[论文阅读笔记] Structural Deep Network Embedding
本文结构
- 解决问题
- 主要贡献
- 算法原理
- 参考文献
(1) 解决问题
现有的表示学习方法大多采用浅层模型,这可能不能捕获具有高度非线性的网络结构,导致学习到一个局部最优的节点向量表示。
(2) 主要贡献
Contribution: 提出一个半监督的深度模型SDNE,包含多个非线性层,同时优化一阶和二阶相似度的目标函数来保留原始网络的局部和全局网络结构,因此可能能够捕获高度非线性的网络结构。
(3) 算法原理
简单来说:SDNE利用一阶和二阶相似度来保留网络结构。 二阶相似度作为无监督部分被用来捕获全局结构。一阶相似度作为监督部分被用来捕获局部结构。通过利用半监督的深层模型联合优化以上两个目标可以保留局部和全局网络结构。
详细来说:SDNE的总体框架如下图所示(图中的Local structure preserved cost和Global structure preserved cost应该是标反了!!!):
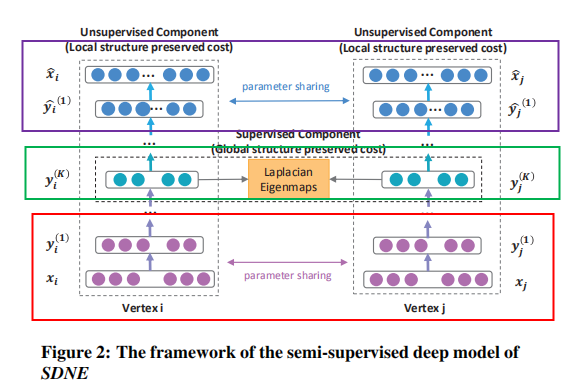
SDNE可以看成一个自编码器框架,上图中红框框部分可以看成编码器,中间绿色框框部分为编码器的输出,为节点的对应的嵌入向量,紫色框框部分为对应的解码器部分。了解了SDNE的框架组成部分之后,我们来看看各个部分是怎么设计的。
SDNE的无监督部分由深层自编码器组成。其中,编码器由多个非线性层组成,可以映射输入数据到表示空间。解码器也由多个非线性层组成。即,给定输入x,编码器每一隐藏层的输出如下:

解码器重构输入xi为x~。因此
自编码器的目标就是最小化以下输出x~与原始输入x的重构损失,损失函数如下:
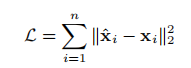
如果使用邻接矩阵作为自编码器的输入x,即每一行代表一个节点,因为邻接矩阵反应的是对应节点的邻居结构信息,这使得重构构成会使得有相似邻居结构的节点有相似的向量表示(即该无监督组件(自编码器)保留了网络中的二阶相似度信息)。但是,如果直接使用邻接矩阵S作为传统自编码器的输入,则模型更容易重构邻接矩阵中的零元素(因为网络的稀疏性,邻接矩阵中的零元素数目远远大于一的数目)。然而我们更关注的是邻接矩阵中代表邻居的1元素,为了解决这个问题,SDNE对非零元素的重构误差增加更多惩罚(即加了一个权重项bi,对非零元素的重构误差赋予更大的惩罚项)。新的目标函数(保留二阶相似度信息)如下:

一个圈圈一个点的符号代表哈达玛积(矩阵对应位相乘),如果邻接矩阵Sij>0,那么赋予相应的bij=1,否则bij=β>1,即更大的惩罚权重。以上便是SDNE的无监督模块,其通过二阶相似度试图保留全局网络结构。
然而,局部网络结构的保留也是必要的。以下介绍SDNE的用来保留一阶相似度的监督模块。 监督模块的一阶相似度的损失函数如下,这保证在原始网络中有连边的节点在嵌入空间中也比较相近(yi是对应的节点嵌入向量,即编码器的输出)。
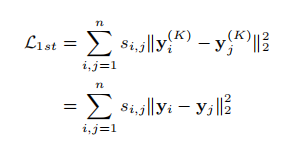
SDNE总的目标函数如下(包含一阶相似度和二阶相似度):
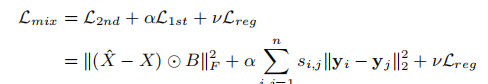
Lreg为L2正则项,惩罚神经网络的复杂性,防止模型过拟合,如下所示:

以上,SDNE模型就介绍完啦,目标函数优化部分请自行查看原始论文。
(4) 参考文献
Wang D, Cui P, Zhu W. Structural deep network embedding[C]//Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining. 2016: 1225-1234.