一、流与缓存区
1.1 如何理解流?
流是一种连接,一种管道,它建立了与物理文件或网络相关联的机制,方便读写文件或者网络。当然还有其它类型的流。
1.2 流的操作
读取:将数据从流传输到缓存区,缓冲区就是内存中的一块区域,代码中常用byte数组。
写入:将数据从数据源传输到流中。
流用完后需要释放资源,因为文件或者网络连接都属于非托管资源,需要手动释放。
二、客户端和服务器的通信
http通信,通过接口请求、响应。
三、何为断点续传
从哪跌倒,就从哪爬起,顾名思义,从上次断开的位置接着传输。
四、为什么需要断点续传
优点:针对大文件且网络不太稳定的情况,断点续传能节省带宽。
缺点:增加额外的通信
五、如何进行断点续传
断点续传的解决方案,如下图所示:
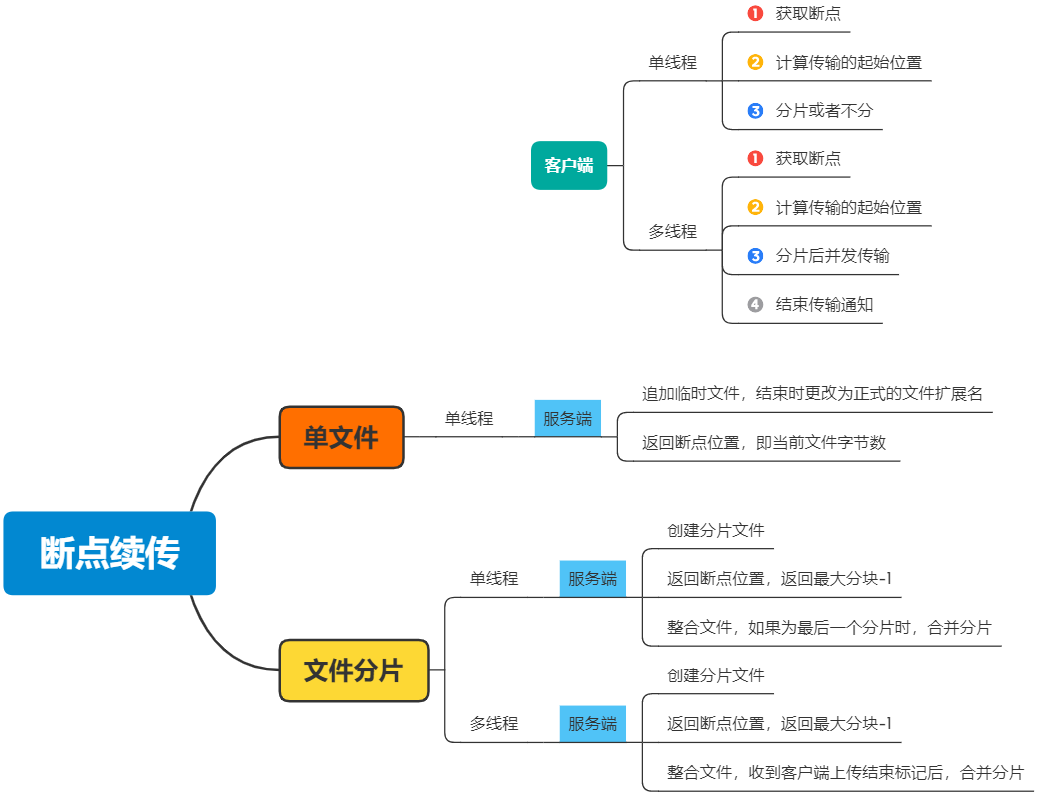
上图中,主要描述了客户端和服务器通信的情况
客户端:
1、需要知道上次断点位置
2、计算当前开始传输的位置
3、传输文件
如何传输文件,比如分片还是不分片,是多线程还是不用多线程,这些都需要设计与考虑。如果用了多线程,就会增加问题的复杂度。当然用好了,好处也很多。
服务端:
创建文件的服务
提供断点位置的服务
如果是分片传输,还要提供合并分片的服务