1,如何模拟登陆
2,验证码识别
3,分布式爬取网页
4,数据存储
5,网页更新
6,基于关键字的微博爬取
然后上面的每一个问题其实研究起来都是很有意思的。虽然上面的每一个问题都有很多人解决,但是我感觉都不是很漂亮,下面一点一点来分析:
第一个,模拟登陆。我估计啊,每一个爬微博数据的人都会花费50%的时间在这,这还是保守估计。我说的模拟登陆不仅仅只是登陆成功就ok了,还有很多问题需要解决,比如一下几个小问题:
(1)登陆成功以后如何保存cookie,方便下一次发起请求的时候直接放入请求头里面(注意这里是分布式的爬虫,所以cookie存储要考虑分布式的环境)
(2)如何检测cookie的失效时间,以便你重新登录,刷新cookie
(3)发起请求后,对状态码的处理,通过状态码的分析,去检测是不是账号的问题。你比如微博发生302重定向,那很可能就是账号被判为异常,重定向到安全页面,那你是不是需要对302返回码处理,删除老的cookie,采用新的cookie,再次发起请求。
再看第二个问题,验证码识别:
这个是在登录模块里面,没错。但是这个模块又很有研究价值,所以我单独拿出来说。验证码的识别本质就是图片识别。BAT(百度,阿里,腾讯)都做的有对应的图片识别api,你可以调用,但是次数多的话,需要钱。但是这些都不是最重要的,重要的是不准,下面来看看究竟有多不准。
百度的OCR api:

腾讯的:只有身份证和名片的OCR,识别效果不好,我就不贴了
 阿里的OCR:右边的SOR4N,2C,X,0是识别结果
阿里的OCR:右边的SOR4N,2C,X,0是识别结果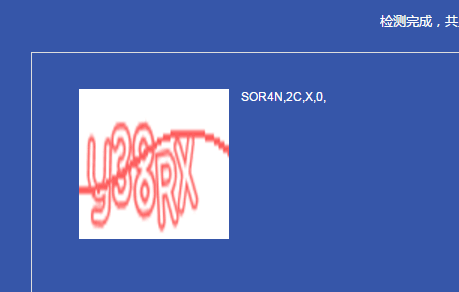
我想说,要是效果做成这样,我也能做。
但是有一家小众的公司,确实做得好,就是聚合数据,他们的api也是收费的,但是做得挺好,但是他家的在线测试提交不成功,只能用代码调用,或者用Postman去测试。我测试了10次,9次是正确的,但是需要花钱,注册免费送50次调用。
当然你是搞图像的,很简单,去看论文,把论文里面的方法实现,估计应该不错。我不是这行的,我就不去做了,我是用人工输入验证码的。
第三个问题:分布式爬取数据
这里面最主要的就是URL去重,防止爬虫爬重复的东西,scrapy是采用redis来去重的,就是统一管理URL,给每一个URL产生一个指纹,当有新的URL时,判断指纹有没有出现过,出现过就不放如URL,然后没出现的都放入待爬队列里面。
这个解决方案有问题,因为内存是有限的,生产环境是不能用的(想想谷歌10000亿的URL,就算能存起来,查重也是一个很耗时的问题),然后就得像更好的方法,有的采用布隆过滤器来解决,但是这个方法也还是无法完全解决这个问题。所以就去查看论文,在文章Design and Implementation of a High-Performance Distributed Web Crawler里面采用内存和磁盘的方式去解决,主要思想是内存里面维护一颗红黑树,然后把红黑树不断和磁盘合并,达到去重的效果。
但是我感觉也不是最好的方法,虽然我不知道最好的方法是什么...
第四个问题:数据存储
这个里面主要是分布式爬去的时候如何把微博数据存起来,一般都是用mongodb,但是单台mongodb存储能力有限,所以就需要做mongodb的集群,这里就是纯工程的问题,大家可以上网查。不过mongodb集群存储还是蛮有意思的,工程技术能力要求高。
第五个问题:网页更新
这个应该一直都是学术界研究的问题,google爬下那么多网页,如何决定那些网页需要刷新,毕竟有的网页是经常改动的,有的又是从来都不变的。同样上一篇文章Design and Implementation of a High-Performance Distributed Web Crawle里面也说了一些方法,但也不是很完美的解决方案,还是需要大家去探索。
第六个问题:基于关键字的微博爬取
我们爬网页的时候,很多时候我们是有意图的,比如我就只想爬“关于网络爬虫”的网页,其他的网页我们都不要,那怎么办?这个也是学术界在研究的问题,如何设计爬取特定主题网页的爬虫,毕竟网页实在太多了,我们只想去爬对我们有意义的网页。当然这里面就会涉及很多概念背景图,语义分析的知识,这个时候离散数学就会大展身手了。
总之,上面的每一个问题,随便挑一个,楼主都有很多事去做,而且技术含量不低.....
【参考文章】
Design and implementation of a high-performance ..._百度学术
--------------2015.11.08----------------------
评论区有人很不赞同我的这个答案,然后就开始argue 我,这个可能怪我写的不够仔细,还是让他们觉得写爬虫是一种很low的东西,甚至
我一条一条来回答。
第一个,模拟登录,除非是针对某个特定网站,其余通用的解决方法其实就是大量代理 IP 轮着用,非常「没有技术含量」。我就想问一下,在没有大量的IP地址可用的情况下,你有去研究过反向代理IP地址复用的解决方案吗?
第二个,验证码,你所谓的「有一家小众的公司,确实做得好」,后面对接的就是人工打码,它就是「最没有技术含量」的方式实现的。是的,我刚开始是人工输入,但是我后面去研究了验证码的识别方案了。现今的验证码破解步骤主要有一下几部:预处理阶段、特征提取阶段、验证码识别阶段和结果修正。预处理阶段包含的技术又有:图像灰度化,背景去噪,二值化,去干扰线等。特征的提取有平均切分、横竖投影切分。最重要的识别阶段,方法有模板匹配法,神经网络法,统计决策法,模糊判断,SVM,隐马尔可夫等等,这里面数学要求还是极高的
。第三个,URL去重,生产环境的解决方法就是全存内存,查重都是 O(1) 的,不是一个「很耗时的问题」。内存多便宜啊,全存内存有什么关系啊。我想了一下O(1)复杂度的查找算法,还是没有一个能够解决当前问题的,还劳烦
指教。第四个,你放在 google 的语境下是个问题,但是对于其他人不一定。对于大部分环境来说,MySQL 就够用了,就算是 mongodb,那也是工业上已有的实现,搭起来也就是一个「世界上最无聊最没有技术含量最累的」非「编程活动」。非「编程活动」这个标签我赞同,但是「世界上最无聊最没有技术含量最累的」,我就只能呵呵了,一个数据库集群不是搭建起来就好了,还有数据故障恢复,性能优化,这些尼?这些都没有技术含量...
第五个,同样,你放在 google 语境下是个问题,但是对于大部分人来说,哪些页面是经常更新的,是「最无聊最没有技术含量最累的」 heuristic 规则搞得定的。大哥,你简直就是NB啊,学术界至今没有很好解决的问题,你用heuristic 规则搞得定,还请指教?难道高手真的在人间,还是那帮教授太蠢了?
第六个,这个反过来了,「只想爬“关于网络爬虫”的网页」对于 google 来说反而不是一个问题。如果一个特定关键词有足够多的需求,那么它一定会有足够的链入链接,它是不会漏掉的。反过来,对于其他人,这又是一个「最无聊最没有技术含量最累的」 heuristic 规则搞得定的问题。对于google不是问题,google现在的搜索都是基于爬到的网页,正反向的索引加上pagerank来做的,请参考《The Anatomy of a Large-Scale Hypertextual Web Search Engine》。如果有一天给定特定主题,爬虫就能爬到相关的网页,那么google还有必要去爬网页,存储,建索引吗?解决这个问题,就意味着Google不在需要开很多机器去爬网页,不用买很多硬盘存储,这个能节约多大的费用?至少光电费都节省不少吧。
其实,你上面说的都没有什么问题,按照你说的,问题都能解决,但是这些解决方法都不够好,我们需要去想更好的方法,否则大家都停留在这个位置,就永远不会进步了。而且楼主需要的是写牛逼代码,而不是为了爬网页而爬网页,我们回答是给他一个学习的方向,而不是告诉他很low,这些都不用学,没有意义。
很多在这个答案下说爬虫很low的人都是为了爬网页而爬网页的人,你们压根就没有去思考这个后面所蕴藏的问题。