1.1.hive的基本思想
HIve是基于Hadoop的一个数据仓库的工具(离线,分析数据),可以将结构化的数据文件映射为一张数据库表,并提供类sql查询功能。
1.2.为什么使用Hive
直接使用hadoop所面临的问题:1.人员学习成本高 2.项目周期要求太短 3.MapReduce复杂查询开发难度太大
为什么要使用hive:1.操作接口采用类sql语法,提供快速开发的能力 2.避免去写MapReduce,减少开发人员的学习成本,功能扩展很方便
1.3.hive特点
- 可扩展
Hive可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 容错
良好的容错性,节点出现问题SQL仍可完成执行。
1.2 hive的基本架构
1.2 hive的基本架构
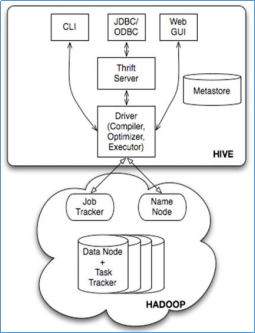
Jobtracker是hadoop1.x中的组件,它的功能相当于:
2.x:Resourcemanager+MRAppMaster
Jobtracker属于主节点
TaskTracker 相当于:
Nodemanager + yarnchild
TaskTracker属于从节点
1.3.hive的安装
安装:
1.将hive的安装包(apache-hive-1.2.2-bin.tar)放到root下,解压到/usr/local/路径下 tar -zxvf .....-C /usr/local/
2.mysql的驱动jar包mysql-connector-jar(放在hive的lib下)
3.进行hive的元数据配置
vi conf/hive-sit.xml(连接驱动/jdbcmysql的账号和密码,hive-sit,xml是不存在)
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> <description>password to use against metastore database</description> </property> </configuration>
4.配置环境变量 vi /etc/profile
5.source /etc/profile(修改环境变量,必须进行这一步)
6.开启hadoop集群 start-all.sh (hive的底层依赖于hive)
7.开启mysql service mysqld start
8.启动hive 启动命令: hive
(注意更新时间:安装 yum -y install ntpdate 更新时间:ntpdate pool.ntp.org 查看时间:date)
错误1:
说明:处在安全状态(原因栓数据还没有启动成功)
纠错:强制离开安全模式状态命令:hadoop dfsadmin -safemode leave
1.4.hive的使用方式
1.查看数据库:show database;
2.创建数据库:create database db_myde;
3.创建表(string不区分大小写) 首先使用数据库 use db_myde; create table stu1(id string,name string,age int,address string) row format delimited fields terminated by ',';
这样就指定了,我们的表数据文件中的字段分割符为“,”。
4.查看表 show tables;
5.删除表 drop table 表名;
6.内部表和外部表
内部表(MANAGED_TABLE):表目录按照hive的规范来部署,位于hive的仓库目录/user/hive/warehouse中
外部表(EXTERNAL_TABLE):表目录由建表用户自己指定
create external table t_access(ip string,url string,access_time string)
row format delimited
fields terminated by ','
location '/access/log';
自己指定路径:location '/access/log'
外部表和内部表的特性差别:
1、内部表的目录在hive的仓库目录中 VS 外部表的目录由用户指定
2、drop一个内部表时:hive会清除相关元数据,并删除表数据目录(数据不再hdfs上了)
3、drop一个外部表时:hive只会清除相关元数据;(数据还在hdfs上,在创建时,可以自己指定路径)
一个hive的数据仓库,最底层的表,一定是来自于外部系统,为了不影响外部系统的工作逻辑,在hive中可建external表来映射这些外部系统产生的数据目录;
然后,后续的etl操作,产生的各种中间表建议用managed_table(内部表)
7.分区表
分区表的实质是:在表目录中为数据文件创建分区子目录,以便于在查询时,MR程序可以针对分区子目录中的数据进行处理,缩减读取数据的范围。
比如,网站每天产生的浏览记录,浏览记录应该建一个表来存放,但是,有时候,我们可能只需要对某一天的浏览记录进行分析
这时,就可以将这个表建为分区表,每天的数据导入其中的一个分区;
当然,每日的分区目录,应该有一个目录名(分区字段)
实例:创建分区表(dt string 值得是时间)
create table access(ip string,url String,access_time string) partition by (dt string)
row format delimited
fields terminated by ',';
导入一个分区字段:
load date local inpath '/root/students1.txt' into table access partition(dt='20190529');
查询分区:
select * from access where dt='20190529';
select count(*) from access;
8.导入导出数据(将hive表中的数据导出到指定路径的文件)
1.将hive表中的数据导入到hdfs的文件
insert overwrite directory '/root/kgc/' row format delimited fields terminated by ',' select * from access;
2.将hive表中的数据导入到本地磁盘文件
insert overwrite directory '/root/kgc/' row format delimited fields terminated by ',';
1.5.数据类型
1.数字类型
tinyint(1字节整数)
smallint(2字节整数)
int/integer(4字节整数)
bigint(8字节整数)
float(4字节浮点数)
double(8字节双精度浮点数)
2.时间类型
timestamp(时间戳)(包含年月日时分秒的一种包装)
date(日期)(只包含年月日)
3.字符串类型
string
varchar(字符串1-65355长度,超长截断)
char(字符串,最大长度255)
4.其他类型
boolean(布尔类型):true false
binary(二进制)
5.复合类型
array数组类型
array<data_type>
示例:
假如有如下数据需要用hive的表去映射:
|
流浪地球,吴京:吴孟达:李光洁,2019-02-06 三生三世十里桃花,杨幂:迪丽热巴:高伟光,2017-08-20 都挺好,姚晨:倪大伟:郭京飞,2019-03-01 |
设想:如果主演信息用一个数组来映射比较方便
建表:create table t_movie(name string,cat array<string>,first_date date) row format ddelimited fields terminated by ',' collection items terminated by ':';
导入数据:load data local inpath '/root/movie.txt' into table t_movie;
查询数据:select * from t_movie;
select name,cat[0] from t_movie;
select name,size(cat) from t_movie;
map类型
map<string,string>
示例:
假如有以下数据:
|
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoli,28 2,lisi,father:mayun#mother:huangyi#brother:mahuateng,22 3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29 4,mayun,father:mayongzhen#mother:angelababy,26 |
建表:
create table t_person(id int,name string,family_members map<string,string>,age int)
row format delimited fields terminater by ','
collection items terminated by '#'
map keys terminated by ':';
导入数据:
load data inpath '/root/person.txt' into table t_person;
查询:
select * from t_person;
取map字段指定key值
select id,name,familty_members['father'] as father from t_person;
取map字段所有的key
select id,name,map_keys(family_members) from t_person;
取map字段所有的values
select id,name,key_values(family_members) from t_person;
select id,name,key_values(family_members)[0] from t_person;
综合:查询有brother的信息
select id,name,brother from(select id,name,family_members['brother'] from t_person)
where brother is not null;
struct类型
假如有如下数据:
|
1,zhangsan,18:male:beijing 2,lisi,28:female:shanghai 3,wangwu,38:male:henan 4,zhaoliu,30:female:shanxi |
其中的用户信息包含:年龄:整数,性别:字符串,地址:字符串
设想用一个字段来描述整个用户信息,可以采用struct
建表:
create table t_struct(id int,name string,info struct<age:int,sex:string,addr:string>) row format fields terminated by ',' collection items terminated by ':';
查询:
select * from t_struct;
select id,name,info.age from t_struct;
1.6.函数
1.表生成函数
行转列函数
假如有以下数据:
|
1,zhangsan,化学:物理:数学:语文 2,lisi,化学:数学:生物:生理:卫生 3,wangwu,化学:语文:英语:体育:生物 4,zhaoliu,数学:物理:化学:英语 |
建表:
create table t_subject(id int,name string,account array<string>) row format delimited fields terminated by ',' collection items terminated by ':';
查询:
表现形式:
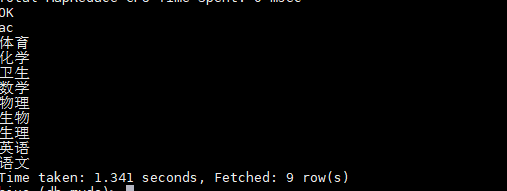
sql:
select distinct tmp.ac from(
select explode(account) as ac from t_subject) as tmp;
表生成函数lateral view