https://zhuanlan.zhihu.com/p/46362124
简介
上一篇文章中,介绍了BlueStore的诞生背景、逻辑架构以及设计思想,提到了在BlueStore中元数据都是存放在RocksDB中的,BlueStore又实现了一个轻量级的文件系统BlueFS供RocksDB读写数据。
在本篇文章中将会描述BlueFS的设计缘由和设计原理。
为什么要BlueFS?
BlueStore使用RocksDB来管理元数据,但是RocksDB本身并不支持对裸设备的操作,文件的读写必须实现rocksdb::EnvWrapper接口,RocksDB默认实现有POSIX文件系统的读写接口,那么直接为BlueStore格式化一个POSIX文件系统供RocksDB使用就好了,为什么还要单独实现BlueFS呢?但是POSIX文件系统作为通用的文件系统,其很多功能对于RocksDB来说并不是必须的,为了进一步提升RocksDB的性能,需要对文件系统的功能进行裁剪,而更彻底的办法就是考虑RocksDB的场景量身定制一套本地文件系统,BlueFS也就应运而生。BlueFS相较于POSIX文件系统具有以下几种优势。
- 简单结构
首先RocksDB的文件层次结构比较简单,主要包含sst文件,CURRENT文件,manifest文件,log文件,LOG文件和LOCK文件,文件数量较少且目录层次单一,不需要复杂的目录管理结构,可简单地用map映射结构进行管理,BlueFS通过一个dir_map建立目录名到目录结构的映射,BlueFS只有一级目录,不存在多级目录,例如目录/a 和 /a/b为同一级目录;另外目录结构中有一个file_map,为文件名到文件结构的映射,表示该目录包含的文件。
此外RocksDB对文件系统的使用场景也比较简单,对于写操作只需要追加写,那么可以针对这种使用场景,每次分配物理空前时进行提前预分配,一方面减少空间分配的次数,另一方面做到较好的空间连续性;另外由于RocksDB的文件数量较少,可以将文件的元数据全部加载到内存,减少读放大,从而提高读取性能。
- 多设备支持
RocksDB在将数据写入到.log文件中即可视为写入成功,.log文件的写入处在IO关键路径当中且IO一般较小,对延时要求较高;而.sst文件则是由后台线程进行读写,不处于关键路径当中,在compaction的时候会有大量的读写操作,对throughput要求较高。因此可以使用性能较好的设备(例如NVMe SSD)存放.log文件,而使用一般的SSD存放.sst文件。但是传统的POSIX文件系统不能同时支持多设备类型,而BlueFS将存储空间划分为三层:慢速(Slow)空间、高速(DB)空间、超高速(WAL)空间,不同空间可使用不同设备类型,.log和BlueFS本身的journal优先用WAL空间,.sst优先用DB空间,空间不足或空间不存在时可自动降级到下一层空间,例如当WAL空间不存在或者空间不足时,.log文件会自动选择DB空间,如果DB空间不存在或者空间不足时就会降至Slow空间。
通过这种特性可以对成本和性能要求进行一个评估,选择不同的存储设备存放不同的数据,配置比较灵活。
- 新设备技术支持
一直以来,存储设备的速度都远低于计算机系统的其他组件,比如 RAM 和 CPU。 这意味着操作系统和 CPU 需借助中断才能与磁盘进行交互:
- 向操作系统提出从磁盘读取数据的请求。
- 驱动程序处理请求,并与硬件通信。
- 磁盘片开始运转。
- 针在磁盘片内移动,开始读取数据。
- 数据被读取并拷贝至缓冲区。
- 生成中断,通知 CPU 数据已就绪。
- 最后从缓冲区读取数据。
这种中断模式会产生开销;但它的延迟一直远低于基于磁盘的存储设备,因此不失为一种有效方式。 随着固态盘 (SSD) 等全新存储设备以及3D Xpoint 存储等下一代存储技术的推出,使存储速度远高于磁盘,并将瓶颈从硬件(比如磁盘)移回至了软件(比如中断 + 内核),如下图所示:
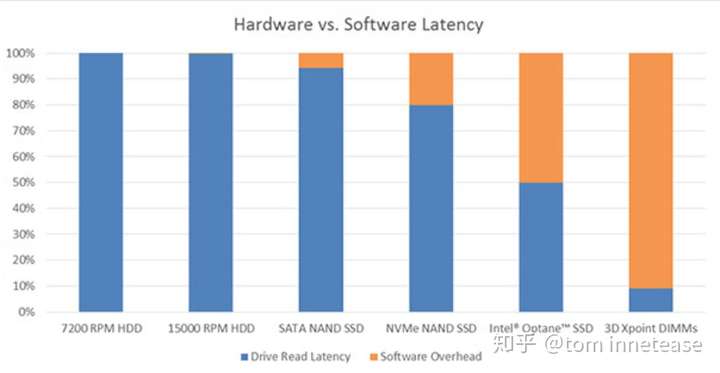
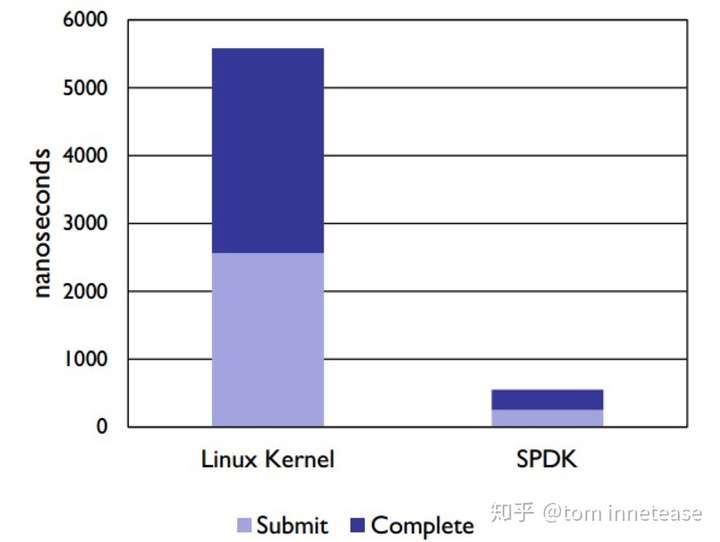
SPDK 提供运行在用户空间 NVMe 驱动程序 ,读写数据时,用户空间 NVMe 驱动程序轮询存储设备,因此不再需要使用中断。 此外更重要的是,NVMe 驱动程序在用户空间中运行,这意味着应用能够直接与 NVMe 设备交互,无需通过内核。 它会产生开销,因为在与内核交互的过程中需要保存和恢复状态。 NVMe 采用无锁设计,不必使用 CPU 周期同步线程之间的数据,而且这种无锁方法还支持并行 IO 命令执行。 以上这些特性都极大减少了软件的开销,相比于使用 Linux 内核的方法,SPDK 用户空间 NVMe 驱动程序可将总体延迟降低 10 倍。
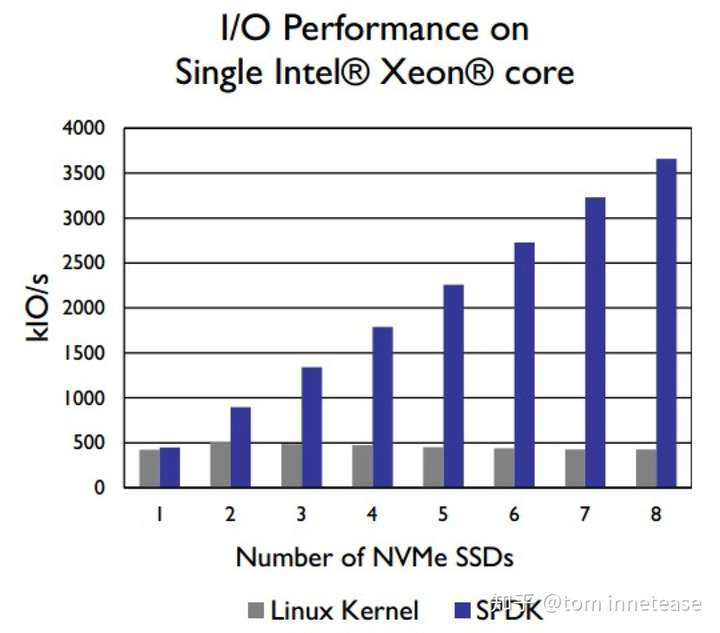
SPDK 能够使 8 块Intel DC P3700系列的 NVMe 固态盘达到饱和,从而通过单个 CPU 内核提供超过 350 万次 IOPS:
但是传统的POSIX文件系统并不支持使用SPDK操作NVMe设备,BlueStore实现了针对NVMe设备的BlockDecive,BlueFS则是基于BlockDecive进行设备管理,因此可以利用SPDK技术,充分发挥NVMe设备的性能。
接口功能
由于BlueFS是为支持RocksDB而实现的文件系统,因此其提供的接口主要针对RocksDB的使用场景。RocksDB中的文件主要包含sst文件,CURRENT文件,manifest文件,log文件,LOG文件和LOCK文件 。
sst文件存储的是落地的数据,CURRENT文件存储的是当前最新的是哪个manifest文件,manifest文件存储的是Version的变化,log文件是rocksdb的write ahead log,就是在写db之前写的数据日志文件,LOG文件是一些日志信息,是供调试用的,LOCK是打开db锁,只允许同时有一个进程打开db ;上述的这些文件基本都是追加写入,只有CURRENT文件需要修改数据内容,RocksDB的实现是通过先将数据写到新的临时文件,然后将新文件重命名为CURRENT文件实现修改,因此BlueFS只需要实现追加写的接口而不需要提供随机写接口。
log文件的读操作一般是顺序的,因此可以通过预读的功能,提前将数据读到缓存,从而加快读取速度;而像sst文件在查询数据的时候需要用到随机读的接口,不需要进行预读,为此BlueFS实现了预读的接口以及随机读接口。
RocksDB对于BlueFS的需求主要在于文件目录的操作,如文件目录的创建删除、目录的遍历、文件重命名、文件追加写、文件的预读接口和随机写接口、数据的sync等;而BlueStore则需要对BlueFS进行初始化、分配块设备空间、查询文件系统信息等,因此也需要提供相应的接口。
Layout
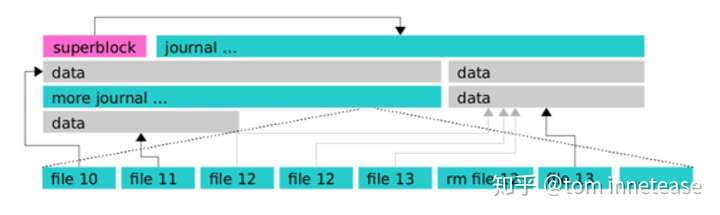
BlueFS的结构比较简单,如下图所示,主要有三部分数据,superblock、journal、以及data。superblock主要存放BlueFS的全局信息以及日志的信息,其位置固定在BlueFS的头部;journal中存放日志记录,一般会预分配一块连续区域,写满以后从剩余空间再进行分配;data为实际的文件数据存放区域,每次写入时从剩余空间分配一块区域。
superblock
superblock记录文件系统的全局信息,也是文件系统加载的入口,其位置固定存放于BlueFS的第二个block(第一个block保留不是很清楚作用),superblock由以下内容组成:
- uuid
表示BlueFS的全局唯一编号,区别于其他BlueFS; - osd_uuid
拥有此BlueFS的OSD的全局唯一编号,识别该BlueFS所属的OSD; - version
BlueFS的版本号,当且仅当日志进行压缩的时候递增,可通过版本号判断BlueFS进行日志压缩的次数; - block_size
BlueFS中的块大小,即每次读写的最小单位 - log_fnode
BlueFS中日志的fnode结构,fnode类似于Linux文件系统中inode的结构,表示一个文件的元数据信息以及数据存放位置。在fnode中,记录有文件的ino编号、文件的大小、文件修改的时间、文件的extent集合(一个extent表示文件的逻辑地址到底层物理空间的映射,这里extent包含物理偏移、区块长度以及设备标识)以及文件已分配空间的大小;写数据时,BlueFS会预分配一段空间,通过文件当前大小和已分配空间大小,可以判断新写入的数据是否需要分配新的存储空间。
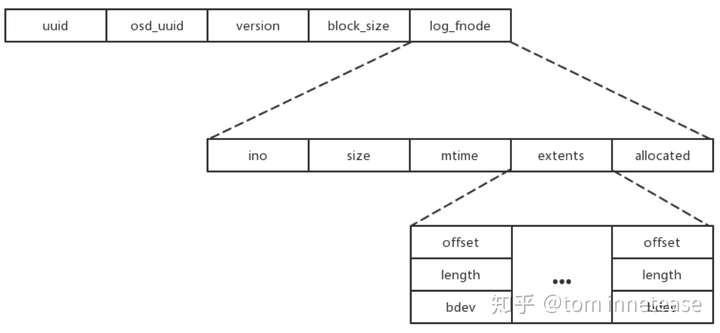
superblock在BlueFS格式化的时候生成,仅当文件系统格式化时或日志压缩完成时持久化到磁盘。BlueFS在初始化时,从superblock中获取日志的fnode,找到日志的位置,然后逐条将日志中的记录回放到内存中,来还原整个BlueFS的元数据(具体流程见下文BlueFS加载)。
journal
BlueFS的元数据不像传统文件系统一样,用特定的数据结构和布局存放,而是通过将所有的操作记录到journal中,然后在加载的时候逐条回放journal中的记录,从而将元数据加载到内存。
journal实际上是一种特殊的文件,其fnode记录在superblock中,而其他文件的fnode作为日志内容记录在journal文件中。
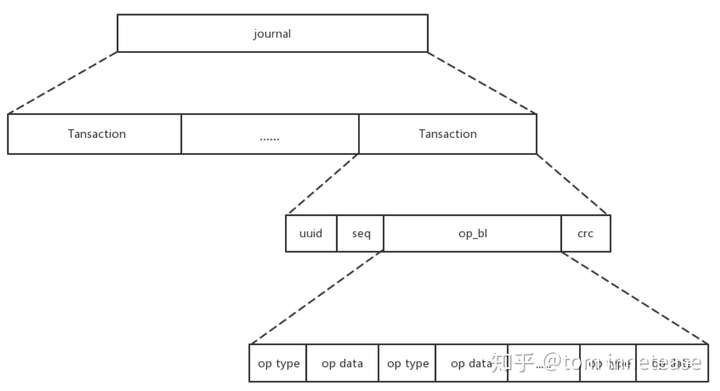
journal是由一条条的事务组成,如下图所示,每条事务包含uuid、seq、op_bl三部分,其作用分别为:
- uuid
表示事务归属的bluefs对应的uuid - seq
事务的全局唯一序列号 - op_bl
编码后的事务条目,可包含多条记录,每条记录由相关的操作码和操作所涉及的相关数据组成。 - crc
在将事务写到日志文件之前,会对op_bl计算crc校验值,该值用于校验该事务的正确性,例如在写日志的中途出现异常掉电的情况,那么下载加载BlueFS时,回放到该条事务时会校验crc,如果上次日志未写完crc校验会失败,从而提示错误。
每条记录中操作类型不同,记录的内容也不同,其操作类型如下表:
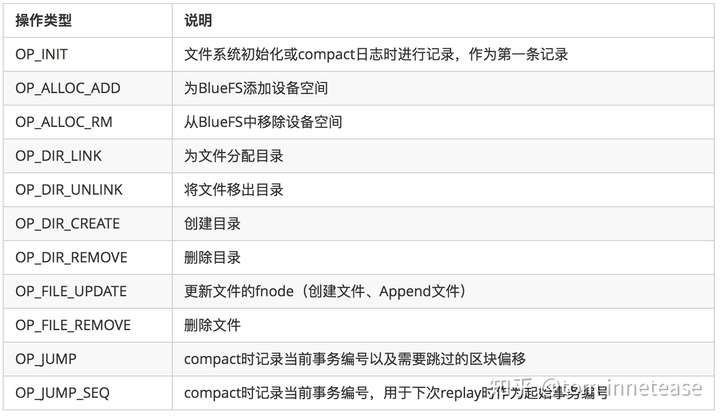
例如操作类型为OP_FILE_UPDATE的日志记录了OP_FILE_UPDATE类型以及更新后的fnode结构,那么对应到上图中的op type就是OP_FILE_UPDATE,op data就是fnode的结构;OP_DIR_LINK操作的op type为OP_DIR_LINK,op data包含目录名、文件名和文件ino编号;回放日志时,首先会解析当前这条记录的操作类型,然后根据操作类型解析后面的数据结构,然后将解析出来的内容放到内存。
我们举个实际的例子来看下日志记录和回放的原理,例如在目录data下新建一个文件1.sst,然后向其中写入数据,将此作为一个事务提交,那么这个事务中最终会按顺序生成三条记录:
1.生成OP_FILE_UPDATE记录,包含记录类型和新生成的fnode结构;
2.生成OP_DIR_LINK记录,包含记录类型、目录名data、文件名1.sst以及文件fnode中的ino编号;
3.生成OP_FILE_UPDATE记录,包含记录类型和新生成的fnode结构;写入操作由于有分配新的空间并且需要更改操作时间,需要更新fnode结构,因此会新生成一条OP_FILE_UPDATE记录。
日志回放会根据记录的顺序逐条解析,在这个例子中首先会将第一条记录中的fnode解析到内存,第二步会在dirmap和filemap中建立文件和目录的映射,第三步会用新的fnode结构替换掉第一步中的fnode。
其它操作同理,只要保证日志顺序与操作顺序一致,最终可以通过日志还原出正确的元数据。
metadata
BlueFS的metadata全部加载在内存当中,主要包含superblock、目录和文件的集合、文件跟目录的映射关系以及文件到物理地址的映射关系;当下次文件系统加载时,将日志中的记录逐条回放到内存,从而还原出metadata。
其中superblock的结构可见上面superblock小节,文件和目录的内存逻辑结构如下图所示,BlueFS的内存中维护一个dir_map,记录BlueFS中的所有目录的目录名到实际目录结构的映射,目录为扁平结构,不存在隶属关系,例如目录/a/b与目录/a在同一级,/a/b即为目录名;每个目录结构下包含一个file_map,记录目录下的所有文件的文件名到实际文件结构的映射,每个文件结构中包含该文件的fnode结构,fnode结构可参考superblock小节中的log_fnode结构。
BlueFS在加载时,会根据日志中记录的内容,在metadata的dir_map和file_map中添加、删除或修改相应的条目;在BlueFS的使用过程中,也会不断变更此映射结构;BlueFS在定位一个具体的文件时会在内存中经过两次查找:第一次通过dir_map找到文件所在的最底层文件夹,第二次通过该文件夹下的file_map找到对应的文件。
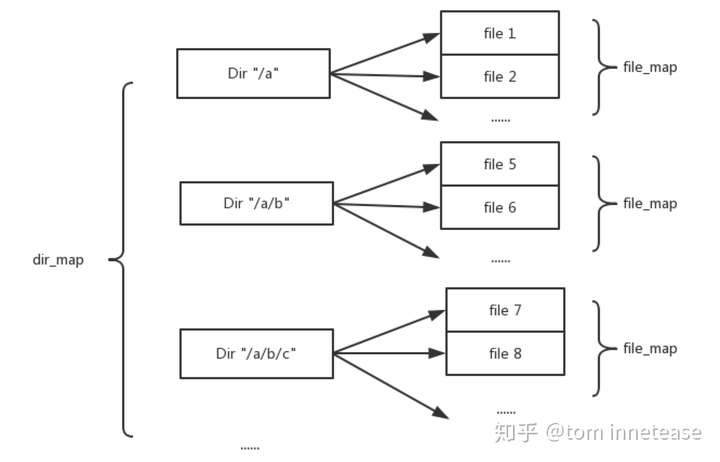
此外内存中还会记录一个dirty_files的列表,记录发生更改,但还未sync的文件集合(因为BlueFS的更新操作只有在调用sync时才会真正更改)。
data
data为实际存放数据的区域,如superblock一节中所描述的fnode结构,每个文件的数据在物理空间上的地址由若干个extents表示;一个extent包含bdev、offset和length三个元素,bdev为设备标识,在前面的章节中我们提到过BlueFS支持三种设备类型,bdev即标识此extent在哪块设备上,offset表示此extent的数据在设备上的物理偏移地址,length表示该块数据的长度。读取文件数据时,可以通过内存中文件的fnode结构中记录的extent找到数据在物理设备上的位置;分配新的空间时,将新分配的extent添加到fnode中。
关键流程
BlueFS加载
- 加载superblock到内存
- 初始化各存储空间的块分配器
BlueFS将存储空间划分为三层:慢速(Slow)空间、高速(DB)空间、超高速(WAL)空间,每种类型空间使用各自的块分配器,块分配器负责该存储空间中空闲空间的分配与回收,块分配器的工作原理我们将在以后的章节中讨论。 - 日志回放
BlueFS元数据都是作为日志持久化在硬盘中,在加载BlueFS时候对日志进行replay还原到内存中,由于日志在持久化时都是根据操作顺序append到日志文件当中,因此在replay的时候只要顺序逐条对日志进行解析就能将BlueFS的当前元数据还原到内存中。
日志回放后会在内存中建立dir_map和file_map,此外块分配器中会添加为不同存储空间分配的磁盘空间。 - 标记已分配空间
日志回放过程中并未将分配给文件的空间从空闲空间中移除,仅当日志回放完成后,所有文件元数据全部加载到内存中,再通过遍历file_map中文件的地址空间映射信息,移除相应的块分配器中的空闲空间,防止已分配空间的重复分配。 - 创建log_writer
log_writer为日志文件的句柄,用于向日志中追加日志项。
日志压缩
如果文件系统一直使用下去,日志将越来越多,日志中有很多操作事实上是可以合并的,例如对同一个文件的多次update,可以直接使用最新的update日志项,删除一个文件后,之前对该文件的操作记录都可以进行回收;如果不做任何处理会造成严重的空间浪费,而且会影响日志回放的性能,因此需要定时对journal进行压缩。
- 压缩原理
由于文件系统的元数据在内存中都有记录,且内存中的元数据都是非重复的,因此可以通过遍历元数据,将元数据重新写到日志文件当中,即可实现日志的压缩。
日志压缩时,会为新的日志分配新的存储空间,将新日志持久化以后再更新superblock中的log_fnode,然后回收旧日志的空间,以此保证日志文件的一致性。 - 压缩策略
BlueFS在刷新日志的时候判断是否要压缩日志,判断依据是日志文件的大小,当日志文件大小超过配置的值时就会触发日志压缩。
由下列两个配置项控制:
bluefs_log_compact_min_ratio // 通过当前日志文件大小和预估的日志文件的大小的比率控制compact,默认为5
bluefs_log_compact_min_size // 通过日志文件大小控制compact,小于此值不做compact。默认为16MB
写数据
RocksDB通过BlueRocksEnv实现的接口与BlueFS交互读写文件,BlueFS只提供append操作,所有文件都是追加写入。RocksDB调用完append以后,数据并未真正落盘,而是先缓存在内存当中,只有调用sync接口时才会真正落盘。实际在用RocksDB时,为了保证BlueStore元数据的可靠性,会将RocksDB设为sync写入,即每次append数据以后都会调用sync保证此次追加成功落盘。
- open file for write
打开文件句柄,如果文件不存在则创建新的文件,如果文件存在则会更新文件fnode中的mtime,在事务log_t中添加更新操作,此时事务记录还不会持久化到日志文件当中。 - append file
将数据追加到文件当中,此时数据缓存在内存当中,并未落盘,也未分配新的空间。 - flush data
判断文件已分配剩余空间(fnode中的 allocated - size)是否足够写入缓存数据,若不够则为文件分配新的空间;如果有新分配空间,将文件标记为dirty加到dirty_files当中,将数据非块大小对齐补零后进行落盘,此时数据已经写到硬盘当中,元数据还未更新,由于BlueFS中的文件都是追加写入,不存在原地覆盖写,不会污染原来的数据。 - flush and sync log
从dirty_files中取到dirty的文件,在事务log_t中添加更新操作(即添加OP_FILE_UPDATE类型的记录),将log_t中的内容flush到log file中,然后移除dirty_files中已更新的文件。
上述步骤中3、4都是sync时的逻辑,写数据一共涉及一次数据的落盘,以及一次log记录的落盘一共两次IO,相比于Ext4文件系统append文件需要六次IO(两次日志的IO、一次inode更改、一次bitmap更改、一次superblock更改以及一次数据落盘),相对来说还是很优秀的。
读数据
由于BlueFS的元数据都在内存中,所以读流程很简单,从内存中获取请求数据的物理位置和物理设备进行读取即可,不存在读放大。
总结
BlueFS是BlueStore针对RocksDB开发的轻量级用户态文件系统,相较于POSIX文件系统结构简单,且支持多种设备,并且可以使用spdk操作NVMe盘,具有更高性能。
通过这篇文章,我们对BlueFS的原理以及在BlueStore中发挥的作用有了一定的了解,在下一篇系列文章中,我们将介绍BlueStore中块分配器Allocator的原理,它是如何进行空间的空间的管理?是否可以减少磁盘碎片?
Notes
作者:网易存储团队工程师 杨耀凯。限于作者水平,难免有理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献中列表注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. Ceph BlueStore BlueFS. http://blog.wjin.org/posts/ceph-bluestore-bluefs.html.
[2]. Ceph BlueFS. https://www.cnblogs.com/chris-cp/p/8067439.html.
[3]. SPDK 助力加速 NVMe 硬盘. https://software.intel.com/zh-cn/articles/accelerating-your-nvme-drives-with-spdk.
[4]. rocksdb理解. http://www.mamicode.com/info-detail-586190.html.
[5]. 谢型果等. Ceph设计原理与实现[M]. 北京:机械工业出版社,2017.12.