一、线程
1.1 生产者消费者模型
"""
生产者:做包子(生产数据的)
消费者:吃包子(处理数据的)
进入的队列,用来解决供需不平衡的问题
定义一个队列,用来存放固定数量的数据,因此,
生产者和消费者不需要直接进行接触,就可以完成整个过程(生产-消费-供需)
"""
from multiprocessing import Queue, Process, JoinableQueue
import time
def producer(name, food, q):
for i in range(5):
data = '%s 生产了%s %s' % (name, food, i)
time.sleep(1)
print(data)
q.put(data) # 将生产者的数据放入队列中
def consumer(name, q):
while True:
data = q.get()
if data is None:
break
time.sleep(1.5)
print('%s 吃了 %s' % (name, data))
q.task_done() # 告诉你的队列,你已经将数据取出并且处理完毕
if __name__ == '__main__':
q = JoinableQueue() # 实例化一个队列对象
p1 = Process(target=producer, args=('zs', '包子', q))
p2 = Process(target=producer, args=('ls', '馒头', q))
c1 = Process(target=consumer, args=('ww', q))
c2 = Process(target=consumer, args=('ll', q))
p1.start()
p2.start()
c1.daemon = True
c2.daemon = True
c1.start()
c2.start()
# 等待生产者生产完所有的数据
p1.join()
p2.join()
# 在生产者生产完数据之后,往队列里面放一个提示性的消息,
# 告诉消费者已经没有数据,无需再等待
q.join() # 等待队列中数据全部取出
print('主')
1.2 线程介绍
将进程比喻成车间,那么线程就可以当作车间里的一条生产线
一个进程中至少有一个线程1.3 创建线程的两种方式
from threading import Thread
import time
# -----------方式一: 通过调用函数------------------
def task(name):
print('%s is starting' % name)
time.sleep(2)
if __name__ == '__main__':
t = Thread(target=task, args=('li',))
t.start()
print('主')
# li is starting
# 主
# -----------方式二:通过类------------------------
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print('%s is running' % self.name)
time.sleep(1)
print('%s is over' % self.name)
if __name__ == '__main__':
t = MyThread('zhangsan')
t.start()
print("主")1.4 join方法
与进程的join方法类似,同样是为了在线程执行完才进行其他的操作1.5 线程间的数据共享
from threading import Thread
x = 100
def task():
global x
x = 666
t = Thread(target=task)
t.start()
t.join()
print(x) # 6661.6 进程对象的其他方法和属性
from threading import Thread, active_count, current_thread
import os
import time
def task(name):
print("%s is running" % name, current_thread().name, current_thread().getName())
time.sleep(1)
print('%s is over' % name)
def info(name):
# current_thread().name :当前线程的名字 后面的 getNam一样的效果
print('%s is running' % name, current_thread().name, current_thread().getName())
time.sleep(1)
print('%s is over' % name)
t = Thread(target=task, args=('zhangsan',))
t1 = Thread(target=info, args=('lisi',))
t.start()
t1.start()
t.join() # 执行完之后才释放主进程资源
# time.sleep(3)
print(active_count())
print(os.getpid())
print('11', current_thread().name)
print('22', current_thread().getName())
"""
# 起的两个新线程
zhangsan is running Thread-1 Thread-1
lisi is running Thread-2 Thread-2
zhangsan is over # 线程1运行完
2 # 当前存活的线程数为2,1.读取线程个数时,线程t已经结束,但是线程2和主进程的线程未结束;
# 有时候,线程t和线程t1都运行结束,那么就会显示 1
# 通过在上面加time.sleep()几秒钟的时间,下面的active_count()就为1了
4124 # 获取进程id
MainThread # 这一行与下一行,表示都是运行在主进程下的(主)线程中
MainThread
lisi is over
"""1.7 守护进程
from threading import Thread
import time
def task(name):
print('%s is running' % name)
time.sleep(1)
print('%s is over' % name)
if __name__ == '__main__':
t = Thread(target=task, args=('li', ))
t.daemon = True
t.start()
print('主')
"""
# 未开启守护进程
li is running
主
li is over
"""
"""
# 开启了守护进程
li is running
主
"""1.8 互斥锁
from threading import Thread, Lock
import time
mutex = Lock()
n = 10.
