口的是财务部门;电商平台解决的是网上购物问题,属于电商领域。可以看出,每个软件系统本质上都解决了特定的问题,属于某一个特定领域,实现了同样的核心业务功能来解决该领域中核心的业务需求。
总结一下,领域模型在软件开发中的主要起到如下作用。
- 帮助分析理解复杂业务领域问题,描述业务中涉及的实体及其相互之间的关系,是需求分析的产物,与问题域相关。
- 是需求分析人员与用户交流的有力工具,是彼此交流的语言。
- 分析如何满足系统功能性需求,指导项目后续的系统设计。
2. 什么是DDD
DDD是Eric Evans在2003年出版的《领域驱动设计:软件核心复杂性应对之道》(Domain-Driven Design: Tackling Complexity in the Heart of Software)一书中提出的具有划时代意义的重要概念,是指通过统一语言、业务抽象、领域划分和领域建模等一系列手段来控制软件复杂度的方法论。
DDD的革命性在于领域驱动设计是面向对象分析的方法论,它可以利用面向对象的特性(封装、多态)有效地化解复杂性,而传统J2EE或Spring+Hibernate等事务性编程模型只关心数据。这些数据对象除了简单的setter/getter方法外,不包含任何业务逻辑,业务逻辑都是以过程式的代码写在Service中。这种方式极易上手,但随着业务的发展,系统也很容易变得混乱复杂。
领域驱动设计关心的是业务中的领域划分(战略设计)和领域建模(战术设计),其开发过程不再以数据模型为起点,而是以领域模型为出发点,研发过程如图2所示。领域模型对应的是业务实体,在程序中主要表现为类、聚合根和值对象,它更加关注业务语义的显性化表达,而不是数据的存储和数据之间的关系。
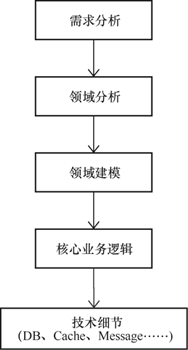
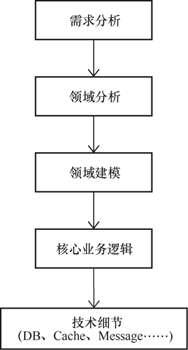 图2 领域驱动研发过程
图2 领域驱动研发过程
3. DDD的优势
3.1 统一语言
统一语言(Ubiquitous Language)的主要思想是让应用能和业务相匹配,这是通过在业务与代码中的技术之间采用共同的语言达成的。业务语言起源于公司的业务侧,业务侧拥有需要实现的概念。业务语言中的术语由公司的的业务侧和技术侧通过协商来定义(意味着业务侧也不能总是选到最好的命名),目标是创造可以被业务、技术和代码自身无歧义使用的共同术语,即统一语言。代码、类、方法、属性和模块的命名必须和统一语言相匹配,必要的时候需要对代码进行重构!
试想,在PRD文档、设计文档、代码以及团队日常交流中,如果有一套领域术语是统一无歧义的,是否会极大地提升沟通和工作效率?在日常工作中,因为概念理解不一致,或者语言表达上的问题,导致沟通效率低,甚至发生误解的情况实在太多了。所以,明确概念、形成统一语言至关重要。
3.2 面向对象
DDD的核心是领域模型,这一方法论可以通俗地理解为先找到业务中的领域模型,以领域模型为中心,驱动项目开发。领域模型的设计精髓在于面向对象分析、对事物的抽象能力,一个领域驱动架构师必然是一个面向对象分析的大师。
DDD鼓励我们接触到需求后第一步就是考虑领域模型,而不是将其切割成数据和行为,然后用数据库实现数据,用服务实现行为,最后造成需求的首尾分离。DDD会让你首先考虑业务语言,而不是数据。DDD强调业务抽象和面向对象编程,而不是过程式业务逻辑实现。重点不同,导致编程世界观不同。
3.3 业务语义显性化
统一语言也好,面向对象也好,最终的目都是为代码的可读性和可维护性服务。统一语言使得我们的核心领域概念可以无损地在代码中呈现,从而提升代码的可理解性。例如,在银行转账的案例中,按照事务脚本的写法来写“透支策略”的业务概念,其含义完全被淹没在代码逻辑中没有突显出来。但是,如果我们使用策略模式将其抽象出来,让业务语义得到显性化的表达,代码的可读性就会提升很多。
面向对象也是让代码尽量体现领域实体和实体之间的关系原貌,所以目的也是业务语义被显性化地表达,显性化的结果是代码更容易被理解和维护,殊途同归,一切都是为了控制复杂度。在软件的世界里,任何的方法论如果最终不能落在“减少代码复杂度”这个焦点上,那么都是有待商榷的。
3.4 分离业务逻辑和技术细节
代码复杂度是由业务复杂度和技术复杂度共同组成的。实践DDD还有一个好处,是让我们有机会分离核心业务逻辑和技术细节,让两个维度的复杂度有机会被解开和分治。如图3所示,核心业务逻辑是整个应用的核心,最好只是简单Java类(Plan Old Java Object,POJO)。也就是说,核心业务逻辑对技术细节没有任何依赖,依赖都是由外向内的,即使有由内向外的依赖,也应该通过依赖倒置来反转依赖的方向。通过这样的划分,Entities只要安安心心地处理业务逻辑就好,业务逻辑越复杂,这样划分带来的好处越明显。
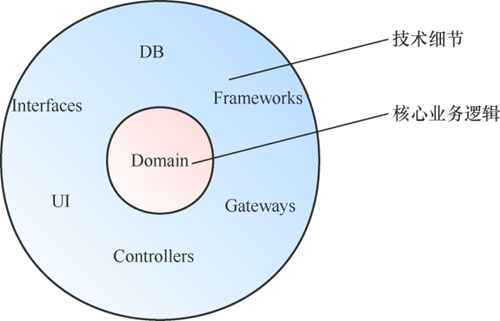
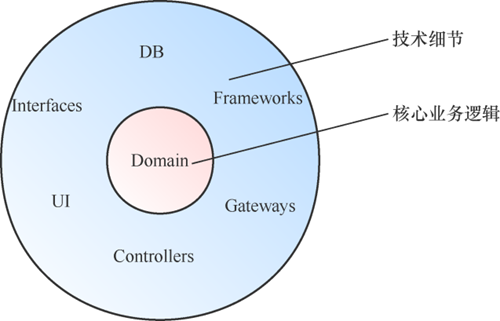 图3 业务逻辑和技术细节分离的架构
图3 业务逻辑和技术细节分离的架构
为什么说数据库、UI和框架都是技术细节呢?
● 数据库:业务逻辑不应该受限于存储方式,也就是不论你是使用关系型数据库还是NoSQL,都不应该影响业务逻辑的实现。数据本身很重要,但数据库技术仅仅是一个实现细节。
● UI:UI只是一种I/O设备的呈现,Web、WAP和Wireless都是不同的I/O,我们的核心业务逻辑应该与如何呈现解耦,以及针对不同的端可以使用不同的适配器(Adaptor)去做适配。
● 框架:不要让框架侵入我们的核心业务代码,以Spring为例,最好不要在业务对象中到处写@autowired注解。业务对象不应该依赖框架。
这么说来,这些技术细节是不重要了吗?不是的,技术细节是一个系统的必要组成部分,也非常重要。技术细节和核心业务逻辑是两个维度的重要性,如果把软件比喻成一个人,那么核心业务逻辑是大脑,技术细节是身体,二者都很重要,分开处理主要是为了降低复杂度。
4. DDD核心概念
4.1 领域实体
毫不夸张地说,我们的软件系统就是对现实世界的真实模拟。如图4所示,现实世界中的事物在软件世界中可以被模拟成一个对象:该事物在现实世界中被赋予什么职责,在软件世界中就被赋予什么职责;在现实世界中拥有什么特性,在软件世界中就拥有什么属性;在现实世界中拥有什么行为,在软件世界中就拥有什么函数;在现实世界中与哪些事物存在怎样的关系,在软件世界中就应当与它们发生怎样的关联。这正是面向对象编程的核心思想,也是DDD中寻找领域实体的核心思想。

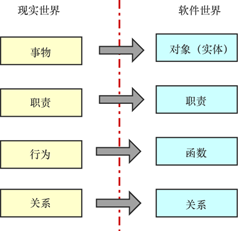 图4 现实世界与软件世界
图4 现实世界与软件世界
假如现在你需要设计一个中介系统,一个典型的User Story是“小明去找工作,中介让他留个电话,有工作机会就会通知他”。我们要如何寻找该业务中的关键领域实体呢?一个简单的方式就是“找名词”,分析这些名词,不难得到以下可能成为实体的候选项。
● 小明:一个求职者。
● 电话:求职者的相关信息,可以是一个属性。
● 中介:可以拆解为中介公司和中介公司的员工两个概念。
● 工作机会:对于中介系统来说,工作机会应该是最关键的实体之一。
● 通知:作为名词是一个实体,但是作为一个动词是在暗示我们可以使用Notify。
是的,对于这个简单的User Story,这样分析就可以了。当然,随着更多的Story被加入,我们会补充更多的实体,比如增加了“中介费是按照小明第一个月工资的30%收取”,那么就可能要引入“订单”和“支付”等实体。
以上就是我在实际工作中寻找领域实体的大致过程。从方法论的角度来说,也叫作“用例分析法”。
4.2 值对象
当你只关心某个对象的属性时,该对象便可作为一个值对象。为其添加有意义的属性,并赋予它相应的行为。我们需要将值对象看成不变对象,不要给它任何身份标识,还应该尽量避免像实体对象一样的复杂性。
4.3 聚合根
聚合根(Aggregate Root)是DDD中的一个概念,是一种更大范围的封装,会把一组有相同生命周期、在业务上不可分割的实体和值对象放在一起,只有根实体可以对外暴露引用,这也是一种内聚性的表现。
确定聚合边界要满足固定规则(Invariant),是指在数据变化时必须保持的一致性规则,具体规则如下。
● 根实体具有全局标识,最终负责检查规定规则。
● 聚合内的实体具有本地标识,这些标识在Aggregate内部才是唯一的。
● 外部对象不能引用除根Entity之外的任何内部对象。
● 只有Aggregate的根Entity才能直接通过数据库查询获取,其他对象必须通过遍历关联来发现。
● Aggegate内部的对象可以保持对其他Aggregate根的引用。
● Aggregate边界内的任何对象在修改时,整个Aggregate的所有固定规则都必须满足。
仍以银行转账的例子来说明,如图5所示,账号(Account)是客户信息(CustomerInfo)Entity和值对象(Address)的聚合根,交易(Tansaction)是流水(Journal)的聚合根,流水是因为交易才产生的,具有相同的生命周期。

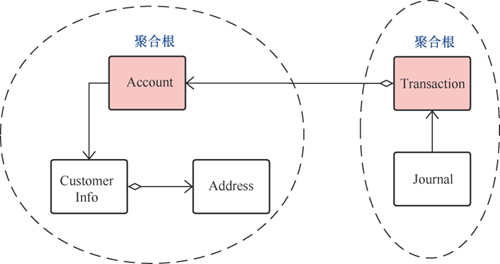 图5 聚合根示例
图5 聚合根示例
4.4 领域服务
有些领域中的动作是一些动词,看上去并不属于任何对象。它们代表了领域中的一个重要的行为,所以不能忽略它们或者简单地把它们合并到某个实体或者值对象中。当这样的行为从领域中被识别出来时,推荐的实践方式是将它声明成一个服务。这样的对象不再拥有内置的状态,其作用仅仅是为领域提供相应的功能。Service往往是以一个活动来命名,而不是Entity来命名。
例如在银行转账的例子中,转账(transfer)这个行为是一个非常重要的领域概念,但是它发生在两个账号之间,归属于账号Entity并不合适,因为一个账号Entity没有必要去关联它需要转账的账号Entity。在这种情况下,使用MoneyTransferDomainService就比较合适了。识别领域服务,主要看它是否满足以下3个特征。
(1)服务执行的操作代表了一个领域概念,这个领域概念无法自然地隶属于一个实体或者值对象。
(2)被执行的操作涉及领域中的其他对象。
(3)操作是无状态的。
4.5 领域事件
领域事件(Domain Event)是在一个特定领域由一个用户动作触发的,是发生在过去的行为产生的事件,而这个事件是系统中的其他部分或者关联系统感兴趣的。
为什么领域事件如此重要?因为在分布式环境下,很少有业务系统是单体的(Monolithic),消息作为分布式系统间耦合度最低、最健壮、最容易扩展的一种通信机制,是我们实现分布式系统互通的重要手段。关于领域事件,我们需要注意两点,分别是事件命名和事件内容。
1.事件命名
事件是表示发生在过去的事情,所以在命名上推荐使用Domain Name + 动词的过去式 + Event,这样可以更准确地表达业务语义。例如,在银行转账的例子中,对于转账成功和失败我们都需要发出事件通知,可以定义两个领域事件如下。
(1)MoneyTransferedEvent:表示转账成功发出的事件。
(2)MoneyTransferFailedEvent:表示转账失败发出的事件。
2.事件内容
事件内容在计算机术语中叫作payload,有以下两种形式。
(1)自恰(Enrichment):就是在事件的payload中尽量多放数据,这样consumer不需要回查就能处理消息,也就是自恰地处理消息。
(2)回查(Query-Back):这种方式是只在payload放置id属性,然后consumer通过回调的形式获取更多数据。这种形式会加重系统的负载,可能会引起性能问题。
4.6 边界上下文
领域实体的意义是有上下文的,比如同样是Apple,在水果店和苹果手机专卖店中表达出的含义就完全不一样。边界上下文(Bounded Context)的作用是限定模型的应用范围,在同一个上下文中,要保证模型在逻辑上统一,而不用考虑它是不是适用于边界之外的情况。
那么不同上下文之间的业务实体要如何实现交互呢?就像关系数据库和对象之间需要ORM一样,不同上下文之间的实体也需要映射。在DDD中,这种机制叫作上下文映射(Context Mapping),我们可以使用防腐层(Anti-Corruption)来完成映射的工作。
如图6所示,在我们开发的CRM系统中,商家的客户大部分是来自于ICBU网站的会员,虽然二者有很多属性都是一样的,但我们还是有必要引入防腐层来做上下文映射,主要有以下两个原因。
(1)虽然属性大部分一样,但二者的作用和行为在各自上下文中是不一样的。
(2)解耦影响,加入了防腐层之后,网站的会员变化就不会影响到CRM系统了。
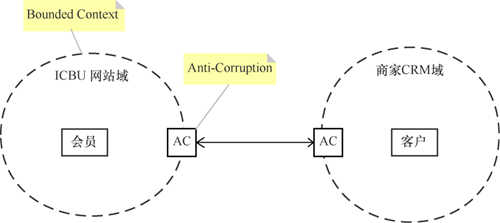
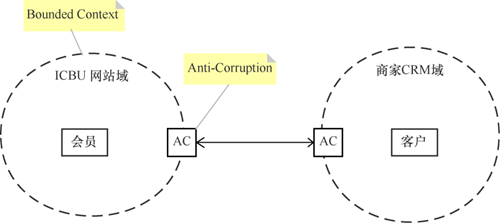 图6 边界上下文示例
图6 边界上下文示例参考资料: