DAGScheduler的主要作用有2个:
一、把job划分成多个Stage(Stage内部并行运行,整个作业按照Stage的顺序依次执行)
二、提交任务
以下分别介绍下DAGScheduler是如何做这2件事情的,然后再跟源码看下DAGScheduler的实现。
一、如何把Job划分成多个Stage
1) 回顾下宽依赖和窄依赖
窄依赖:父RDD的每个分区只被子RDD的一个分区使用。(map,filter,union操作等)
宽依赖:父RDD的分区可能被多个子RDD的分区使用。(reduceByKey,groupByKey等)
如下图所示,左侧的算子为窄依赖, 右侧为宽依赖
 

窄依赖可以支持在同一个集群Executor上,以管道形式顺序执行多条命令,例如在执行了map后,紧接着执行filter。分区内的计算收敛,不需要依赖所有分区的数据,可以并行地在不同节点进行计算。所以它的失败回复也更有效,因为它只需要重新计算丢失的parent partition即可。最重要的是窄依赖没有shuffle过程,而宽依赖由于父RDD的分区可能被多个子RDD的分区使用,所以一定伴随着shuffle操作。
2) DAGScheduler 如何把job划分成多个Stage
DAGScheduler会把job划分成多个Stage,如下图sparkui上的截图所示,job 0 被划分成了3个stage
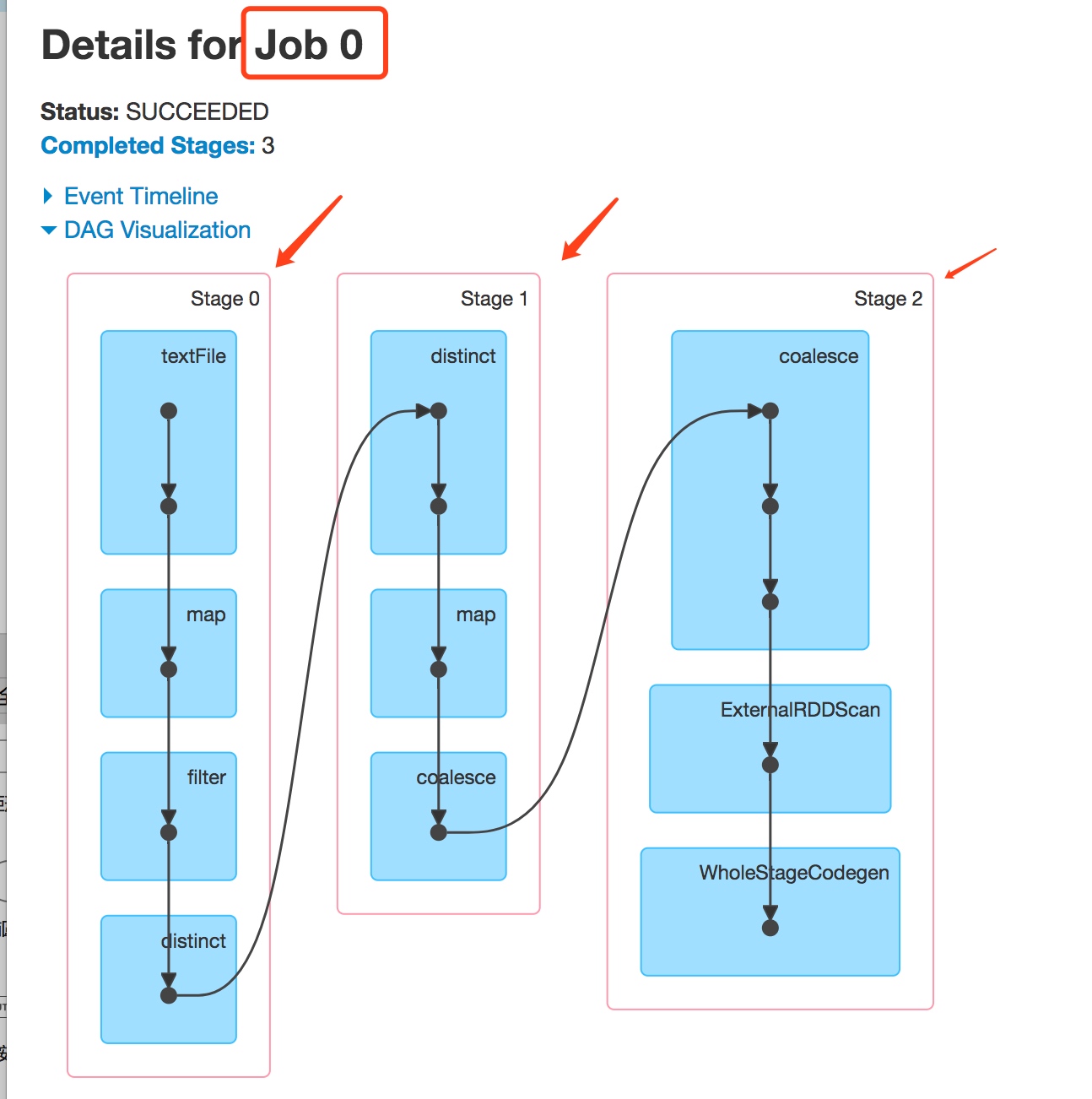 

DAGScheduler划分Stage的过程如下:
DAGScheduler会从触发action操作的那个RDD开始往前倒推,首先会为最后一个RDD创建一个stage,然后往前倒推的时候,如果发现对某个RDD是宽依赖(产生Shuffle),那么就会将宽依赖的那个RDD创建一个新的stage,那个RDD就是新的stage的最后一个RDD。然后依次类推,继续往前倒推,根据窄依赖或者宽依赖进行stage的划分,直到所有的RDD全部遍历完成为止。
3) wordcount的Stage划分
在前面大话spark(3)-一图深入理解WordCount程序在Spark中的执行过程中,我画过一张wordcount作业的Stage的划分的图,如下:
 

可以看出上图中,第一个stage的3个task并行执行,遇到reduceByKey这个产生shuffle的操作开始划分出新的Stage。但是其实这张图是不准确的。
其实对于每一种有shuffle的操作,比如groupByKey、reduceByKey、countByKey的底层都对应了三个RDD:MapPartitionsRDD、ShuffleRdd、MapPartitionsRDD
(宽依赖shuffle生成的rdd为ShuffleRdd)
其中Shuffle发生在第一个RDD和第二个RDD之间,前面说过如果发现对某个RDD是宽依赖(产生Shuffle),那么就会将宽依赖的那个RDD创建一个新的stage
所以说上图中 reduceByKey操作其实对应了3个RDD,其中第一个RDD会被划分到Stage1中!
4) DAGScheduler划分Stage源码
RDD类中所有的action算子触发计算都会调用sc.runjob方法, 而sc.runjob方法底层都会调用到SparkContext中的dagscheduler对象的runJob方法。
例如count这个action操作
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
一直追着runJob方法往底层看最终调用dagScheduler.runJob,传入调用这个方法的rdd
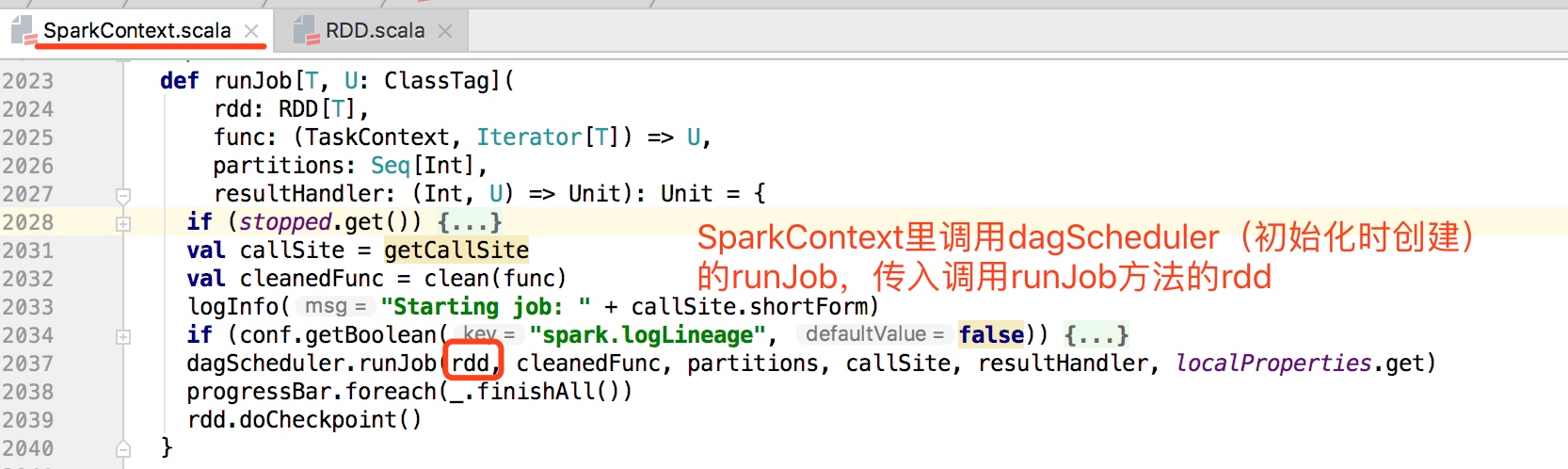 

dagScheduler.runJob内部调用submitJob提交当前的action到scheduler
submitJob内部调用DAGSchedulerEventProcessLoop发送JobSubmitted的信息,
在JobSubmitted内部最终调用dagScheduler的handleJobSubmitted(dagScheduler的核心入口)。
handleJobSubmitted方法如下:
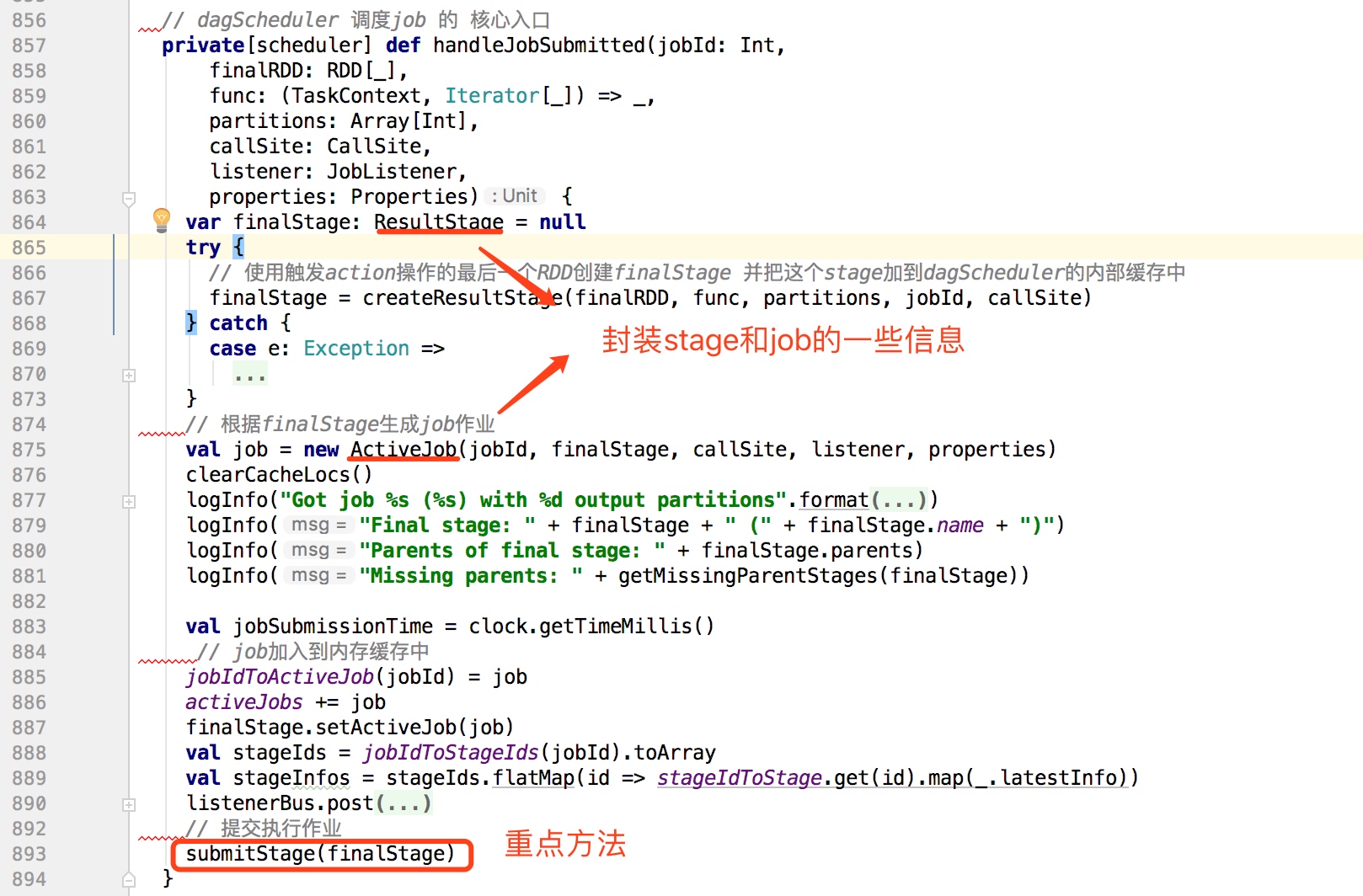 

上面代码中submitStage提交作业,其内代码如下:
 

submitStage方法中调用getMissingParentStages方法获取finalStage的父stage,
如果不存在,则使用submitMissingTasks方法提交执行;
如果存在,则把该stage放到waitingStages中,同时递归调用submitStage。通过该算法把存在父stage的stage放入waitingStages中,不存在的作为作业运行的入口。
其中最重要的getMissingParentStages中是stage划分的核心代码,如下:
 