def task():
global n
mutex.acquire() # 锁住
tmp = n
time.sleep(0.1)
n = tmp - 1
mutex.release() # 释放
t_list = []
for i in range(10):
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(n)1.9 GIL
GIL是一个互斥锁:
1.保证数据的安全(以牺牲效率来换取数据的安全)
2.阻止同一个进程内多个线程同时执行(不能并行,可并发)
3.GIL全局解释器存在的原因是Cpython解释器的内存管理不是线程安全的
ps: 每个进程中都有垃圾回收机制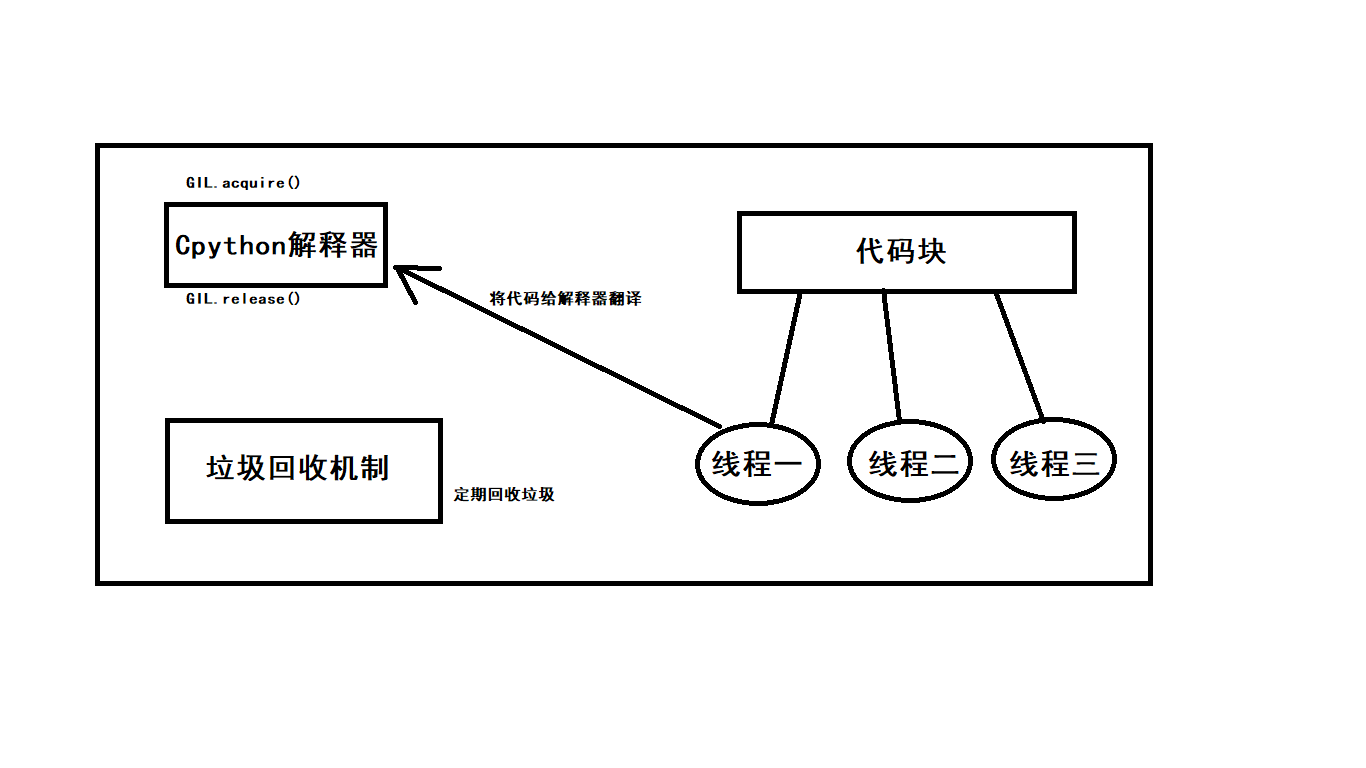
GIL全局解释器锁是所有解释性语言的通病
同一个进程下的多个线程不能实现并行,但是能够实现并发,多进程下的线程能够实现并行(有多个处理器)
Q:python多线程能够实现并行?
A:分情况讨论:
1.四个任务:计算密集的任务(假设每个任务耗时10s)
单核情况下:多线程好一点,消耗的资源少一点
多核情况下:开四个进程:10s多点
开四个线程:40s多点
2.四个任务:IO密集的任务(假设每个IO任务耗时10s)
单核情况:多线程好一点
多核情况:多线程好一点1.10 GIL与普通互斥锁的区别
对于不同的数据,要想保证安全,需要加不同的锁处理
GIL并不能保证数据的安全,它是对cpython解释器加锁,针对的是线程,保证的是同一线程的多线程之间的安全1.11 死锁与递归锁
1.死锁:
例子:
A被锁在了B的家里,身上揣着自己家的钥匙
B被锁在了A的家里,身上揣着自己家的钥匙
A,B互相等着另一把钥匙来打开门
两个进程A,B,二者都同时需要获取数据a和b两个数据之后,才能开始完成相应的操作,
但是二者一旦运行并且A获取了数据a,B获取了数据b,A接下来便会一直等待获取数据b,
B会一直等待获取数据a,这便产生了死锁。
2.递归锁:
递归锁,调用RLock
当一个线程抢到了锁,可再次(多次)得到这个锁,并且每次得到这个锁都会对锁
进行标记+1(类似于引用计数),在标记减为0之前,其他线程都不可以操作from threading import Thread,Lock,RLock
import time
"""
自定义锁一次acquire必须对应一次release,不能连续acquire
递归锁可以连续的acquire,每acquire一次计数加一:针对的是第一个抢到我的人
"""
import random
# mutexA = Lock()
# mutexB = Lock()
mutexA = mutexB = RLock() # 抢锁之后会有一个计数 抢一次计数加一 针对的是第一个抢到我的人
class MyThead(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
mutexA.acquire()
print('%s 抢到A锁了'%self.name)
mutexB.acquire()
print('%s 抢到B锁了' % self.name)
mutexB.release()
print('%s 释放了B锁'%self.name)
mutexA.release()
print('%s 释放了A锁'%self.name)
def func2(self):
mutexB.acquire()
print('%s 抢到了B锁'%self.name)
time.sleep(1)
mutexA.acquire()
print('%s 抢到A锁了' % self.name)
mutexA.release()
print('%s 释放了A锁' % self.name)
mutexB.release()
print('%s 释放了B锁' % self.name)
for i in range(10):
t = MyThead()
t.start()1.12 信号量
跟普通的互斥锁区别在于,普通的互斥锁是单个的数据的锁,所有的线程抢这一个东西
信号量是,包含多个锁的多个数据,所有的线程抢多把锁from threading import Thread,Semaphore
import time
import random
sm = Semaphore(5) # 五个厕所五把锁
# 跟你普通的互斥锁区别在于,普通的互斥锁是独立卫生间,所有人抢一把锁
# 信号量 公共卫生间 有多个坑,所有人抢多把锁
def task(name):
sm.acquire()
print('%s正在蹲坑'%name)
# 模拟蹲坑耗时
time.sleep(random.randint(1,5))
sm.release()
if __name__ == '__main__':
for i in range(20):
t = Thread(target=task,args=('伞兵%s号'%i,))
t.start()2.13 event事件
例子:车等红路灯
人为的设置条件,当满足什么条件的时候,就进行什么操作from threading import Event,Thread
import time
event = Event()
def light():
print('红灯亮着!')
time.sleep(3)
event.set() # 解除阻塞,给我的event发了一个信号
print('绿灯亮了!')
def car(i):
print('%s 正在等红灯了'%i)
event.wait() # 阻塞
print('%s 加油门飙车了'%i)
t1 = Thread(target=light)
t1.start()
for i in range(10):
t = Thread(target=car,args=(i,))
t.start()2.14 线程queue
1.普通级别的q
2.先进后出的q
3.具有优先级的qimport queue
# 普通的q
q = queue.Queue(3)
q.put(1)
q.put(2)
q.put(3)
print(q.get())
print(q.get())
print(q.get())
# 先进后出q
q = queue.LifoQueue(5)
q.put(1)
q.put(2)
q.put(3)
q.put(4)
print(q.get())
# 优先级q
q = queue.PriorityQueue()
q.put((10, 'a'))
q.put((-1, 'b'))
q.put((100, 'c'))
print(q.get())
print(q.get())
print(q.get())
结果:
(-1, 'b')
(10, 'a')
(100, 'c')