1,简述socket 通信原理
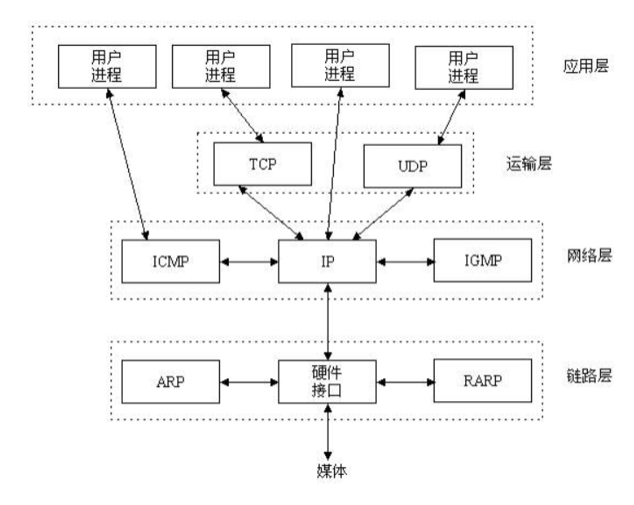

如上图,socket通信建立在应用层与TCP/IP协议组通信(运输层)的中间软件抽象层,它是一组接口,在设计模式中,socket其实就是一个门面模式,它把复杂的TCP/IP协议组隐藏在Socket接口后面,对于用户来说,一组简单的接口就是全部,让socket去组织数据,以符合指定的协议。
所以,经常对用户来讲,socket就是ip+prot 即IP地址(识别互联网中主机的位置)+port是程序开启的端口号
socket通信如下:
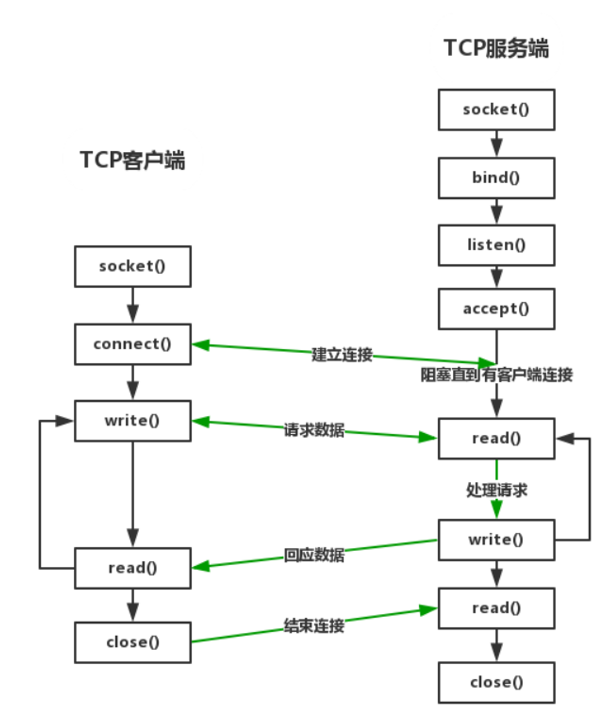
客户端
|
1
2
3
4
5
6
7
8
9
10
11
12
|
# _*_ coding: utf-8 _*_import socketip_port = ('127.0.0.1',9696)link = socket.socket(socket.AF_INET,socket.SOCK_STREAM)link.connect(ip_port)print("开始发送数据")cmd = input("client请输入要发送的数据>>>>").strip()link.send(cmd.encode('utf-8'))recv_data = link.recv(1024)print("这是受到的消息:",recv_data)link.close() |
服务端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# _*_ coding: utf-8 _*_import socketip_port = ('127.0.0.1',9696)link = socket.socket(socket.AF_INET,socket.SOCK_STREAM)link.bind(ip_port)link.listen(5)conn,addr = link.accept()#这里,因为我们知道自己写的少,所以1024够用recv_data = conn.recv(1024)print("这是受到的消息:",recv_data)cmd = input("server请输入要发送的数据>>>>").strip()conn.send(cmd.encode('utf-8'))conn.close()link.close() |
2,粘包的原因和解决方法?
TCP是面向流的协议,发送文件内容是按照一段一段字节流发送的,在接收方看来不知道文件的字节流从和开始,从何结束。
UDP是面向消息的协议,每个UDP段都是一个消息,
|
1
2
3
4
5
6
7
|
直接原因: 所谓粘包问题主要还是因为接收方不知道消息之间的界限,不知道一次性提取多少字节的数据所造成的根本原因: 发送方引起的粘包是由TCP协议本身造成的,TCP为了提高传送效率,发送方往往要收集到足够多的数据才发送一个TCP段,若连续几次需要send的数据都很少,通常TCP会根据优化算法把这些数据合成到一个TCP段后一次发送过去,这样接收方就受到了粘包数据。 |
如果需要一直收发消息,加一个while True即可。但是这里有个1024的问题,即粘包,
粘包的根源在于:接收端不知道发送端将要发的字节流的长度,所以解决粘包问题的方法就是围绕如何让发送端在发送数据前,把自己将要发送的字节流大小让接收段知道,然后接收端来一个死循环,接收完所有的数据即可。
粘包解决的具体做法:为字节流加上自定义固定长度报头,报头中包含字节流长度,然后依次send到对端,对端在接受时,先从缓存中取出定长的报头,然后再取真是数据。
客户端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# _*_ coding: utf-8 _*_import socketimport structimport jsonphone = socket.socket(socket.AF_INET,socket.SOCK_STREAM)phone.connect(('127.0.0.1',8080)) #连接服务器while True: # 发收消息 cmd = input('请你输入命令>>:').strip() if not cmd:continue phone.send(cmd.encode('utf-8')) #发送 #先收报头的长度 header_len = struct.unpack('i',phone.recv(4))[0] #吧bytes类型的反解 #在收报头 header_bytes = phone.recv(header_len) #收过来的也是bytes类型 header_json = header_bytes.decode('utf-8') #拿到json格式的字典 header_dic = json.loads(header_json) #反序列化拿到字典了 total_size = header_dic['total_size'] #就拿到数据的总长度了 #最后收数据 recv_size = 0 total_data=b'' while recv_size<total_size: #循环的收 recv_data = phone.recv(1024) #1024只是一个最大的限制 recv_size+=len(recv_data) #有可能接收的不是1024个字节,或许比1024多呢, # 那么接收的时候就接收不全,所以还要加上接收的那个长度 total_data+=recv_data #最终的结果 print('返回的消息:%s'%total_data.decode('gbk'))phone.close() |
服务端
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
# _*_ coding: utf-8 _*_import socketimport subprocessimport structimport jsonphone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #买手机phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)phone.bind(('127.0.0.1',8080)) #绑定手机卡phone.listen(5) #阻塞的最大数print('start runing.....')while True: #链接循环 coon,addr = phone.accept()# 等待接电话 print(coon,addr) while True: #通信循环 # 收发消息 cmd = coon.recv(1024) #接收的最大数 print('接收的是:%s'%cmd.decode('utf-8')) #处理过程 res = subprocess.Popen(cmd.decode('utf-8'),shell = True, stdout=subprocess.PIPE, #标准输出 stderr=subprocess.PIPE #标准错误 ) stdout = res.stdout.read() stderr = res.stderr.read() # 制作报头 header_dic = { 'total_size': len(stdout)+len(stderr), # 总共的大小 'filename': None, 'md5': None } header_json = json.dumps(header_dic) #字符串类型 header_bytes = header_json.encode('utf-8') #转成bytes类型(但是长度是可变的) #先发报头的长度 coon.send(struct.pack('i',len(header_bytes))) #发送固定长度的报头 #再发报头 coon.send(header_bytes) #最后发命令的结果 coon.send(stdout) coon.send(stderr) coon.close()phone.close() |
3,TCP/IP协议详情
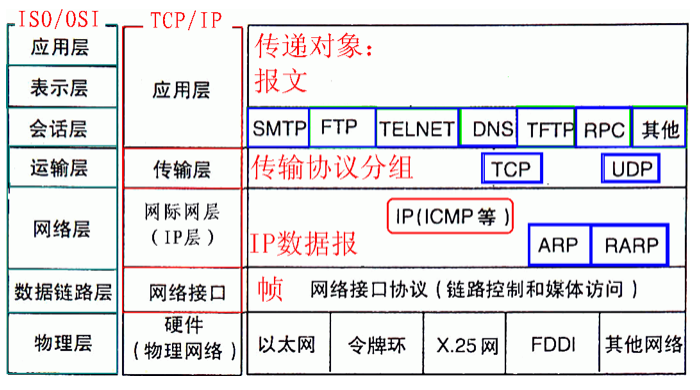
TCP和UDP协议在传输层
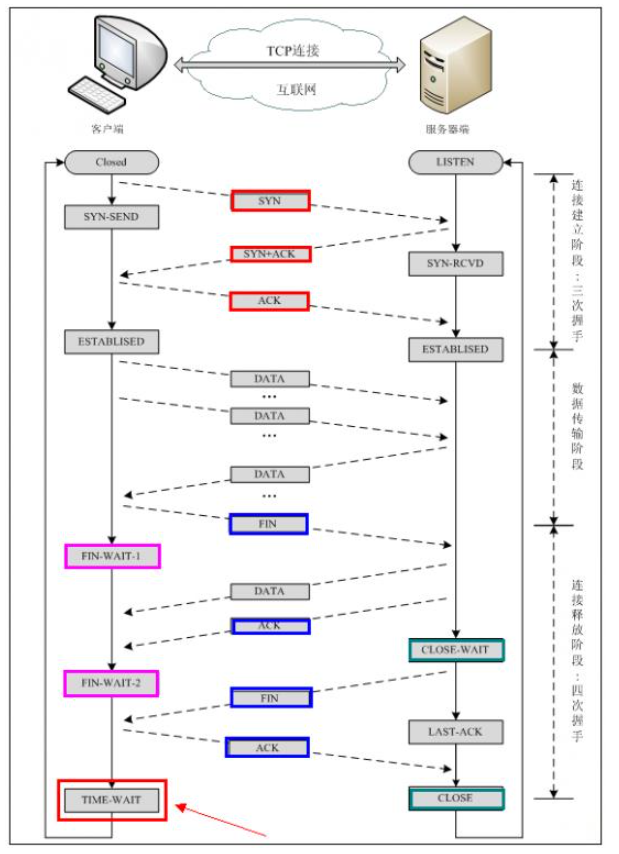
4,简述3次握手,四次挥手?
|
1
2
3
4
5
6
7
8
9
10
|
三次握手: client发送请求建立通道; server收到请求并同意,同时也发送请求建通道; client收到请求并同意,建立完成 四次挥手: client发送请求断开通道; server收到请求并同意,同时还回复client上一条消息; server也发送请求断开通道; client受到消息结束 |
5,定义一个学生类,然后。。。
__init__被称为构造方法或者初始化方法,在例实例化过程中自动执行,目的是初始化实例的一些属性,每个实例通过__init__初始化的属性都是独有的。
self就是实例本身,你实例化时候python解释器就会自动把这个实例本身通过self参数传进去。
这个object,就是经典类与新式类的问题了。
|
1
2
3
4
5
6
7
|
1.只有在python2中才分新式类和经典类,python3中统一都是新式类2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类 |
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# _*_ coding: utf-8 _*_class Student(object): def __init__(self,name,age,sex): self.name = name self.sex = sex self.age = age def talk(self): print("hello,my name is %s "%self.name)p = Student('james',12,'male')p.talk()print(p.__dict__)# 结果:# hello,my name is james# {'name': 'james', 'sex': 'male', 'age': 12} |
6,继承
|
1
2
|
继承: 继承就是类与类的关系,是一种创建新类的方式,在python中,新建的类可以继承一个或多个父类,父类可以称为基类或超类,新建的类称为派生类或子类。 |
python中类的继承分为:单继承和多继承
|
1
2
3
4
5
6
7
8
9
10
11
|
class ParentClass1: #定义父类 passclass ParentClass2: #定义父类 passclass SubClass1(ParentClass1): #单继承,基类是ParentClass1,派生类是SubClass passclass SubClass2(ParentClass1,ParentClass2): #python支持多继承,用逗号分隔开多个继承的类 pass |
查看继承:
|
1
2
3
4
5
|
>>> SubClass1.__bases__#__base__只查看从左到右继承的第一个子类,__bases__则是查看所有继承的父类(<class '__main__.ParentClass1'>,)>>> SubClass2.__bases__(<class '__main__.ParentClass1'>, <class '__main__.ParentClass2'>) |
7,多态
多态指一种事物有多种形态,那为什么要使用多态呢?
|
1
2
3
4
5
6
7
|
1.增加了程序的灵活性 以不变应万变,不论对象千变万化,使用者都是同一种形式去调用,如func(animal)2.增加了程序额可扩展性 通过继承animal类创建了一个新的类,使用者无需更改自己的代码,还是用func(animal)去调用 |
举个例子:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
>>> class Cat(Animal): #属于动物的另外一种形态:猫... def talk(self):... print('say miao')...>>> def func(animal): #对于使用者来说,自己的代码根本无需改动... animal.talk()...>>> cat1=Cat() #实例出一只猫>>> func(cat1) #甚至连调用方式也无需改变,就能调用猫的talk功能say miao'''这样我们新增了一个形态Cat,由Cat类产生的实例cat1,使用者可以在完全不需要修改自己代码的情况下。使用和人、狗、猪一样的方式调用cat1的talk方法,即func(cat1)''' |
8,封装
首先说一下隐藏,在python中用双下划线开头的方式将属性隐藏起来(即设置成私有属性)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#其实这仅仅这是一种变形操作#类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式:class A: __N=0 #类的数据属性就应该是共享的,但是语法上是可以把类的数据属性设置成私有的如__N,会变形为_A__N def __init__(self): self.__X=10 #变形为self._A__X def __foo(self): #变形为_A__foo print('from A') def bar(self): self.__foo() #只有在类内部才可以通过__foo的形式访问到.#A._A__N是可以访问到的,即这种操作并不是严格意义上的限制外部访问,仅仅只是一种语法意义上的变形 |
封装不是单纯意义上的隐藏
1,封装数据
将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
class Teacher: def __init__(self,name,age): self.__name=name self.__age=age def tell_info(self): print('姓名:%s,年龄:%s' %(self.__name,self.__age)) def set_info(self,name,age): if not isinstance(name,str): raise TypeError('姓名必须是字符串类型') if not isinstance(age,int): raise TypeError('年龄必须是整型') self.__name=name self.__age=aget=Teacher('egon',18)t.tell_info()t.set_info('egon',19)t.tell_info() |
2,封装方法,目的是隔离复杂度
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
#取款是功能,而这个功能有很多功能组成:插卡、密码认证、输入金额、打印账单、取钱#对使用者来说,只需要知道取款这个功能即可,其余功能我们都可以隐藏起来,很明显这么做#隔离了复杂度,同时也提升了安全性class ATM: def __card(self): print('插卡') def __auth(self): print('用户认证') def __input(self): print('输入取款金额') def __print_bill(self): print('打印账单') def __take_money(self): print('取款') def withdraw(self): self.__card() self.__auth() self.__input() self.__print_bill() self.__take_money()a=ATM()a.withdraw() |
9,元类? 使用元类定义一个对象
|
1
2
3
4
|
元类是类的类,是类的模板元类是用来控制如何创建类的,正如类是创建对象的模板一样,而元类的主要目的是为了控制类的创建行为元类的实例化的结果为我们用class定义的类,正如类的实例为对象(f1对象是Foo类的一个实例,Foo类是 type 类的一个实例) |
10,说一下__new__和__init__的区别
根据官方文档:
-
__init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值。
-
__new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例,是个静态方法。
也就是,__new__在__init__之前被调用,__new__的返回值(实例)将传递给__init__方法的第一个参数,然后__init__给这个实例设置一些参数。
在python2.x中,从object继承得来的类称为新式类(如class A(object))不从object继承得来的类称为经典类(如class A()
新式类跟经典类的差别主要是以下几点:
1. 新式类对象可以直接通过__class__属性获取自身类型:type
2. 继承搜索的顺序发生了改变,经典类多继承时属性搜索顺序: 先深入继承树左侧,再返回,开始找右侧(即深度优先搜索);新式类多继承属性搜索顺序: 先水平搜索,然后再向上移动
例子:
经典类: 搜索顺序是(D,B,A,C)
|
1
2
3
4
5
6
7
8
9
10
11
|
>>> class A: attr = 1...>>> class B(A): pass...>>> class C(A): attr = 2...>>> class D(B,C): pass...>>> x = D()>>> x.attr1 |
新式类继承搜索程序是宽度优先
新式类:搜索顺序是(D,B,C,A)
|
1
2
3
4
5
6
7
8
9
10
11
|
>>> class A(object): attr = 1...>>> class B(A): pass...>>> class C(A): attr = 2...>>> class D(B,C): pass...>>> x = D()>>> x.attr2 |
3. 新式类增加了__slots__内置属性, 可以把实例属性的种类锁定到__slots__规定的范围之中。
4. 新式类增加了__getattribute__方法
5.新式类内置有__new__方法而经典类没有__new__方法而只有__init__方法
注意:Python 2.x中默认都是经典类,只有显式继承了object才是新式类
而Python 3.x中默认都是新式类(也即object类默认是所有类的祖先),不必显式的继承object(可以按照经典类的定义方式写一个经典类并分别在python2.x和3.x版本中使用dir函数检验下。
例如:
|
1
2
3
4
5
|
class A(): pass print(dir(A)) |
会发现在2.x下没有__new__方法而3.x下有。
接下来说下__new__方法和__init__的区别:
在python中创建类的一个实例时,如果该类具有__new__方法,会先调用__new__方法,__new__方法接受当前正在实例化的类作为第一个参数(这个参数的类型是type,这个类型在c和python的交互编程中具有重要的角色,感兴趣的可以搜下相关的资料),其返回值是本次创建产生的实例,也就是我们熟知的__init__方法中的第一个参数self。那么就会有一个问题,这个实例怎么得到?
注意到有__new__方法的都是object类的后代,因此如果我们自己想要改写__new__方法(注意不改写时在创建实例的时候使用的是父类的__new__方法,如果父类没有则继续上溯)可以通过调用object的__new__方法类得到这个实例(这实际上也和python中的默认机制基本一致),如:
|
1
2
3
4
5
6
7
8
|
class display(object): def __init__(self, *args, **kwargs): print("init") def __new__(cls, *args, **kwargs): print("new") print(type(cls)) return object.__new__(cls, *args, **kwargs) a=display() |
运行上述代码会得到如下输出:
|
1
2
3
4
5
|
new <class 'type'> init |
因此我们可以得到如下结论:
在实例创建过程中__new__方法先于__init__方法被调用,它的第一个参数类型为type。
如果不需要其它特殊的处理,可以使用object的__new__方法来得到创建的实例(也即self)。
于是我们可以发现,实际上可以使用其它类的__new__方法类得到这个实例,只要那个类或其父类或祖先有__new__方法。
|
1
2
3
4
5
6
7
8
9
10
11
12
|
class another(object): def __new__(cls,*args,**kwargs): print("newano") return object.__new__(cls, *args, **kwargs) class display(object): def __init__(self, *args, **kwargs): print("init") def __new__(cls, *args, **kwargs): print("newdis") print(type(cls)) return another.__new__(cls, *args, **kwargs) a=display() |
上面的输出是:
|
1
2
3
4
|
newdis<class 'type'>newanoinit |
所有我们发现__new__和__init__就像这么一个关系,__init__提供生产的原料self(但并不保证这个原料来源正宗,像上面那样它用的是另一个不相关的类的__new__方法类得到这个实例),而__init__就用__new__给的原料来完善这个对象(尽管它不知道这些原料是不是正宗的)
11,说一下深度优先和广度优先的区别
|
1
2
3
4
|
只有在python2中才分新式类和经典类,python3中统一都是新式类2.在python2中,没有显式的继承object类的类,以及该类的子类,都是经典类3.在python2中,显式地声明继承object的类,以及该类的子类,都是新式类4.在python3中,无论是否继承object,都默认继承object,即python3中所有类均为新式类 |
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如果继承了多个父类,那么属性的查找方式有两种,分别是:深度优先和广度优先
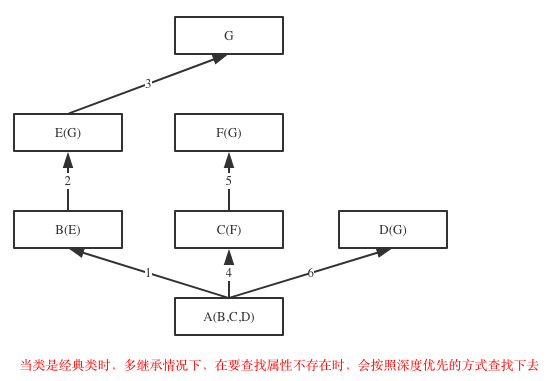
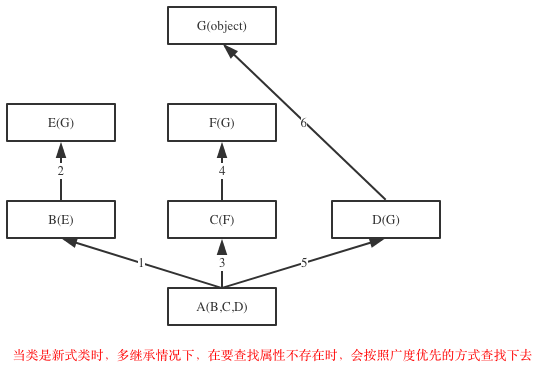
示范代码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
|
class A(object): def test(self): print('from A')class B(A): def test(self): print('from B')class C(A): def test(self): print('from C')class D(B): def test(self): print('from D')class E(C): def test(self): print('from E')class F(D,E): # def test(self): # print('from F') passf1=F()f1.test()print(F.__mro__) #只有新式才有这个属性可以查看线性列表,经典类没有这个属性#新式类继承顺序:F->D->B->E->C->A#经典类继承顺序:F->D->B->A->E->C#python3中统一都是新式类#pyhon2中才分新式类与经典类 |
12,说一下反射的原理
反射就是通过字符串映射到对象的属性,python的一切事物都是对象(都可以使用反射)
1,hasattr(object,name) 判断object中有没有对应的方法和属性
|
1
|
判断object中有没有一个name字符串对应的方法或属性 |
2,getattr(object, name, default=None) 获取object中有没有对应的方法和属性
3,setattr(x, y, v) 设置对象及其属性
4,delattr(x, y) 删除类或对象的属性
13,编写程序, 在元类中控制把自定义类的数据属性都变成大写.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
class Mymetaclass(type): def __new__(cls,name,bases,attrs): update_attrs={} for k,v in attrs.items(): if not callable(v) and not k.startswith('__'): update_attrs[k.upper()]=v else: update_attrs[k]=v return type.__new__(cls,name,bases,update_attrs) class Chinese(metaclass=Mymetaclass): country='China' tag='Legend of the Dragon' #龙的传人 def walk(self): print('%s is walking' %self.name) print(Chinese.__dict__)'''{'__module__': '__main__', 'COUNTRY': 'China', 'TAG': 'Legend of the Dragon', 'walk': <function Chinese.walk at 0x0000000001E7B950>, '__dict__': <attribute '__dict__' of 'Chinese' objects>, '__weakref__': <attribute '__weakref__' of 'Chinese' objects>, '__doc__': None}''' |
14,编写程序, 在元类中控制自定义的类无需init方法.
1.元类帮其完成创建对象,以及初始化操作;
2.要求实例化时传参必须为关键字形式,否则抛出异常TypeError: must use keyword argument
3.key作为用户自定义类产生对象的属性,且所有属性变成大写
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
class Mymetaclass(type): # def __new__(cls,name,bases,attrs): # update_attrs={} # for k,v in attrs.items(): # if not callable(v) and not k.startswith('__'): # update_attrs[k.upper()]=v # else: # update_attrs[k]=v # return type.__new__(cls,name,bases,update_attrs) def __call__(self, *args, **kwargs): if args: raise TypeError('must use keyword argument for key function') obj = object.__new__(self) #创建对象,self为类Foo for k,v in kwargs.items(): obj.__dict__[k.upper()]=v return obj class Chinese(metaclass=Mymetaclass): country='China' tag='Legend of the Dragon' #龙的传人 def walk(self): print('%s is walking' %self.name) p=Chinese(name='egon',age=18,sex='male')print(p.__dict__) |
15,简述静态方法和类方法
1:绑定方法(绑定给谁,谁来调用就自动将它本身当作第一个参数传入):
绑定方法分为绑定到类的方法和绑定到对象的方法,具体如下:
|
1
2
3
4
5
6
7
8
9
|
1. 绑定到类的方法:用classmethod装饰器装饰的方法。 为类量身定制 类.boud_method(),自动将类当作第一个参数传入 (其实对象也可调用,但仍将类当作第一个参数传入) 2. 绑定到对象的方法:没有被任何装饰器装饰的方法。 为对象量身定制 对象.boud_method(),自动将对象当作第一个参数传入 (属于类的函数,类可以调用,但是必须按照函数的规则来,没有自动传值那么一说) |
2:非绑定方法:用staticmethod装饰器装饰的方法
|
1
2
3
4
|
1. 不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。就是一个普通工具而已 注意:与绑定到对象方法区分开,在类中直接定义的函数,没有被任何装饰器 装饰的,都是绑定到对象的方法,可不是普通函数,对象调用该方法会自动传值,而 staticmethod装饰的方法,不管谁来调用,都没有自动传值一说 |
具体见:http://www.cnblogs.com/wj-1314/p/8675548.html
3,类方法与静态方法说明
1:self表示为类型为类的object,而cls表示为类也就是class
2:在定义普通方法的时候,需要的是参数self,也就是把类的实例作为参数传递给方法,如果不写self的时候,会发现报错TypeError错误,表示传递的参数多了,其实也就是调用方法的时候,将实例作为参数传递了,在使用普通方法的时候,使用的是实例来调用方法,不能使用类来调用方法,没有实例,那么方法将无法调用。
3:在定义静态方法的时候,和模块中的方法没有什么不同,最大的不同就是在于静态方法在类的命名空间之间,而且在声明静态方法的时候,使用的标记为@staticmethod,表示为静态方法,在叼你用静态方法的时候,可以使用类名或者是实例名来进行调用,一般使用类名来调用
4:静态方法主要是用来放一些方法的,方法的逻辑属于类,但是有何类本身没有什么交互,从而形成了静态方法,主要是让静态方法放在此类的名称空间之内,从而能够更加有组织性。
5:在定义类方法的时候,传递的参数为cls.表示为类,此写法也可以变,但是一般写为cls。类的方法调用可以使用类,也可以使用实例,一般情况使用的是类。
6:在重载调用父类方法的时候,最好是使用super来进行调用父类的方法。静态方法主要用来存放逻辑性的代码,基本在静态方法中,不会涉及到类的方法和类的参数。类方法是在传递参数的时候,传递的是类的参数,参数是必须在cls中进行隐身穿
7:python中实现静态方法和类方法都是依赖python的修饰器来实现的。静态方法是staticmethod,类方法是classmethod。