这里就是前面说到的stage划分的方式,查看最后一个rdd的依赖,如果是窄依赖,则不创建新的stage,如果是宽依赖,则用getOrCreateShuffledMapStage方法创建新的rdd,依次往前推。
所以Stage的划分算法最核心的两个方法为submitStage何getMissingParentStage
二、提交任务
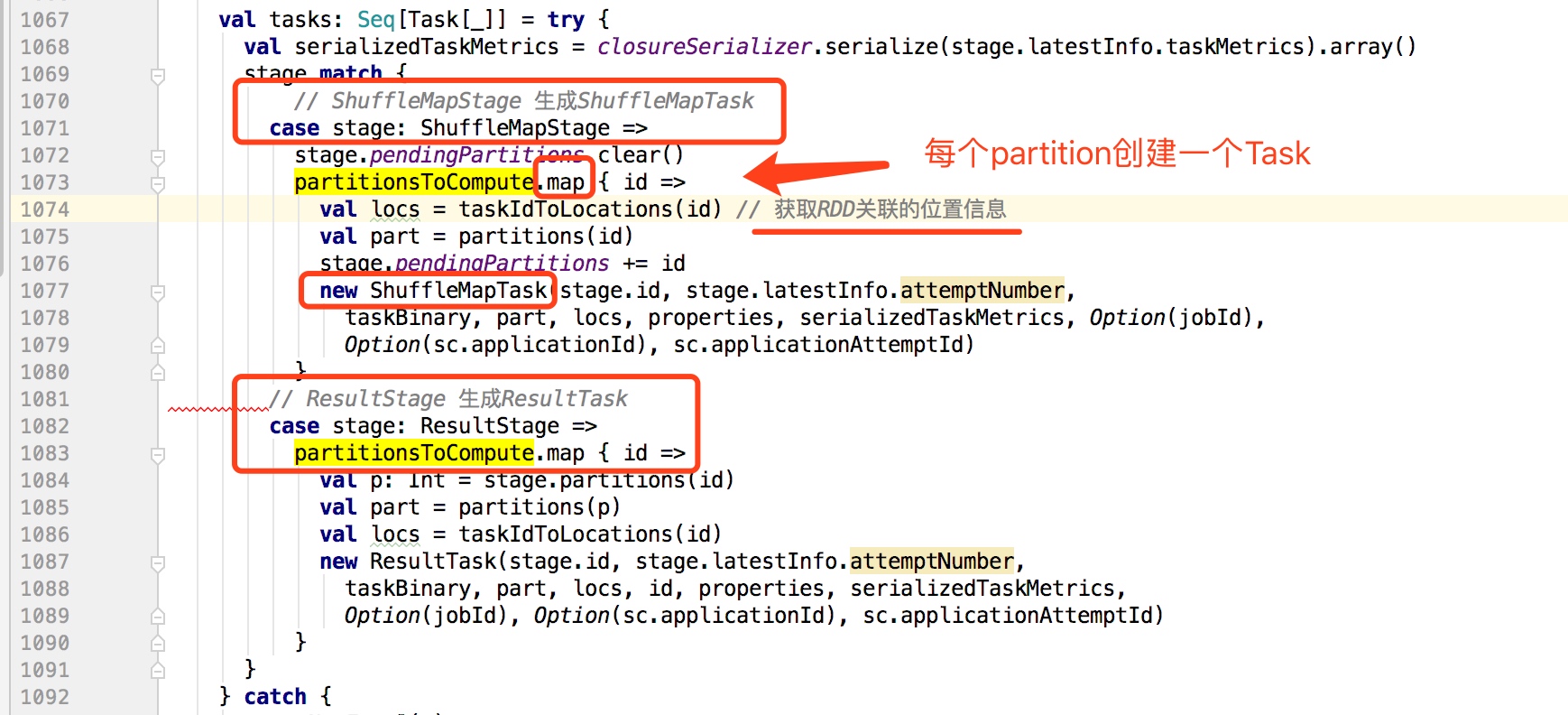
当Stage提交运行后,在DAGScheduler的submitMissingTasks方法中,会根据Stage的Partition个数拆分对应个数任务,这些任务组成一个TaskSet提交到TaskScheduler进行处理。
对于ResultStage(最后一个Stage)生成ResultTask,对于ShuffleMapStage生成ShuffleMapTask。
每一个TaskSet包含对应Stage的所有task,这些Task的处理逻辑完全一样,不同的是对应处理的数据,而这些数据是对应其数据分片的(Partition)。
submitMissingTasks如下:
 


 

原文链接: