ElasticSearch 系列文章
1 ES 入门之一 安装ElasticSearcha
2 ES 记录之如何创建一个索引映射
3 ElasticSearch 学习记录之Text keyword 两种基本类型区别
4 ES 入门记录之 match和term查询的区别
5 ElasticSearch 学习记录之ES几种常见的聚合操作
6 ElasticSearch 学习记录之父子结构的查询
7 ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
8 ElasticSearch 学习记录之ES高亮搜索
9 ElasticSearch 学习记录之ES短语匹配基本用法
10 ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
11 ElasticSearch 学习记录之集群分片内部原理
12 ElasticSearch 学习记录之ES如何操作Lucene段
13 ElasticSearch 学习记录之如任何设计可扩容的索引结构
14 ElasticSearch之 控制相关度原理讲解
分布式文档存储
ES分布式特性
- 屏蔽了分布式系统的复杂性
- 集群内的原理
-
- 垂直扩容和水平扩容
- 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中
ES集群特点
- 一个集群拥有相同的cluster.name 配置的节点组成, 它们共同承担数据和负载的压力
- 主节点负责管理集群的变更例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作
- 集群健康
1.GET /_cluster/health返回值中的status 是我们关注的
- green 主副分片均正常
- yellow 主都正常,不是所有的副都正常
- red 所有主分片都不正常
- 分片的特点
-
- Elasticsearch 是利用分片将数据分发到集群内各处
- 分片是数据的容器,文档保存在分片内
- 分片又被分配到集群内的各个节点里
- 当集群规模变动,ES会自动在各个节点中迁移分片。使得数据任然均匀分布在集群中
- 副分片是主分片的一个拷贝,作为硬件故障时的备份。并提供返回文档读操作
- 在创建索引时,确定主分片数,但是副分片可以在后面进行更改
在更新一个文档时的ES内部操作
- Elasticsearch 已将旧文档标记为已删除,并增加一个全新的文档。
- 尽管你不能再对旧版本的文档进行访问,但它并不会立即消失。
- 当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档
ES如何处理冲突
- 使用乐观并发控制
- 利用 _version 号来确保 应用中相互冲突的变更不会导致数据丢失
- 通过外部系统使用版本控制
文档的部分更新
- 文档不能被修改,只能被替换
如何路由一个文档到一个分片中
- 当索引一个文档时,我们怎么知道这个文档在什么位置
- 使用下面的这个路由选择公式
1.shard = hash(routing) % number_of_primary_shards下面将对这个公式每个字段进行分析-
shard 哪个分片, 也就是分片idrouting 一个可变值,默认是文档的idhash 一个哈希函数,对rounting字段进行哈希计算生成一个数字number_of_primary_shards 主分片的数量,routing字段经过hash函数计算之后的值,将对 主分片的数量也就是 number_of_primary_shards 进行取与,之后得到的shard就是我们文档所在的分片的位置
主分片和副分片如何交互
假设一个集群由三个节点组成。有一个索引,这个索引有两个主分片,每个主分片有两个副分片,相同的分片的副本不会放在同一个节点上。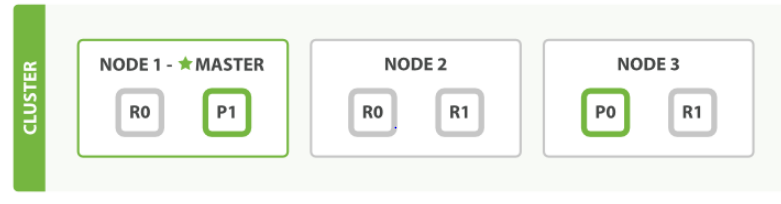
请求发送到集群任意节点,每个节点都有能力处理请求。每个节点都知道集群中任一文档的位置,所以可以将请求转发到需求节点上。
新建、索引和删除单个文档 时的流程
-

先向 node 1 来一个请求这个请求可能是发送新建,索引或者删除文档等。node 1 节点根据文档的_id 确定文档属于分片0, 请求被转发到node3 节点node 3 在主分片执行了请求,如果主分片执行成功了,它将请求转发给node1 和node 2 节点。当所有的副分片都执行成功,node 3 将协调节点报告成功,并向客户端报告完成
-
consistency 参数的值可以设为 one (只要主分片状态 ok 就允许执行写操作),all(必须要主分片和所有副本分片的状态没问题才允许执行_写_操作), 或quorum 。默认值为 quorum , 即大多数的分片副本状态没问题就允许执行写操作 - 在执行一个写操作时,主分片都需要必须有一个规定数量的(quorum),也就是在大多数主副分片处于活跃状态。这样是防止在网络分区故障是执行写操作会导致数据不一致
1.quorum = int( (primary + number_of_replicas) / 2 ) + 1取回一个文档
可以从主分片或者任意副本分片检索文档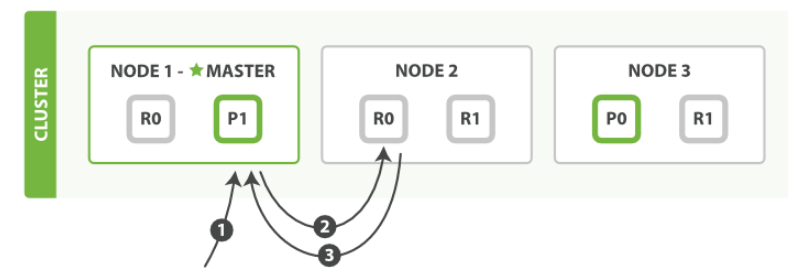
某个请求向node 1 发送获取请求 节点使用节点使用节点文档_ID来确定文档属于分片0, 分片0 的副本分片存在于所有的三个节点上,在这种情况下,他将请求转发到node 2node 2 将文档返回给node 1 ,然后将文档返回给客户端
在每次处理读取请求时,协调结点在每次请求的时候都会轮训所有的副本片来达到负载均衡
局部更新文档

部分更新一个文档的步骤客户端向node1 发送一个请求它将请求转发到主分片这个文档所在的Node 3node 3从主分片检索文档,修改_Source json ,并且尝试重新索引主分片的文档。如果文档被另一个进程修改,他会重复步骤3 知道超过retry_on_conflict 次后放弃node 3 成功更新文档,它将新版本的文档并行转发到node 1 和node 2 的副本分片,重新建立索引。所有副本分片都返回成功,node 3 向协调节点也返回成功,协调节点向客户端返回成功update 操作也支持 新建索引的时的那些参数 routing 、 replication 、 consistency 和 timeout
多文档模式
mget 和 bulk API 的 模式类似于单文档模式。 协调节点知道每个文档的位置,将多个文档分解成每个文档的的多文档请求,并且将这些请求并行的转发到每个参与节点中 。使用 mget 取回多个文档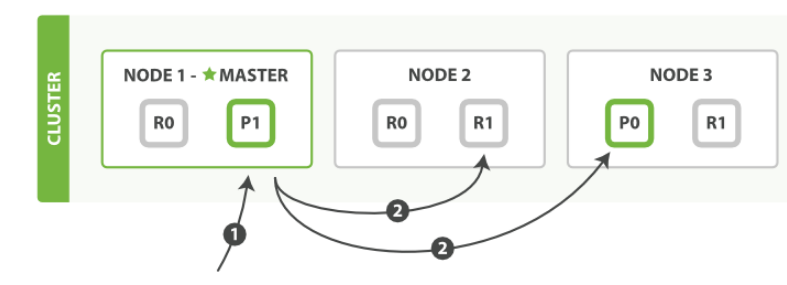
客户端向node 1 发送一个mget请求node 1 向每个分片构建多文档请求,并行的转发这些请求到托管在每个所需的主分盘或者副分片的节点上一旦收到所有的额回复,node 1 构建响应并将其返回给客户端
使用 bulk 修改多个文档
一个bulk请求请求到node 1node 1 为每个节点创建一个批量请求,并将这些请求并行转发到每个包含主分片的节点主分片一个接一个按顺序执行每个操作。当每个操作成功时,主分片并行转发新文档(或删除)到副本分片,然后执行下一个操作。 一旦所有的副本分片报告所有操作成功,该节点将向协调节点报告成功,协调节点将这些响应收集整理并返回给客户端
搜索—–最基本的工具
ElastcSearch 的三个基本概念映射 Mapping 描述数据在每个字段是如何存储的分析 Analysis 全文如何处理使之可以被搜索到Query DSL ES中强大灵活的查询语言
空搜索-
GET /_search 没有指定任何查询的搜索包括没有指定索引
1.**查询获取之后****查询获取之后**2. 3. { 4. "took": 8, //请求耗费多少毫秒 5. "timed_out": false,//是否超时 6. "_shards": {//在查询中参与分片的总数,成功多少,失败多少 7. "total": 42,//总分片数 8. "successful": 42,//成功数 9. "skipped": 0,//跳过数 10. "failed": 0//失败数 11. }, 12. "hits": {//hits指返回的结果集 13. "total": 6184,//总文档数量 14. "max_score": 1, 15. "hits": [ 16. { 17. "_index": ".kibana", //索引名称 18. "_type": "config",//索引type 19. "_id": "5.6.3",//文档在这个索引下的id 20. "_score": 1,//索引得分,是查询后的计算得来的 21. "_source": { 22. "buildNum": 15554 23. } 24. },
xxxxxxxxxxxxxxxxxx