Spark On Yarn 有两种运行模式:
- Yarn - Cluster
- Yarn - Client
他们的主要区别是:
Cluster: Spark的Driver在App Master主进程内运行, 该进程由集群上的YARN管理, 客户端可以在启动App Master后退出.
Client: Driver在提交作业的Client中运行, App Master仅用于从YARN请求资源.
这里以Client为例介绍:
Yarn-Client运行模式
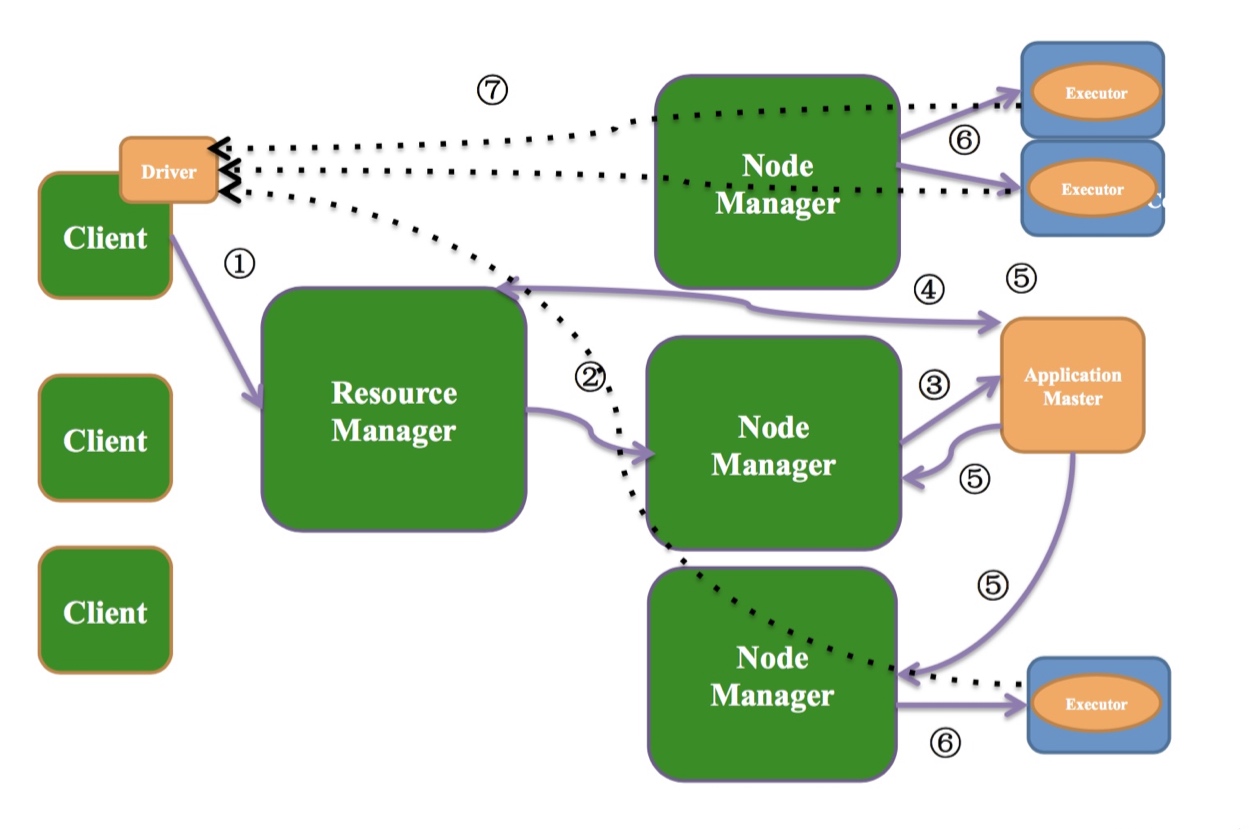 

如上图:
Yarn-Client模式中,Driver运行在客户端(提交Spark程序的机器, 代码中Main方法运行的机器).
作业提交过程
- Client端提交作业到ResourceManager
(连接到ResourceManager, 获取queue,resource等信息,upload app jar,设置运行环境和container上下文) - ResourceManager找一个NodeManager
- NodeManager启动ApplicationMaster(在运行的时候指定占用多少资源)
- ApplicationMaster启动之后跟ResourceManager通信,为Executor申请资源.
- ApplicationMaster申请资源之后跟NodeManager通信
- 启动Executor
- Exector启动之后会跟Driver通信领取任务.
每个Spark程序由1个Driver和多个Executor构成.
Executor个数, 内存, cpu多少由用户控制(默认1g内存 1个cpu 2个executor)
WorkCount--逻辑查询计划--物理查询计划
逻辑查询计划
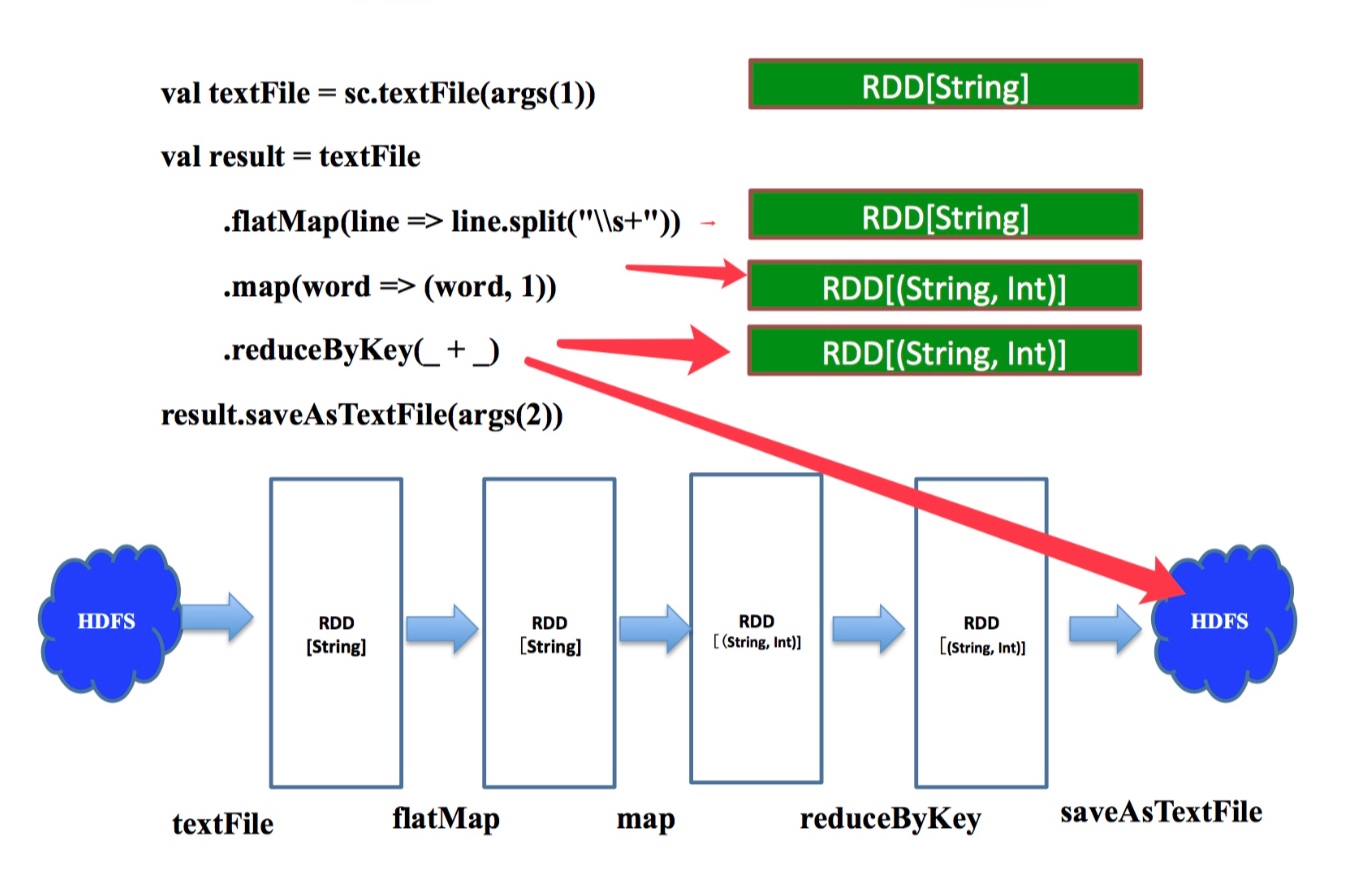 

上图右侧绿框代表每一步算子计算之后的结果
sc.textFile取hdfs路径生成rddtextFile.flatMap把rdd中的一行数据按照s+(匹配任何空白字符,包括空格、制表符、换页符等等)拆成多行work=>(work, 1)把每条数据x 转换成(x, 1)这样key-value对的元组.reduceByKey(_ + _)按照每个key聚合,取value的总和(每个单词出现的次数)saveAsTextFile这是一个action操作,把最终结果写到hdfs
上图的下半部分是workcount作业的逻辑查询计划.
物理查询计划
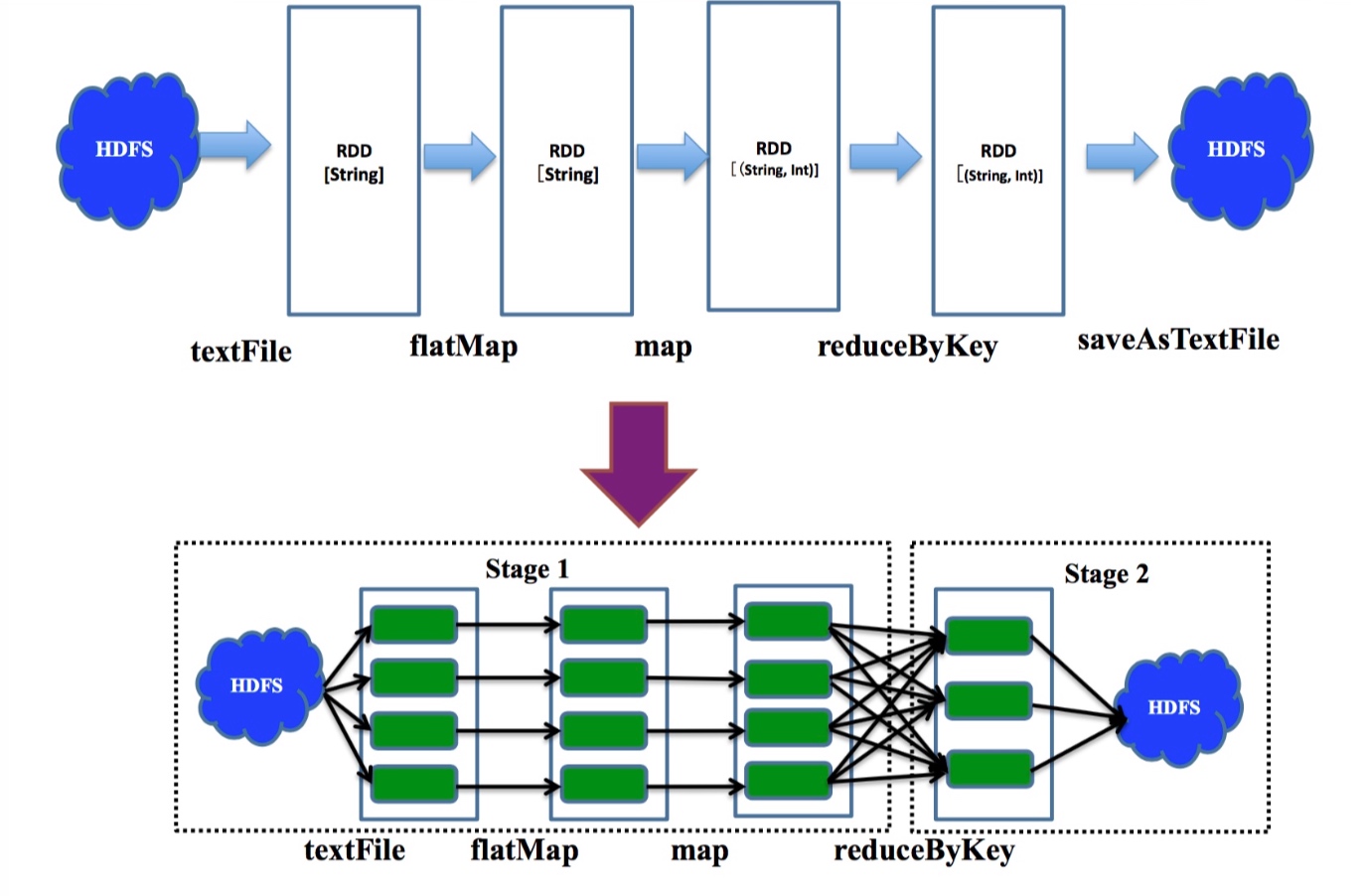 

上图上半部分展示了各级算子值键的依赖关系(逻辑查询计划)
下半部分的每个绿块代表一个partition的数据,多个partition值键并行计算, 遇到会产生shuffle的reduceByKey操作时划分stage.
窄依赖:
指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区
宽依赖:
是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区
stage内部是窄依赖,stage间是宽依赖.
原文链接: