前文介绍了python的scrapy爬虫框架和登录知乎的方法.
这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中.
首先,看一下我要爬取哪些内容:
如下图所示,我要爬取一个问题的6个信息:
- 问题的id(question_id)
- 标题(title)
- 问题描述(intro)
- 回答个数(answer_num)
- 关注人数(attention_uv)
- 浏览次数(read_pv)
 

爬取结果我保存到mysql数据库中,表名为:zhihu_question
如下图中,红框里的就是上图是有人为我的穿着很轻浮,我该如何回应?问题的信息.
(回答个数,关注着和浏览次数数据不一致是因为我是在爬取文章信息之后的一段时间才抽出来时间写的文章,在这期间回答个数,关注着和浏览次数都会增长.)
 

爬取方法介绍
我用的是scrapy框架中自带的选择器selectors.
selectors通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。 CSS 是一门将HTML文档样式化的语言。
XPath最最直观的介绍:
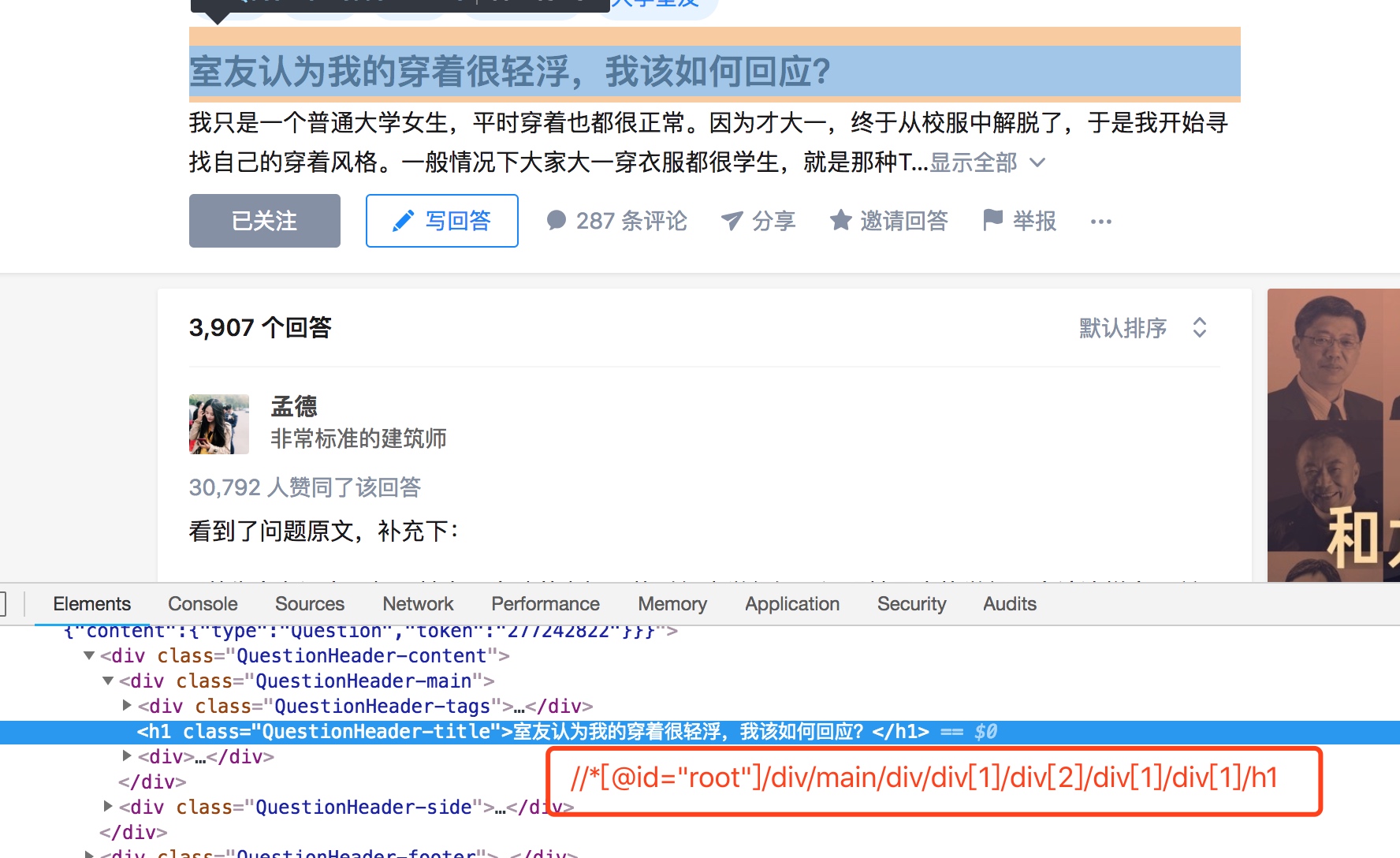
例如:知乎问题页面上的标题的XPath如下:
图中红框里就是标题的XPath.(这只是一个直观的介绍,还有一些细节可以在代码中看到)

爬取代码:
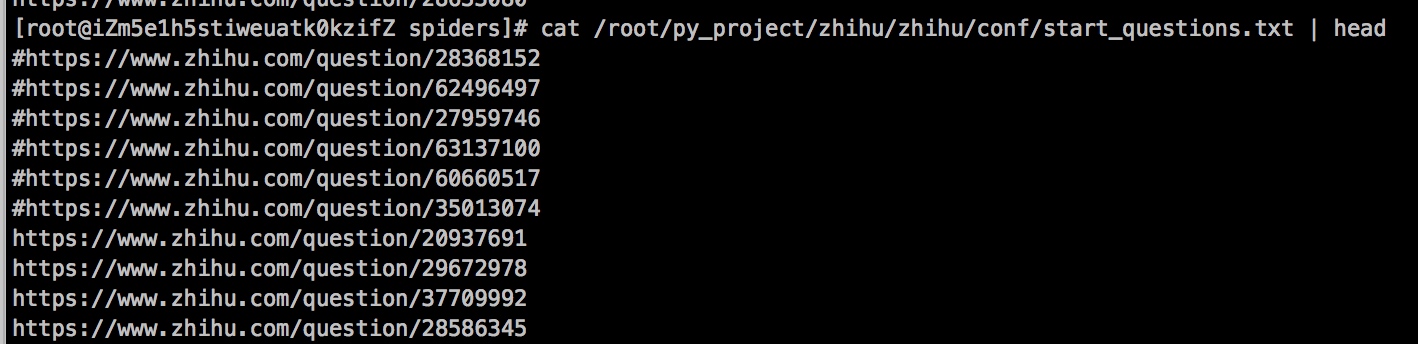
爬取问题的相关信息只需要问题url即可,我这里把收集的问题url写到文件中,爬虫程序去遍历文件,然后依次爬取.
我是在登录成功知乎后的check_login这个方法里面构造的起始url,所以读文件的方法也在这里,代码如下:
def check_login(self, response):
# 验证登录成功之后构造初始问题url
file = open("/root/py_project/zhihu/zhihu/conf/start_questions.txt")
while 1:
line = file.readline()
line = line.strip('
') #去掉最后的换行
if not line:
break
if(line[0:1] == "#"):
#如果是#开头的url, 跳过
print line
pass
else:
print("current url : " + line)
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
file.close()
其中最重要的一行是:
yield scrapy.Request(line,callback=self.parse_question, headers=self.headers)
yield scrapy.Request 代表开始爬取一条url,如果有多个url就yield多次. 这里的次数等同于start_question.txt中非#开头的url
如下:

callback=self.parse_question 是请求url地址后,返回的response的回调处理函数,也是整个爬取过程中最核心的代码.
如下:
def parse_question(self,response):
item = QuestionItem()
url = response.url
questionid=url[url.rindex("/")+1:]
item['questionid']=questionid
item['title']=response.selector.xpath('//*[@class="QuestionHeader-title"]/text()')[0].extract()
descarr=response.selector.xpath('//span[@itemprop="text"]/text()')
if len(descarr) > 0:
item['desc']=descarr[0].extract()
else:
item['desc']="-"
item['answer_num']=response.selector.xpath('//*[@id="QuestionAnswers-answers"]/div/div/div[1]/h4/span/text()[1]')[0].extract().replace(',','')
item['attention_uv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[0].extract().replace(',','')
item['read_pv']=response.selector.xpath('//strong[@class="NumberBoard-itemValue"]/text()')[1].extract().replace(',','')
yield item
其中主要代码是用selectors.xpath选取我们需要的问题信息(注意:这里的路径并不一定与 chrome的debug模式中复制的xpath一致,直接复制的xpath一般不太能用,自己看html代码结构写的),
获取到问题的信息之后放到item.py中定义好的QuestionItem对象中,然后yield 对象 , 会把对象传递到配置的pipelines中.
pipelines一般是在配置文件中配置,
因为这里爬取问题只保存到mysql数据库,并不下载图片,(而爬取答案需要下载图片)所以各自在在爬虫程序中定义的pipelines,如下:
custom_settings = {
'ITEM_PIPELINES' : {
'zhihu.mysqlpipelines.MysqlPipeline': 5
#'scrapy.pipelines.images.ImagesPipeline': 1,#这个是scrapy自带的图片下载pipelines
}
}
以上是爬取知乎问题的整个大致过程.
后文介绍爬取收藏夹下的回答 和 问题下的回答(包括内容和图片).